60 #Interview #Questions On #MachineLearning https://analyticsindiamag.com/60-in
Data Science 2020. 2. 10. 17:15https://analyticsindiamag.com/60-interview-questions-on-machine-learning/
https://analyticsindiamag.com/60-interview-questions-on-machine-learning/
Machine Learning From Scratch
GitHub, by Erik Linder-Norén : https://github.com/eriklindernoren/ML-From-Scratch
#ArtificialIntelligence #DeepLearning #MachineLearning
Machine Learning From Scratch. Bare bones NumPy implementations of machine learning models and algorithms with a focus on accessibility. Aims to cover everything from linear regression to deep learning.
Python implementations of some of the fundamental Machine Learning models and algorithms from scratch.
The purpose of this project is not to produce as optimized and computationally efficient algorithms as possible but rather to present the inner workings of them in a transparent and accessible way.
$ git clone https://github.com/eriklindernoren/ML-From-Scratch $ cd ML-From-Scratch $ python setup.py install
$ python mlfromscratch/examples/polynomial_regression.py
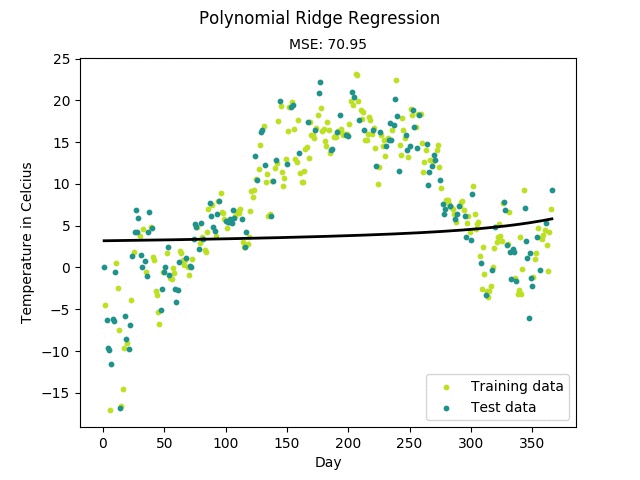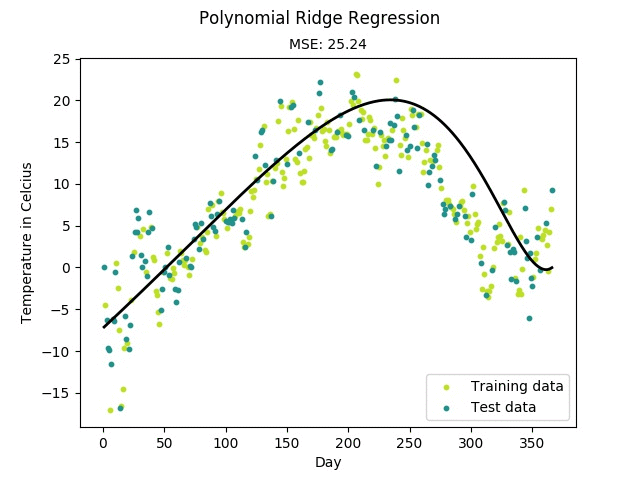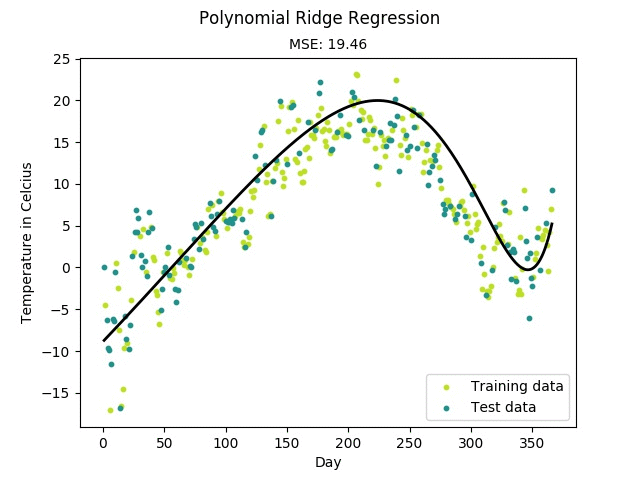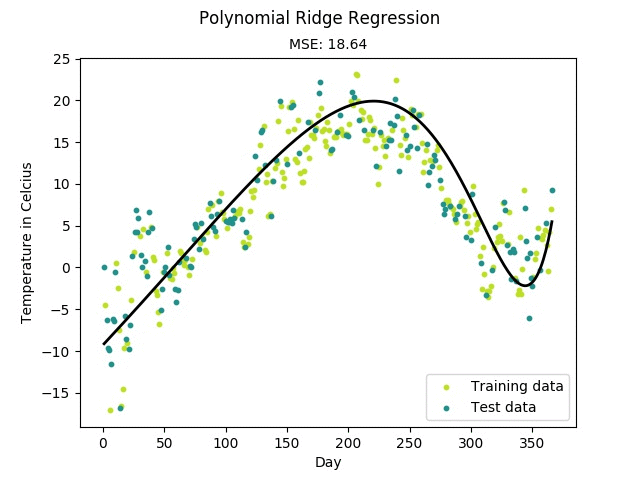
Figure: Training progress of a regularized polynomial regression model fitting
temperature data measured in Linköping, Sweden 2016.
$ python mlfromscratch/examples/convolutional_neural_network.py +---------+ | ConvNet | +---------+ Input Shape: (1, 8, 8) +----------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +----------------------+------------+--------------+ | Conv2D | 160 | (16, 8, 8) | | Activation (ReLU) | 0 | (16, 8, 8) | | Dropout | 0 | (16, 8, 8) | | BatchNormalization | 2048 | (16, 8, 8) | | Conv2D | 4640 | (32, 8, 8) | | Activation (ReLU) | 0 | (32, 8, 8) | | Dropout | 0 | (32, 8, 8) | | BatchNormalization | 4096 | (32, 8, 8) | | Flatten | 0 | (2048,) | | Dense | 524544 | (256,) | | Activation (ReLU) | 0 | (256,) | | Dropout | 0 | (256,) | | BatchNormalization | 512 | (256,) | | Dense | 2570 | (10,) | | Activation (Softmax) | 0 | (10,) | +----------------------+------------+--------------+ Total Parameters: 538570 Training: 100% [------------------------------------------------------------------------] Time: 0:01:55 Accuracy: 0.987465181058
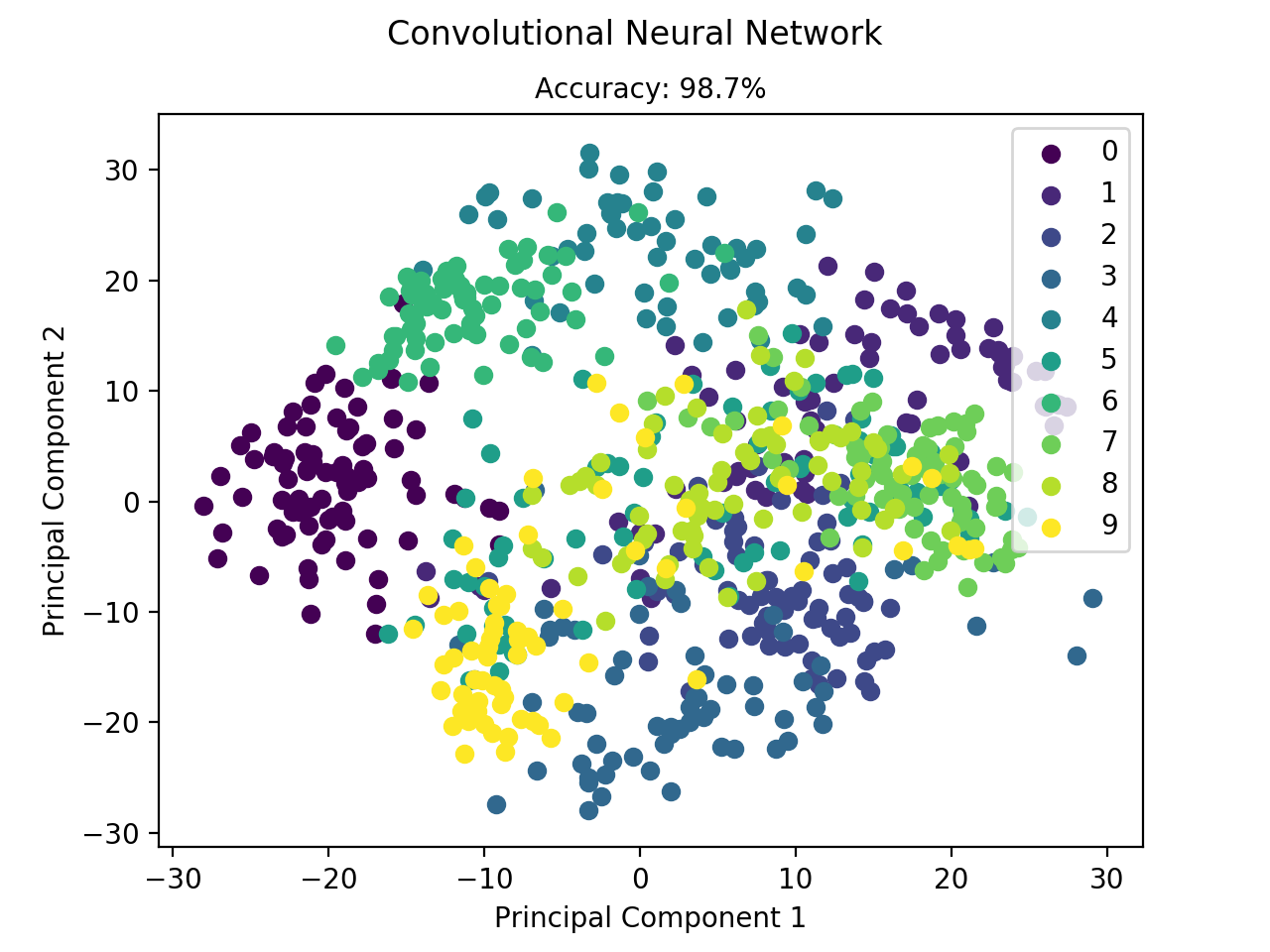
Figure: Classification of the digit dataset using CNN.
$ python mlfromscratch/examples/dbscan.py
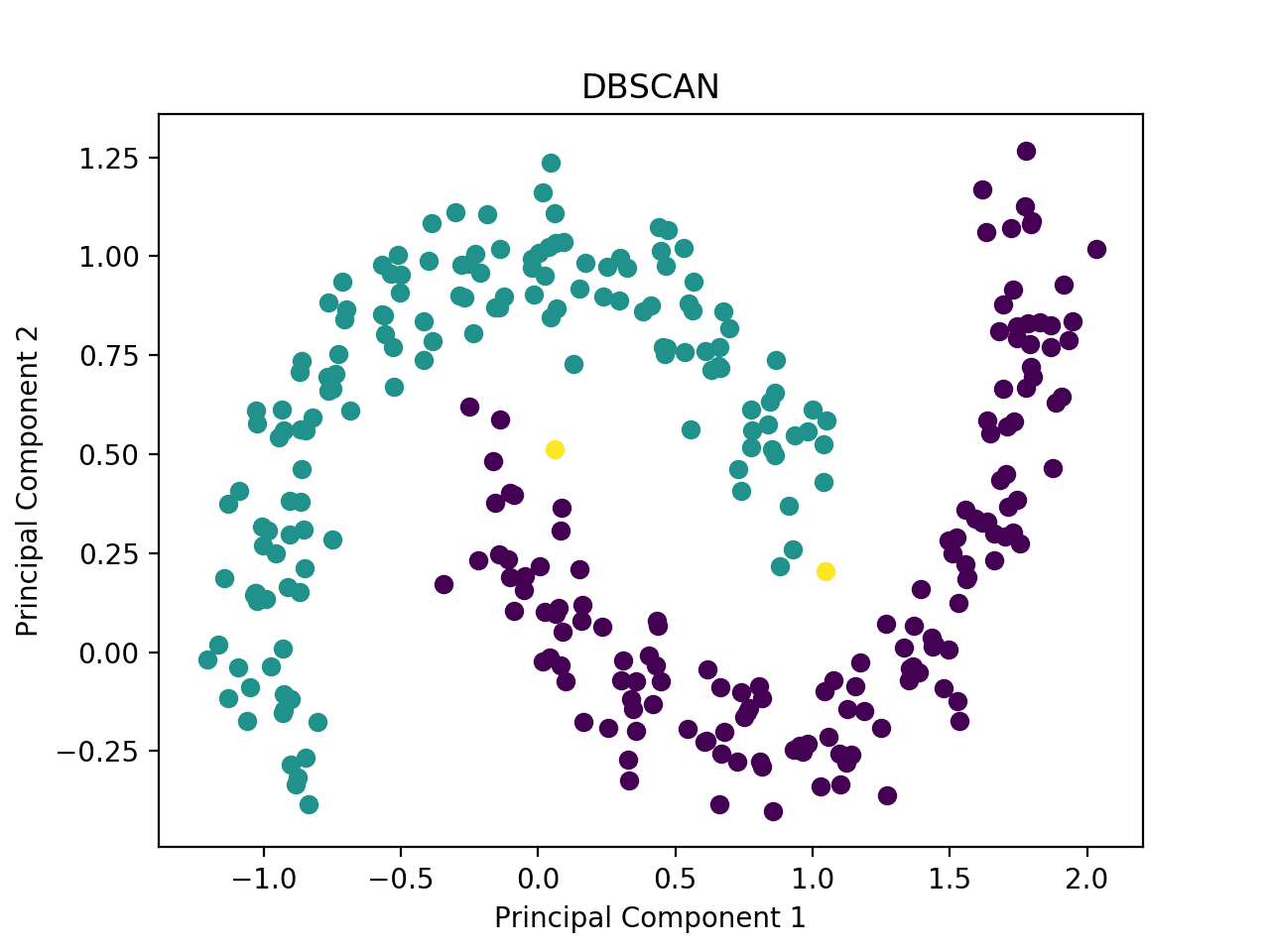
Figure: Clustering of the moons dataset using DBSCAN.
$ python mlfromscratch/unsupervised_learning/generative_adversarial_network.py +-----------+ | Generator | +-----------+ Input Shape: (100,) +------------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +------------------------+------------+--------------+ | Dense | 25856 | (256,) | | Activation (LeakyReLU) | 0 | (256,) | | BatchNormalization | 512 | (256,) | | Dense | 131584 | (512,) | | Activation (LeakyReLU) | 0 | (512,) | | BatchNormalization | 1024 | (512,) | | Dense | 525312 | (1024,) | | Activation (LeakyReLU) | 0 | (1024,) | | BatchNormalization | 2048 | (1024,) | | Dense | 803600 | (784,) | | Activation (TanH) | 0 | (784,) | +------------------------+------------+--------------+ Total Parameters: 1489936 +---------------+ | Discriminator | +---------------+ Input Shape: (784,) +------------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +------------------------+------------+--------------+ | Dense | 401920 | (512,) | | Activation (LeakyReLU) | 0 | (512,) | | Dropout | 0 | (512,) | | Dense | 131328 | (256,) | | Activation (LeakyReLU) | 0 | (256,) | | Dropout | 0 | (256,) | | Dense | 514 | (2,) | | Activation (Softmax) | 0 | (2,) | +------------------------+------------+--------------+ Total Parameters: 533762

Figure: Training progress of a Generative Adversarial Network generating
handwritten digits.
$ python mlfromscratch/examples/deep_q_network.py +----------------+ | Deep Q-Network | +----------------+ Input Shape: (4,) +-------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +-------------------+------------+--------------+ | Dense | 320 | (64,) | | Activation (ReLU) | 0 | (64,) | | Dense | 130 | (2,) | +-------------------+------------+--------------+ Total Parameters: 450

Figure: Deep Q-Network solution to the CartPole-v1 environment in OpenAI gym.
$ python mlfromscratch/examples/restricted_boltzmann_machine.py

Figure: Shows how the network gets better during training at reconstructing
the digit 2 in the MNIST dataset.
$ python mlfromscratch/examples/neuroevolution.py +---------------+ | Model Summary | +---------------+ Input Shape: (64,) +----------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +----------------------+------------+--------------+ | Dense | 1040 | (16,) | | Activation (ReLU) | 0 | (16,) | | Dense | 170 | (10,) | | Activation (Softmax) | 0 | (10,) | +----------------------+------------+--------------+ Total Parameters: 1210 Population Size: 100 Generations: 3000 Mutation Rate: 0.01 [0 Best Individual - Fitness: 3.08301, Accuracy: 10.5%] [1 Best Individual - Fitness: 3.08746, Accuracy: 12.0%] ... [2999 Best Individual - Fitness: 94.08513, Accuracy: 98.5%] Test set accuracy: 96.7%
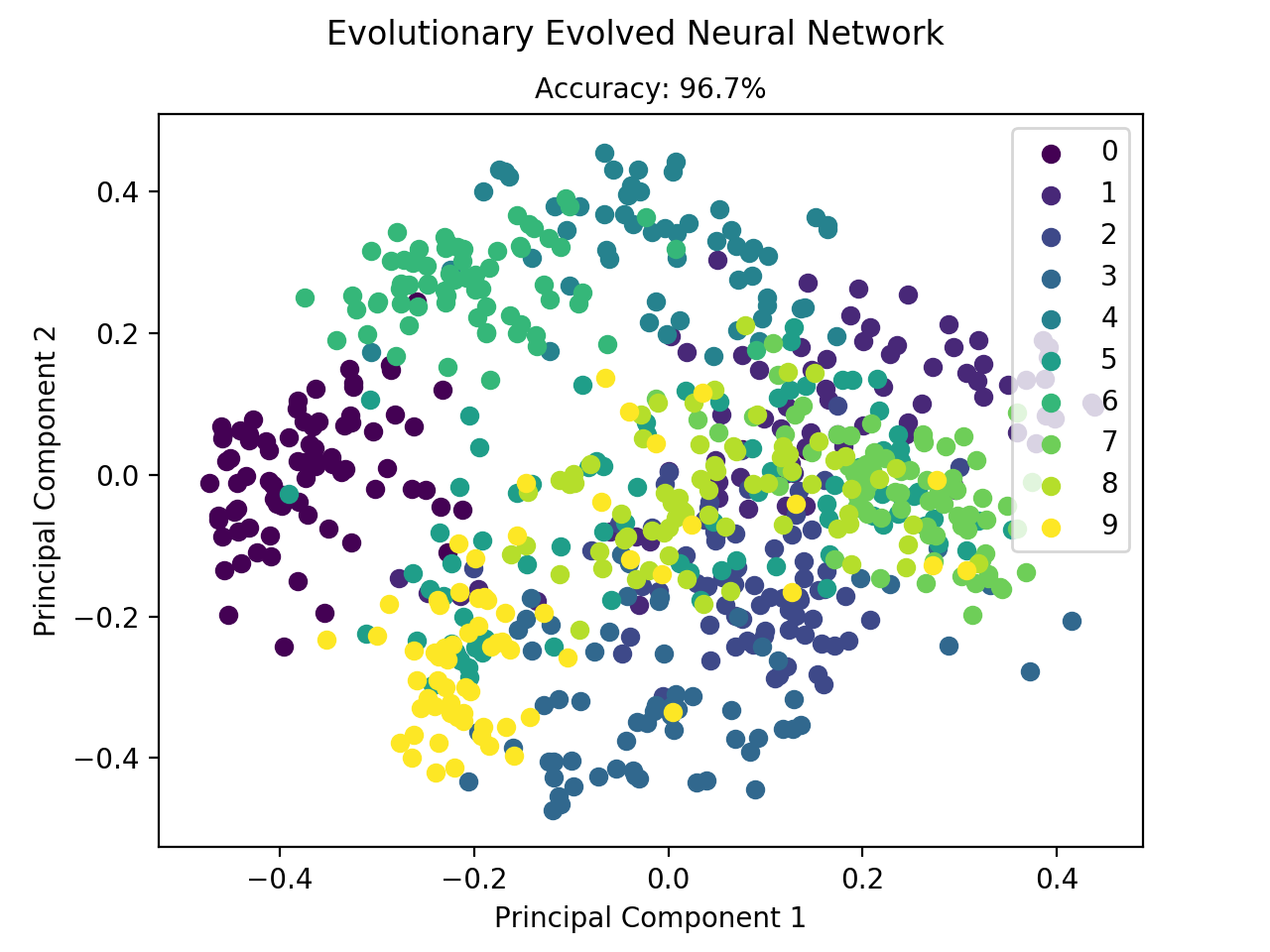
Figure: Classification of the digit dataset by a neural network which has
been evolutionary evolved.
$ python mlfromscratch/examples/genetic_algorithm.py +--------+ | GA | +--------+ Description: Implementation of a Genetic Algorithm which aims to produce the user specified target string. This implementation calculates each candidate's fitness based on the alphabetical distance between the candidate and the target. A candidate is selected as a parent with probabilities proportional to the candidate's fitness. Reproduction is implemented as a single-point crossover between pairs of parents. Mutation is done by randomly assigning new characters with uniform probability. Parameters ---------- Target String: 'Genetic Algorithm' Population Size: 100 Mutation Rate: 0.05 [0 Closest Candidate: 'CJqlJguPlqzvpoJmb', Fitness: 0.00] [1 Closest Candidate: 'MCxZxdr nlfiwwGEk', Fitness: 0.01] [2 Closest Candidate: 'MCxZxdm nlfiwwGcx', Fitness: 0.01] [3 Closest Candidate: 'SmdsAklMHn kBIwKn', Fitness: 0.01] [4 Closest Candidate: ' lotneaJOasWfu Z', Fitness: 0.01] ... [292 Closest Candidate: 'GeneticaAlgorithm', Fitness: 1.00] [293 Closest Candidate: 'GeneticaAlgorithm', Fitness: 1.00] [294 Answer: 'Genetic Algorithm']
$ python mlfromscratch/examples/apriori.py +-------------+ | Apriori | +-------------+ Minimum Support: 0.25 Minimum Confidence: 0.8 Transactions: [1, 2, 3, 4] [1, 2, 4] [1, 2] [2, 3, 4] [2, 3] [3, 4] [2, 4] Frequent Itemsets: [1, 2, 3, 4, [1, 2], [1, 4], [2, 3], [2, 4], [3, 4], [1, 2, 4], [2, 3, 4]] Rules: 1 -> 2 (support: 0.43, confidence: 1.0) 4 -> 2 (support: 0.57, confidence: 0.8) [1, 4] -> 2 (support: 0.29, confidence: 1.0)
If there's some implementation you would like to see here or if you're just feeling social, feel free to email me or connect with me on LinkedIn.
안녕하세요 Lidar SLAM공부중인 김기섭 입니다
#
지난주에 SLAM덩크 스터디에서 이종훈 님께서 레인지넷에 대해 소개해주셨는데요,
19 ICCV에 소개된 시맨틱 키티라는 point-wise 로 fully labeled 된 dataset이 있었기에 가능했던 연구였습니다.
#
시맨틱키티는
28가지 종류의 라벨 (도로, 폴, 인도, 자동차, 사람 등) 및
movable 한 object의 경우 (자동차, 사람 등) instance ID 또한 제공합니다.
이 정보를 이용하면 기존 segmentation work 뿐 아니라 object tracking 또는 dynamic/static 판별 등의 연구도 진행할 수 있을 것 같네요.
예시 영상입니다 https://youtu.be/gNeEfPEyHuw
#
저자가 공개한 파이썬API도 공개되어 있습니다.
https://github.com/PRBonn/semantic-kitti-api
저는 개인적으로 매트랩을 선호해서 매트랩 API도 간단히 만들어보았습니다.
https://github.com/kissb2/semantickitti-matlab
#
시맨틱 라이다 슬램 연구 관심 많으신분들 함께해요
감사합니다.
안녕하세요!
최근 ImageNet 에 SOTA 를 찍은 논문입니다.
https://arxiv.org/abs/1911.04252
캐글에서 많이 보던 pseudo-labeling 이 들어가있네요!
대략 정리하면
1. Train the teacher model with labeled data
2. Generate pseudo label for unlabeled data with teacher model
3. Train the student model with both labeled data and unlabeled data
4. Generate pseudo label for unlabeled data with teature model (student model in step 3)
5. Train the student model with both labeled data and unlabeled data
위 과정을 계속 반복합니다 ㅎ
성능이 매우 좋아지네요!
캐글에서 메달 따려면, SOTA 논문을 잘 보고, 그대로 쓰면 되겠죠?
https://www.facebook.com/groups/PyTorchKR/permalink/1620762534730088/
Pytorch로 image classification 작업하는 분들을 위해 좋은 github을 소개합니다.
https://github.com/rwightman/pytorch-image-models
(pip install timm이나 git clone https://github.com/rwightman/pytorch-image-models 등으로 사용하실 수 있습니다.)
이전에도 efficientnet code에 대해서 소개해드린 코드베이스입니다.
EfficientNet, ResNet, HRNet, SelecSLS등 다양한 모델들과 pretrained weight들을 갖추고 있으며, 모듈러 구조로 다양한 batchnorm, activation, 트레이닝트릭등(Autoaugment 등) 을 쉽게 사용할 수 있도록 짜여있습니다.
개인이 만든것이라고 생각하기에는 놀라울정도로 다양한 모델들과 아키텍쳐를 갖추고 있는데요, maintainer 본인이 여러 업무나 kaggle대회를 진행하거나 논문들을 살펴보면서 맞이하는 코드등을 쌓아가면서 코드를 형성했다고합니다.
최근에 네이버 클로버ai에서 resnet을 재구성하여 이전에 sota였던 efficientnet을 능가하는 assemblenet이 나온 후, 여기 maintainer도 tensorflow로 구성되어있던 원래의 코드를 pytorch로 구현하는 작업에 매진하고 있는 모양입니다.
현재는 selective kernel network를 구현하고 있는데요 이미 다양한 최적화, 모듈화가 가능한 자신의 코드베이스에 맞게 재구성중인 모양입니다.
저 개인적으로는 해당 assemblenet 논문의 결론부에서 언급된 ECA- Net(efficient channel attention)을 나름대로 재구성해서 해당 github에 pull request를 보내놓은 상태입니다.
이 과정에서 원래 ECA 논문(https://arxiv.org/pdf/1910.03151.pdf)
의 잠재적인 한계에 봉착하였습니다.
ECA 원문에서는 channel간의 결과를 convolution할때 kernel size에 맞게 zero padding하게 됩니다.
그러나 채널들간의 관계는 인접한 픽셀이나 feature map과는 다르기 때문에 zero padding하는게 무의미하다고 생각하였습니다.
"첫"채널이나 "마지막"채널은 기하학적이거나 위상적인 의미를 지니지 않을 것이기 때문에 더 zeropadding하여 더 적은 channel과 convolution하기보다는 circular padding을 통해 모든 채널이 같은 갯수의 서로 다른 채널들과 convolution하는게 논리적으로 맞다고 생각합니다.
그러한 논리적 접근에 따라 circular ECA module을 구현하여 함께 pull request를 하였지만, 꼭 해당 코드에만 사용해야하는 것은 아니라 이러한 attention module(ECA든 cECA든) 이 적합하다고 생각하시는 분이라면 참고해서 쓰실 수있으셨으면 좋겠습니다.
ECA PR: https://github.com/rwightman/pytorch-image-models/pull/82
해당 repo를 fork하여 eca를 구현한 제 코드
https://github.com/VRandme/pytorch-image-models/tree/eca
ECA가 SE, CBAM등 여태까지 나온 대부분의 attention model보다 우수한 성능을 보여주었는데, 저는 아직도 spatial attention을 구현한 CBAM에 미련이 남습니다.
그래서 이 코드가 정리되면 CBAM의 채널 attention부분만 ECA로 교체한 ECABAM?을 구현해볼 예정입니다.
안타깝게도 아직은 ImageNet수준의 트레이닝/테스팅을 수행할만한 여건이 되지 않아서 유의미한 진행은 어려울것같은데요, 곧 google collab에서 9.99$/mo로 무료 서비스와 차별화된 서비스를 제공한다고하니 한국에도 출시되면 알아봐야겠습니다.
관심있는 분들 살펴봐주시고 잘못된 부분등은 얼마든지 지적해주시기바랍니다. 감사합니다.



|
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
