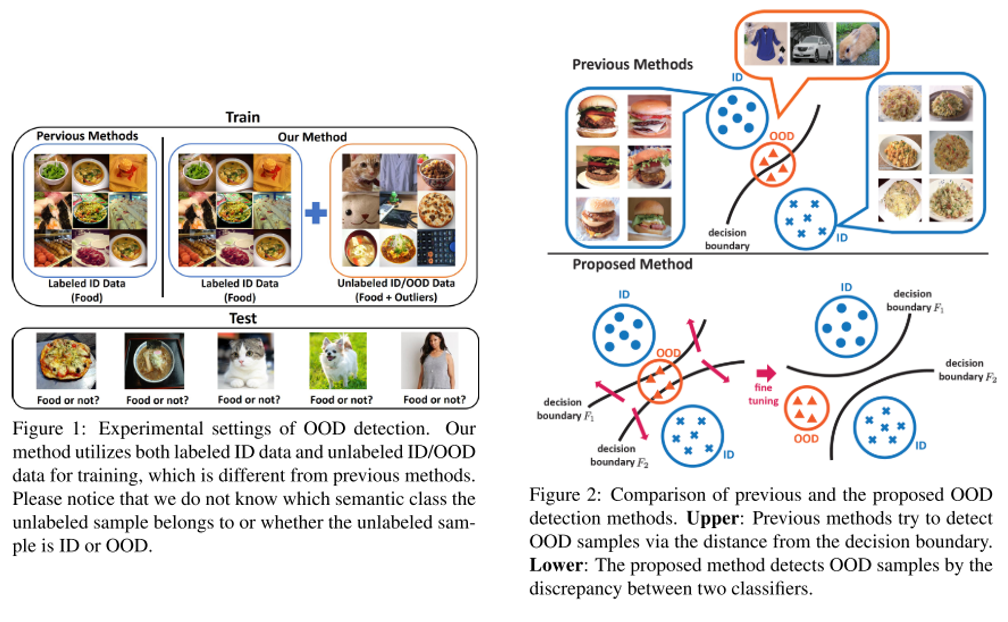
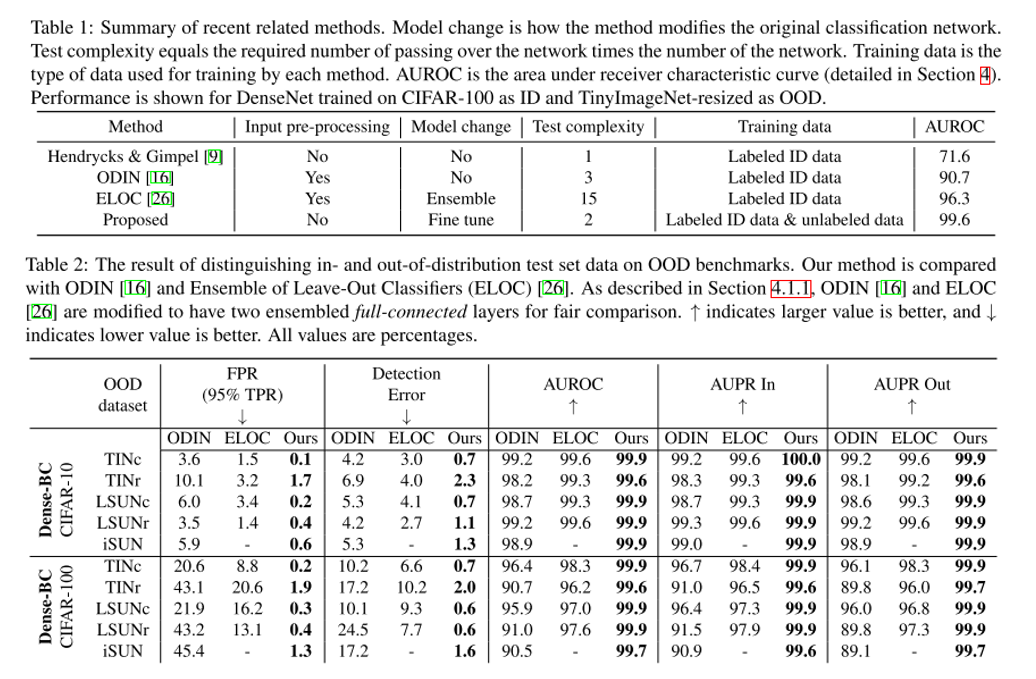
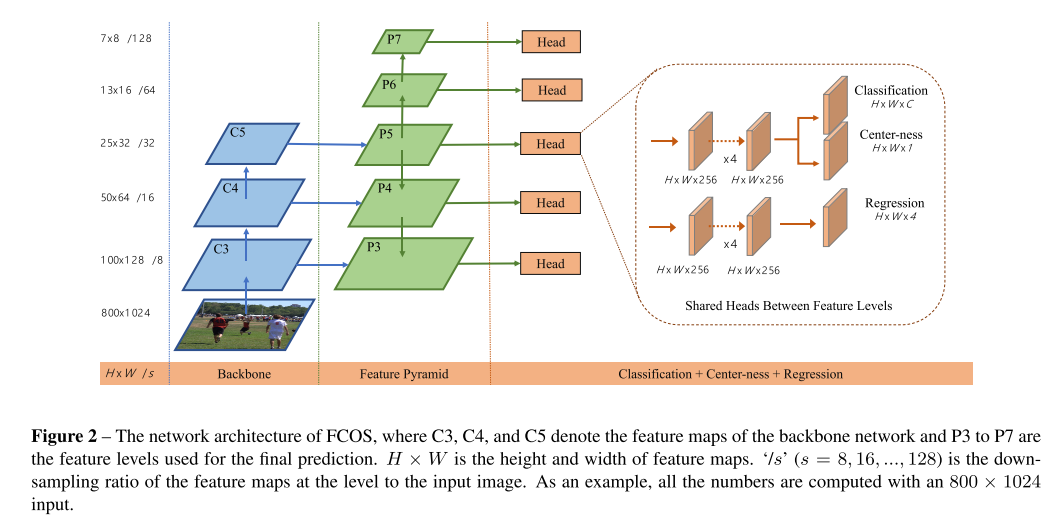
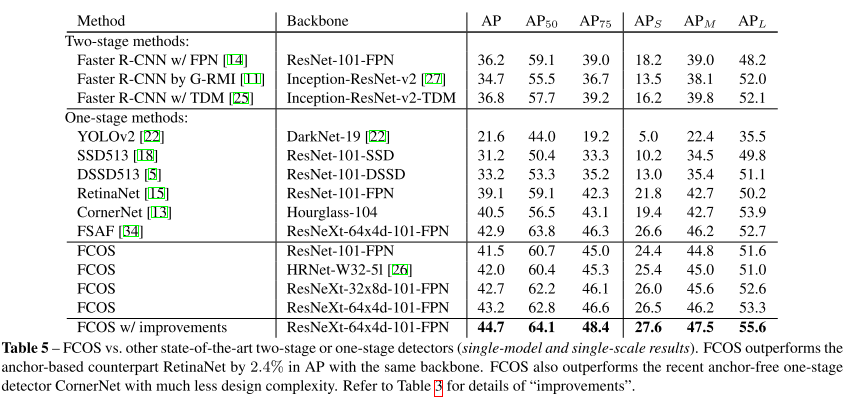
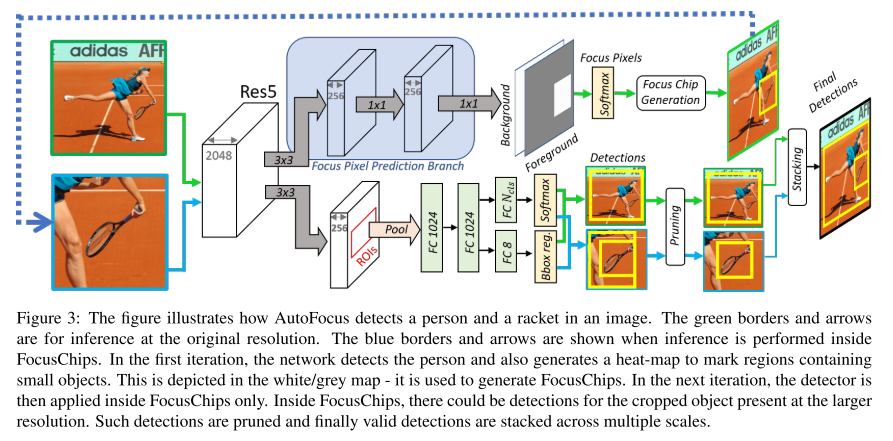
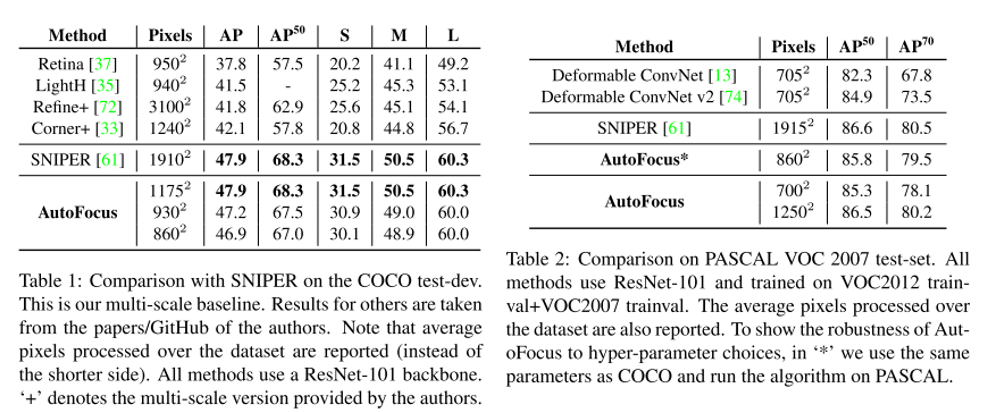
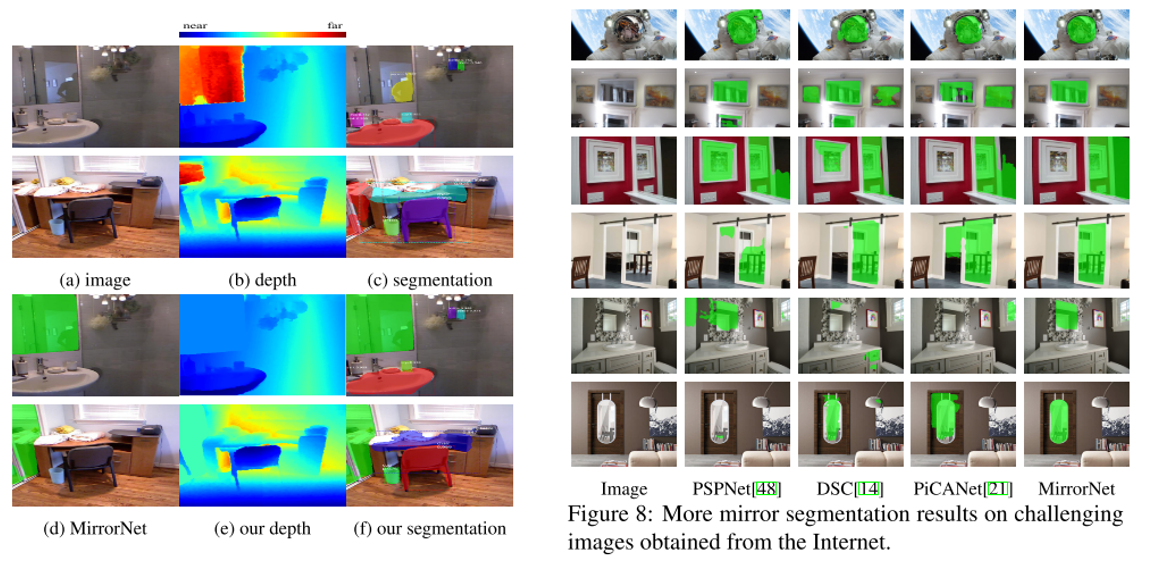
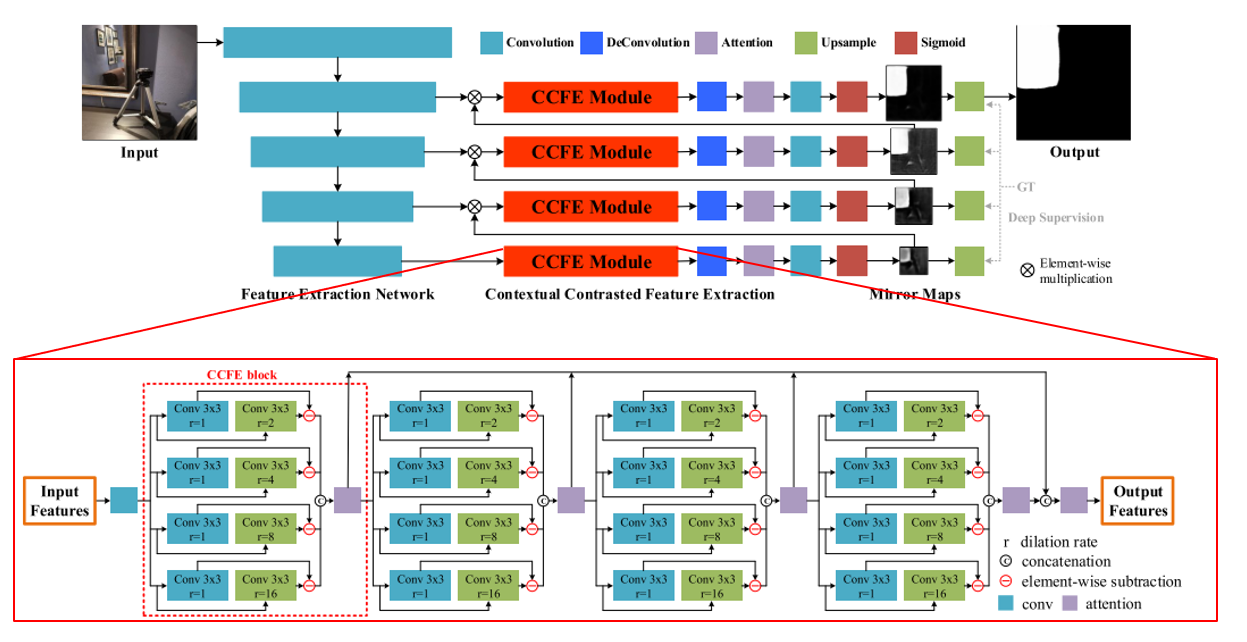
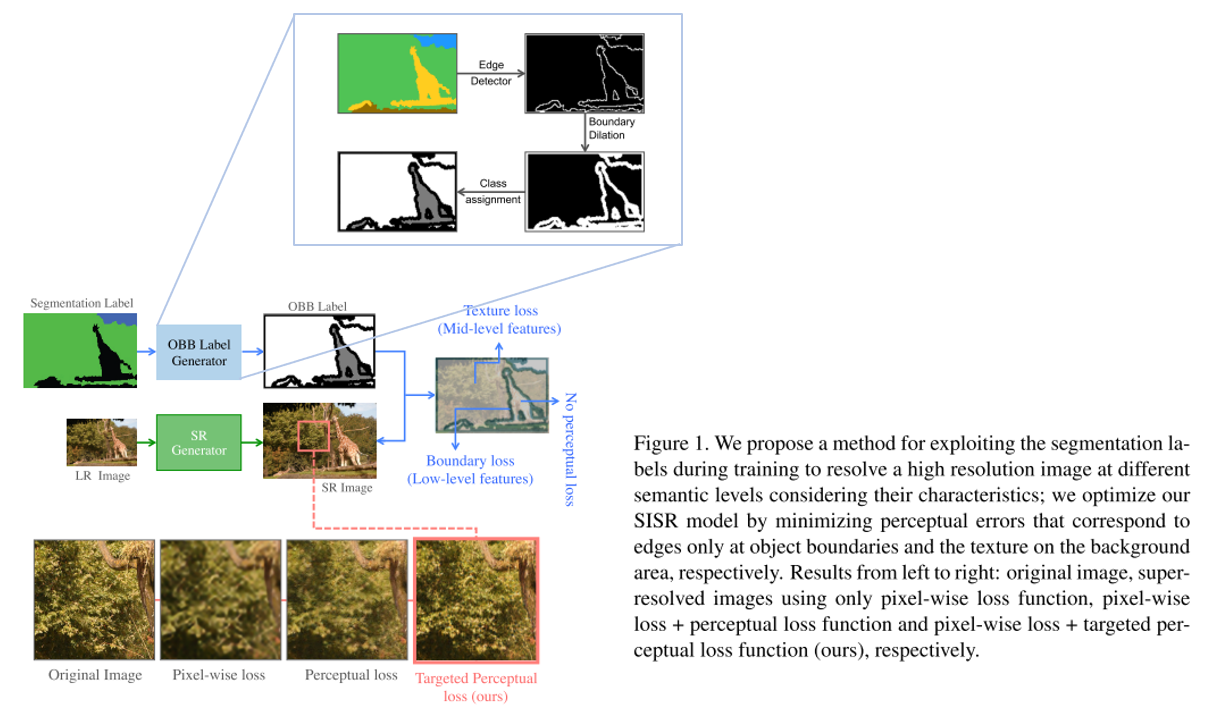
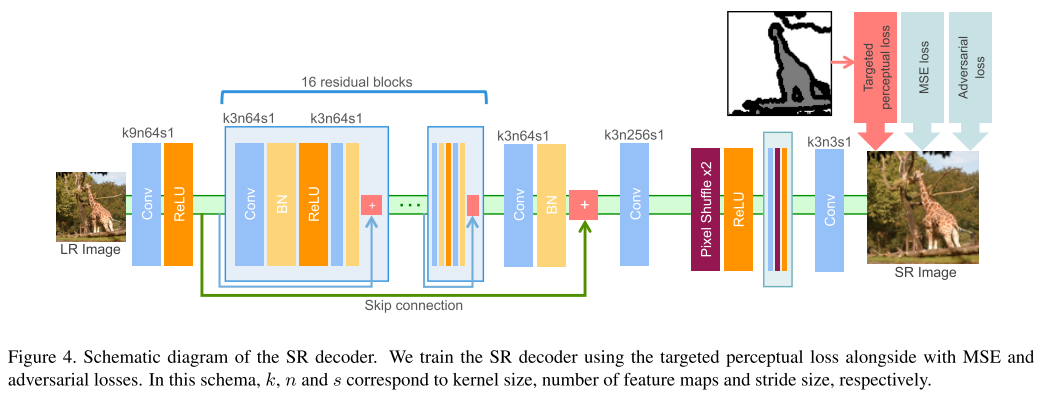
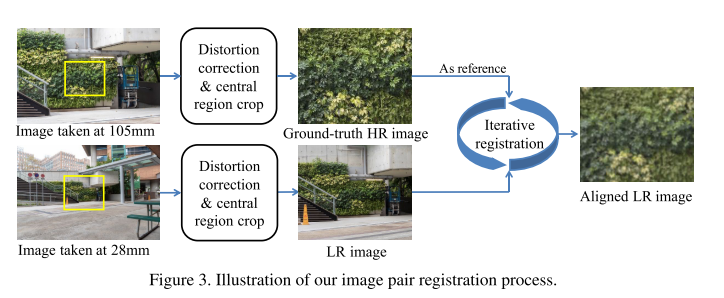
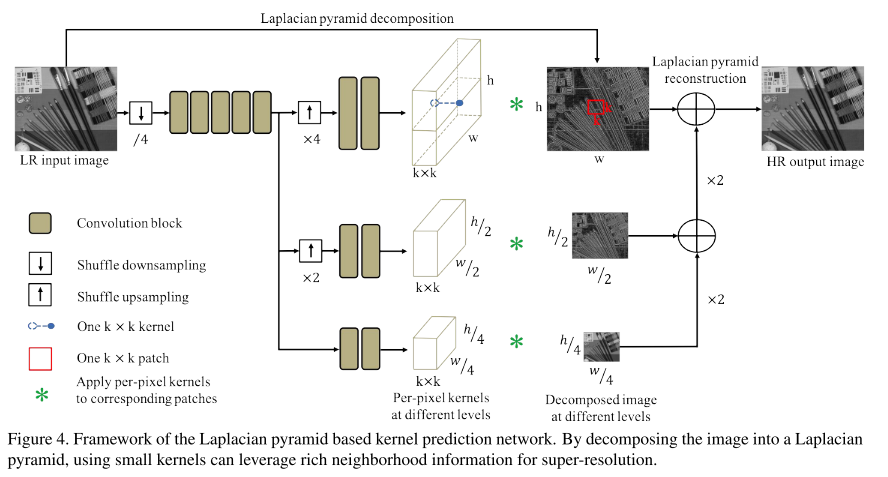
안녕하세요 TmaxData에서 NLP를 연구 중인 장영록입니다:) ALBERT(A Lite BERT - Google 2019.9)라는 논문을 소개드리고자 글 적 습니다. ALBERT는 BERT 보다 모델의 크기는 작지만 GLUE, SQuAD 등의 task에서 더 ..
Deep Learning/Papers2read 2019. 10. 28. 00:18안녕하세요 TmaxData에서 NLP를 연구 중인 장영록입니다:)
ALBERT(A Lite BERT - Google 2019.9)라는 논문을 소개드리고자 글 적 습니다.
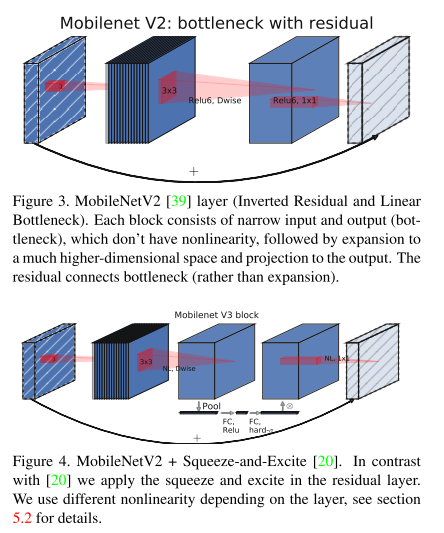
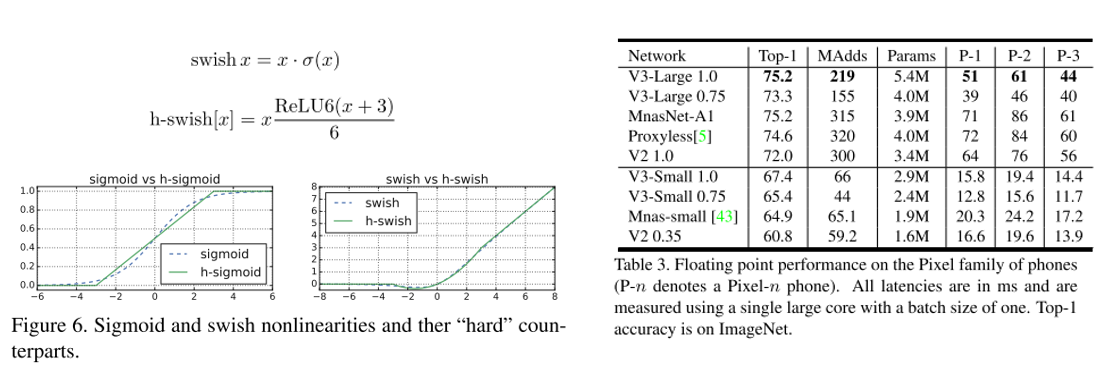
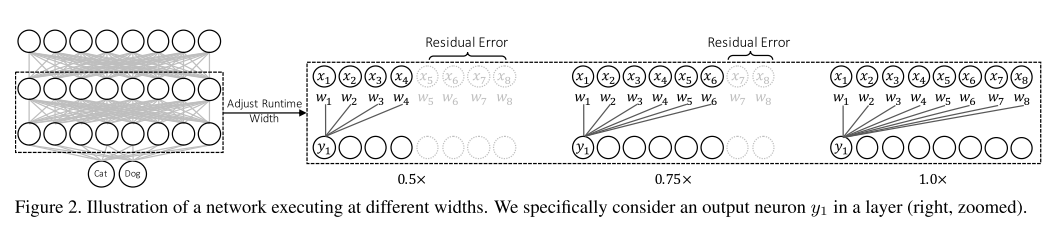
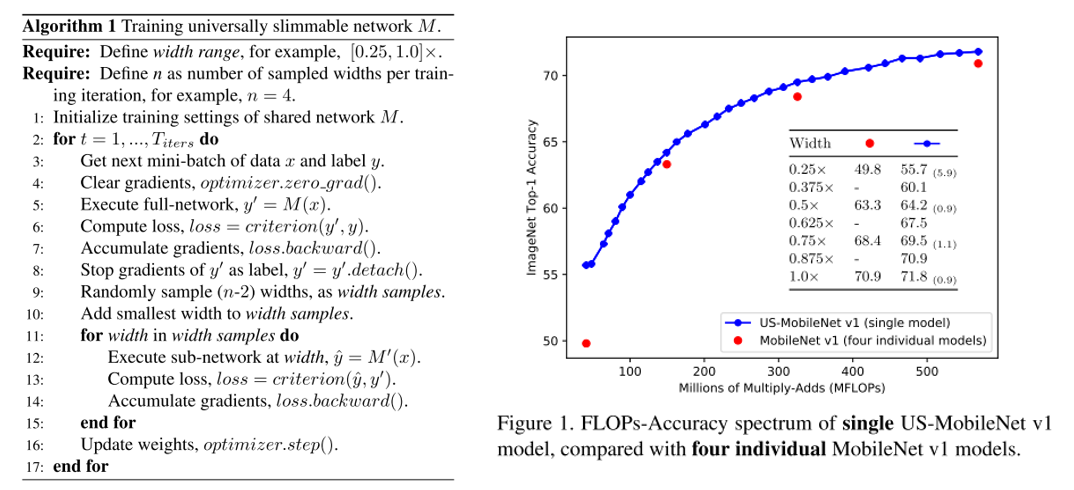
ALBERT는 BERT 보다 모델의 크기는 작지만 GLUE, SQuAD 등의 task에서 더 높은 성능을 달성한 모델입니다. Downstream Task에 높은 성능을 얻은 것도 중요하지만 Transformer의 각 Layer 간 Parameter를 공유하여 모델의 크기가 BERT 보다 현저히 줄었다는게 가장 큰 Contribution인 것 같습니다.
논문 내용을 정리한 제 블로그 글을 공유드리니 관심있으신 분은 보시길 바랍니다. :)
논문 링크 : [https://arxiv.org/abs/1909.11942](https://arxiv.org/abs/1909.11942)
논문 정리 블로그 : [https://y-rok.github.io/nlp/2019/10/23/albert.html](https://y-rok.github.io/nlp/2019/10/23/albert.html)
https://www.facebook.com/groups/TensorFlowKR/permalink/1020923228248735/?sfnsn=mo
ALBERT(A Lite BERT - Google 2019.9)라는 논문을 소개드리고자 글 적 습니다.
ALBERT는 BERT 보다 모델의 크기는 작지만 GLUE, SQuAD 등의 task에서 더 높은 성능을 달성한 모델입니다. Downstream Task에 높은 성능을 얻은 것도 중요하지만 Transformer의 각 Layer 간 Parameter를 공유하여 모델의 크기가 BERT 보다 현저히 줄었다는게 가장 큰 Contribution인 것 같습니다.
논문 내용을 정리한 제 블로그 글을 공유드리니 관심있으신 분은 보시길 바랍니다. :)
논문 링크 : [https://arxiv.org/abs/1909.11942](https://arxiv.org/abs/1909.11942)
논문 정리 블로그 : [https://y-rok.github.io/nlp/2019/10/23/albert.html](https://y-rok.github.io/nlp/2019/10/23/albert.html)
https://www.facebook.com/groups/TensorFlowKR/permalink/1020923228248735/?sfnsn=mo