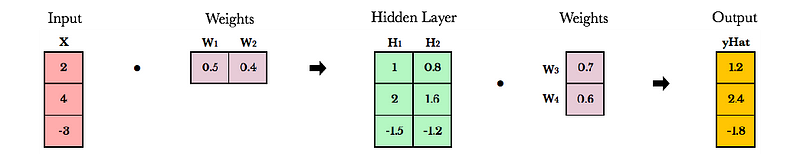
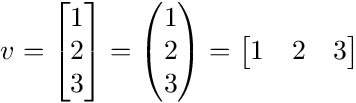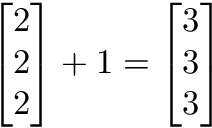Probabilistic Graphical Models Tutorial — Part 2 – Stats and Bots
Deep Learning/algorithm 2017. 11. 24. 10:38Probabilistic Graphical Models Tutorial — Part 2 – Stats and Bots
https://blog.statsbot.co/probabilistic-graphical-models-tutorial-d855ba0107d1
Homepage
Stats and Bots
Get started
HOMEDATA SCIENCEANALYTICSSTARTUPSBOTSDESIGNSUBSCRIBE TRY STATSBOT FREE
Go to the profile of Prasoon Goyal
Prasoon Goyal
PhD candidate at UT Austin. For more content on machine learning by me, check my Quora profile (https://www.quora.com/profile/Prasoon-Goyal).
Nov 23
Probabilistic Graphical Models Tutorial — Part 2
Parameter estimation and inference algorithms
In the previous part of this probabilistic graphical models tutorial for the Statsbot team, we looked at the two types of graphical models, namely Bayesian networks and Markov networks. We also explored the problem setting, conditional independences, and an application to the Monty Hall problem. In this post, we will cover parameter estimation and inference, and look at another application.
Parameter Estimation
Bayesian networks
Estimating the numbers in the CPD tables of a Bayesian network simply amounts to counting how many times that event occurred in our training data. That is, to estimate p(SAT=s1 | Intelligence = i1), we simply count the fraction of data points where SAT=s1 and Intelligence = i1, out of the total data points where Intelligence = i1. While this approach may appear ad hoc, it turns out that the parameters so obtained maximize the likelihood of the observed data.
Markov networks
For Markov networks, unfortunately, the above counting approach does not have a statistical justification (and will therefore lead to suboptimal parameters). So, we need to use more sophisticated techniques. The basic idea behind most of these techniques is gradient descent — we define parameters that describe the probability distribution, and then use gradient descent to find values for these parameters that maximize the likelihood of the observed data.
Finally, now that we have the parameters of our model, we want to use them on new data, to perform inference!
Inference
The bulk of the literature in probabilistic graphical models focuses on inference. The reasons are two-fold:
Inference is why we came up with this entire framework — being able to make predictions from what we already know.
Inference is computationally hard! In some specific kinds of graphs, we can perform inference fairly efficiently, but on general graphs, it is intractable. So we need to use approximate algorithms that trade off accuracy for efficiency.
There are several questions we can answer with inference:
Marginal inference: Finding the probability distribution of a specific variable. For instance, given a graph with variables A, B, C, and D, where A takes values 1, 2, and 3, find p(A=1), p(A=2) and p(A=3).
Posterior inference: Given some observed variables v_E (E for evidence) that take values e, finding the posterior distribution p(v_H | v_E=e) for some hidden variables v_H.
Maximum-a-posteriori (MAP) inference: Given some observed variables v_E that take values e, finding the setting of other variables v_H that have the highest probability.
Answers to these questions may be useful by themselves, or may need to be used as part of larger tasks.
In what follows, we are going to look at some of the popular algorithms for answering these questions, both exact and approximate. All these algorithms are applicable on both Bayesian networks and Markov networks.
Variable Elimination
Using the definition of conditional probability, we can write the posterior distribution as:
Let’s see how we can compute the numerator and the denominator above, using a simple example. Consider a network with three variables, and the joint distribution defined as follows:
Let’s say we want to compute p(A | B=1). Note that this means that we want to compute the values p(A=0 | B=1)and p(A=1 | B=1), which should sum to one. Using the above equation, we can write
The numerator is the probability that A = 0 and B = 1. We don’t care about the values of C. So we would sum over all the values of C. (This comes from basic probability — p(A=0, B=1, C=0) and p(A=0, B=1, C=1) are mutually exclusive events, so their union p(A = 0, B=1) is just the sum of the individual probabilities.)
So we add rows 3 and 4 to get p(A=0, B=1) = 0.15. Similarly, adding rows 7 and 8 gives usp(A=1, B=1) = 0.40. Also, we can compute the denominator by summing over all rows that contain B=1, that is, rows 3, 4, 7, and 8, to get p(B=1) = 0.55. This gives us the following:
p(A = 0 | B = 1) = 0.15 / 0.55 = 0.27
p(A = 1 | B = 1) = 0.40 / 0.55 = 0.73
If you look at the above computation closely, you would notice that we did some repeated computations — adding rows 3 & 4, and 7 & 8 twice. A more efficient way to compute p(B=1)would have been to simply add the values p(A=0, B=1) and p(A=1, B=1). This is the basic idea of variable elimination.
In general, when you have a lot of variables, not only can you use the values of the numerator to compute the denominator, but the numerator by itself will contain repeated computations, if evaluated naively. You can use dynamic programming to use precomputed values efficiently.
Because we are summing over one variable at a time, thereby eliminating it, the process of summing out multiple variables amounts to eliminating these variables one at a time. Hence, the name “variable elimination.”
It is straightforward to extend the above process to solve the marginal inference or MAP inference problems as well. Similarly, it is easy to generalize the above idea to apply it to Markov networks too.
The time complexity of variable elimination depends on the graph structure, and the order in which you eliminate the variables. In the worst case, it has exponential time complexity.
Belief Propagation
The VE algorithm that we just saw gives us only one final distribution. Suppose we want to find the marginal distributions for all variables. Instead of running variable elimination multiple times, we can do something smarter.
Suppose you have a graph structure. To compute a marginal, you need to sum the joint distribution over all other variables, which amounts to aggregating information from the entire graph. Here’s an alternate way of aggregating information from the entire graph — each node looks at its neighbors, and approximates the distribution of variables locally.
Then, every pair of neighboring nodes send “messages” to each other where the messages contain the local distributions. Now, every node looks at the messages it receives, and aggregates them to update its probability distributions of variables.
In the figure above, C aggregates information from its neighbors A and B, and sends a message to D. Then, D aggregates this message with the information from E and F.
The advantage of this approach is that if you save the messages that you are sending at every node, one forward pass of messages followed by one backward pass gives all nodes information about all other nodes. That information can then be used to compute all the marginals, which was not possible in variable elimination.
If the graph does not contain cycles, then this process converges after a forward and a backward pass. If the graph contains cycles, then this process may or may not converge, but it can often be used to get an approximate answer.
Approximate inference
Because exact inference may be prohibitively time consuming for large graphical models, numerous approximate inference algorithms have been developed for graphical models, most of which fall into one of the following two categories:
Sampling-based
These algorithms estimate the desired probability using sampling. As a simple example, consider the following scenario — given a coin, how you would determine the probability of getting heads when the coin is tossed? The simplest thing is to flip the coin, say, 100 times, and find out the fraction of tosses in which you get heads.
This is a sampling-based algorithm to estimate the probability of heads. For more complex questions in probabilistic graphical models, you can use a similar procedure. Sampling-based algorithms can further be divided into two classes. In the first one, the samples are independent of each other, as in the coin toss example above. These algorithms are called Monte Carlo methods.
For problems with many variables, generating good quality independent samples is difficult, and therefore, we generate dependent samples, that is, each new sample is random, but close to the last sample. Such algorithms are called Markov Chain Monte Carlo (MCMC) methods, because the samples form a “Markov chain.” Once we have the samples, we can use them to answer various inference questions.
Variational methods
Instead of using sampling, variational methods try to approximate the required distribution analytically. Suppose you write out the expression for computing the distribution of interest — marginal probability distribution or posterior probability distribution.
Often, these expressions have summations or integrals in them that are computationally expensive to evaluate exactly. A good way to approximate these expressions is to then solve for an alternate expression, and somehow ensure that this alternate expression is close to the original expression. This is the basic idea behind variational methods.
When we are trying to estimate a complex probability distribution p_complex, we define a separate set of probability distributions P_simple, which are easier to work with, and then find the probability distribution p_approx from P_simple that is closest to p_complex.
Application: Image denoising
Let us now use some of the ideas we just discussed on a real problem. Let’s say you have the following image:
Now suppose that it got corrupted by random noise, so that your noisy image looks as follows:
The goal is to recover the original image. Let’s see how we can use probabilistic graphical models to do this.
The first step is to think about what our observed and unobserved variables are, and how we can connect them to form a graph. Let us define each pixel in the noisy image as an observed random variable, and each pixel in the ground truth image as an unobserved variable. So, if the image is M x N, then there are MN observed variables and MN unobserved variables. Let us denote observed variables as X_ij and unobserved variables as Y_ij. Each variable takes values +1 and -1 (corresponding to black and white pixels, respectively). Given the observed variables, we want to find the most likely values of the unobserved variables. This corresponds to MAP inference.
Now, let us use some domain knowledge to build the graph structure. Clearly, the observed variable at position (i, j) in the noisy image depends on the unobserved variable at position (i, j) in the ground truth image. This is because most of the time, they are identical.
What more can we say? For ground truth images, the neighboring pixels usually have the same values — this is not true at the boundaries of color change, but inside a single-colored region, this property holds. Therefore, we connect Y_ij and Y_kl if they are neighboring pixels.
So, our graph structure looks as follows:
Here, the white nodes denote the unobserved variables Y_ij and the grey nodes denote observed variables X_ij. Each X_ij is connected to the corresponding Y_ij, and each Y_ij is connected to its neighbors.
Note that this is a Markov network, because there is no cause-effect relation between pixels of an image, and therefore, defining directions of arrows in Bayesian networks is unnatural here.
Our MAP inference problem can be mathematically written as follows:
Here, we used some standard simplification techniques common in maximum log likelihood computation. We will use X and Y(without subscripts) to denote the collection of all X_ij and Y_ij values, respectively.
Now, we need to define our joint distribution P(X, Y) based on our graph structure. Let’s assume that P(X, Y) consists of two kinds of factors — ϕ(X_ij, Y_ij) and ϕ(Y_ij,Y_kl), corresponding to the two kinds of edges in our graph. Next, we define the factors as follows:
ϕ(X_ij, Y_ij) = exp(w_e X_ij Y_ij), where w_e is a parameter greater than zero. This factor takes large values when X_ij and Y_ij are identical, and takes small values when X_ij and Y_ij are different.
ϕ(Y_ij, Y_kl) = exp(w_s Y_ij Y_kl), where w_s is a parameter greater than zero, as before. This factor favors identical values of Y_ij and Y_kl.
Therefore, our joint distribution is given by:
where (i, j) and (k, l) in the second product are adjacent pixels, and Z is a normalization constant.
Plugging this into our MAP inference equation gives:
Note that we have dropped the term containing Zsince it does not affect the solution.
The values of w_e and w_s are obtained using parameter estimation techniques from pairs of ground truth and noisy images. This process is fairly mathematically involved (although, at the end of the day, it is just gradient descent on a complicated function), and therefore, we shall not delve into it here. We will assume that we have obtained the following values of these parameters — w_e = 8 and w_s = 10.
The main focus of this example will be inference. Given these parameters, we want to solve the MAP inference problem above. We can use a variant of belief propagation to do this, but it turns out that there is a much simpler algorithm called Iterated conditional modes (ICM) for graphs with this specific structure.
The basic idea is that at each step, you choose one node, Y_ij, look at the value of the MAP inference expression for both Y_ij = -1 and Y_ij = 1, and pick the one with the higher value. Repeating this process for a fixed number of iterations or until convergence usually works reasonably well.
You can use this Python code to do this for our model.
This is the denoised image returned by the algorithm:
Pretty good, isn’t it? Of course, you can use more fancy techniques, both within graphical models, and outside, to generate something better, but the takeaway from this example is that a simple Markov network with a simple inference algorithm already gives you reasonably good results.
Quantitatively, the noisy image has about 10% of the pixels that are different from the original image, while the denoised image produced by our algorithm has about 0.6% of the pixels that are different from the original image.
It is important to note that the graph that we used is fairly large — the image size is about 440 x 300, so the total number of nodes is close to 264,000. Therefore, exact inference in such models is essentially infeasible, and what we get out of most algorithms, including ICM, is a local optimum.
Let’s recap
In this section, let us briefly review the key concepts we covered in this two-part series:
Graphical models: A graphical model consists of a graph structure where nodes represent random variables and edges represent dependencies between variables.
Bayesian networks: These are directed graphical models, with a conditional probability distribution table associated with each node.
Markov networks: These are undirected graphical models, with a potential function associated with each clique.
Conditional independences: Based on how the nodes in the graph are connected, we can write conditional independence statements of the form “X is independent of Y given Z.”
Parameter estimation: Given some data and the graph structure, we want to fill the CPD tables or compute the potential functions.
Inference: Given a graphical model, we want to answer questions about unobserved variables. These questions are usually one of the following — Marginal inference, posterior inference, and MAP inference.
Inference on general graphical models is computationally intractable. We can divide inference algorithms into two broad categories — exact and approximate. Variable elimination and belief propagation in acyclic graphs are examples of exact inference algorithms. Approximate inference algorithms are necessary for large-scale graphs, and usually fall into sampling-based methods or variational methods.
Conclusions
We looked at some of the core ideas in probabilistic graphical models in this two-part tutorial. As you should be able to appreciate at this point, graphical models provide an interpretable way to model many real-world tasks, where there are dependencies. Using graphical models gives us a way to work on such tasks in a principled manner.
Before we close, it is important to point out that this tutorial, by no means, is complete — many details have been skipped to keep the content intuitive and simple. The standard textbook on probabilistic graphical models is over a thousand pages! This tutorial is meant to serve as a starting point, to get you interested in the field, so that you can look up more rigorous resources.
Here are some additional resources that you can use to dig deeper into the field:
Graphical Models in a Nutshell
Graphical Models textbook
You should also be able to find a few chapters on graphical models in standard machine learning textbooks.
YOU’D ALSO LIKE:
Probabilistic Graphical Models Tutorial — Part 1
Basic terminology and the problem setting
blog.statsbot.co
Machine Learning Algorithms: Which One to Choose for Your Problem
Intuition of using different kinds of algorithms in different tasks
blog.statsbot.co
Neural networks for beginners: popular types and applications
An introduction to neural networks learning
blog.statsbot.co
Machine LearningData ScienceAlgorithmsBayesian StatisticsMarkov Chains
One clap, two clap, three clap, forty?
By clapping more or less, you can signal to us which stories really stand out.
265
Follow
Go to the profile of Prasoon Goyal
Prasoon Goyal
PhD candidate at UT Austin. For more content on machine learning by me, check my Quora profile (https://www.quora.com/profile/Prasoon-Goyal).
Follow
Stats and Bots
Stats and Bots
Data stories on machine learning and analytics. From Statsbot’s makers.
More from Stats and Bots
Neural networks for beginners: popular types and applications
Go to the profile of Jay Shah
Jay Shah
287
Also tagged Markov Chains
Implementing Markov Chain in Swift. Generating Texts.
Go to the profile of Swift The Sorrow
Swift The Sorrow
41
More on Algorithms from Stats and Bots
Data Structures Related to Machine Learning Algorithms
Go to the profile of Peter Mills
Peter Mills
275
'Deep Learning > algorithm' 카테고리의 다른 글
| Swish activation, get slightly better result Than ReLU. (0) | 2017.10.26 |
|---|---|
| A miscellany of fun deep learning papers (0) | 2017.03.26 |
| Faster R-CNN 한글 설명 (0) | 2017.03.26 |
| GAN 그리고 Unsupervised Learning (0) | 2017.03.22 |
| Linear algebra cheat sheet for deep learning (0) | 2017.03.09 |