Top 20 Data Science interview questions and answers.
https://www.facebook.com/groups/machinelearningforum/permalink/10158132975188475/?sfnsn=mo
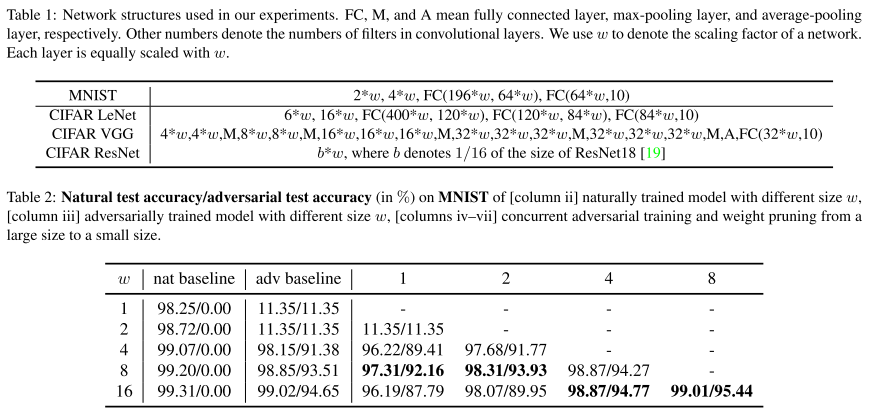
https://www.facebook.com/groups/machinelearningforum/permalink/10158132975188475/?sfnsn=mo
안녕하세요, 이번 포스팅에서는 2019년 10월 27일 ~ 11월 2일 우리나라 서울에서 개최될 ICCV 2019 학회의 accepted paper들에 대해 분석하여 시각화한 자료를 보여드리고, accepted paper 중에 제 관심사를 바탕으로 22편의 논문을 간단하게 리뷰를 할 예정입니다. 최근 모든 학회들이 다 그렇듯이 전체 accepted paper가 폭발적으로 많아지고 있습니다. 논문 수가 많다 보니 하나하나 읽기에는 시간이 많이 소요가 되어서 제목만 보고 논문 리스트를 추리게 되었습니다.
당부드리는 말씀은 제가 정리한 논문 리스트에 없다고 재미 없거나 추천하지 않는 논문은 절대 아니고 단지 제 주관에 의해 정리된 것임을 강조 드리고 싶습니다.!!
ICCV 2019 Paper Statistics
메이저 학회에 대한 미리보기 형식의 블로그 글들을 여러 편 썼는데 이번에는 5번째 글을 작성하게 되었습니다.
매번 하던 것처럼 이번에도 ICCV 2019에 몇 편의 논문이 submit되고 accept되는 지 경향을 시각화하였습니다.
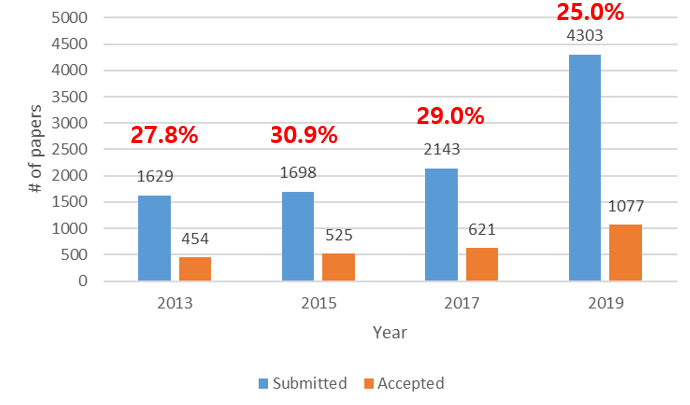
격년으로 진행되어오는 학회인데 2017년까지만 해도 학회에 제출되는 논문의 규모가 약간씩 상승하는 경향을 보였습니다. 그런데 올해에는 2년전에 비해 제출된 논문의 수가 약 2배가량 커졌으며 이에 따라 acceptance rate도 25%대로 크게 떨어진 것을 확인할 수 있습니다. 이러한 경향은 CVPR 2019과도 거의 동일한 것이 흥미로운 점입니다. (2017년 대비 제출된 논문 2배 증가, acceptance rate 30% 25% 감소)
또한 어떤 키워드의 논문들이 많이 제출되는지 경향을 분석하기위해 간단한 python script를 작성해보았습니다.
단순하게 논문 제목에 포함된 키워드를 분석하여 시각화를 하였으며, 코드는 해당 repository 에서 확인하실 수 있습니다. (Star는 저에게 큰 힘이됩니다!)
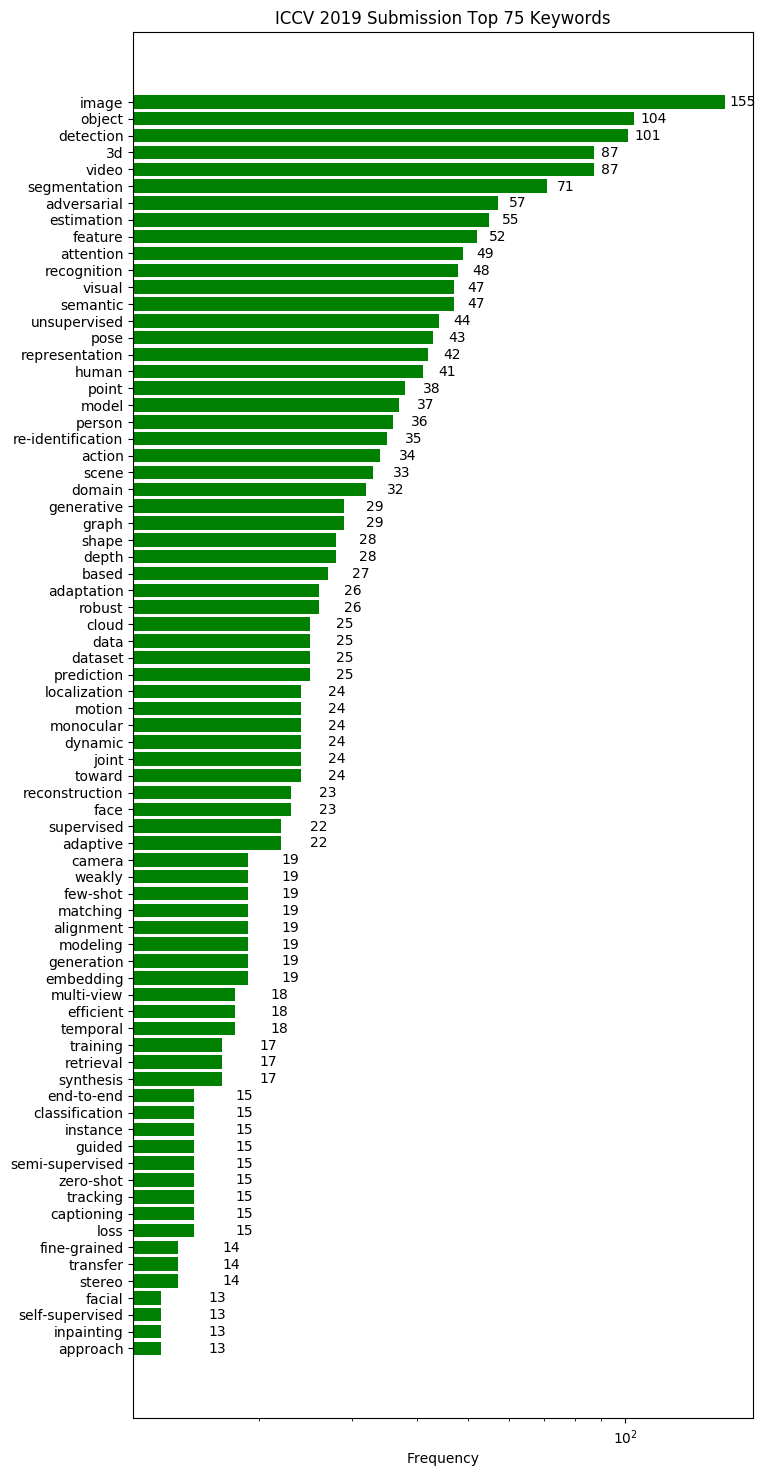
Computer Vision 학회이다 보니 image, video, object 등 general한 키워드들이 주를 이루고 있고, attention, unsupervised, re-identification 등의 키워드를 가진 논문들이 빈도가 증가하였습니다. 이러한 키워드 정보를 참고하면 최근 학회에 제출되는 논문들의 트렌드를 파악하는데 도움이 될 수 있습니다.
참고로 올해는 총 1077편의 논문이 accept 되었고 저는 이 논문들 중 22편을 선정해서 간단하게 소개를 드릴 예정입니다.
ICCV 2019 주요 논문 소개
앞서 말씀드렸듯이 accept된 논문을 모두 다 확인하기엔 시간과 체력이 부족하여서, 간단하게 훑어보면서 재미가 있을 것 같은 논문들을 추려보았습니다. 총 22편의 논문이며, 8편의 oral paper, 14편의 poster paper로 준비를 해보았습니다. 각 논문에서 제안한 방법들을 그림과 함께 간략하게 소개드릴 예정이며, 논문의 디테일한 내용은 직접 논문을 읽어 보시는 것을 추천 드립니다.
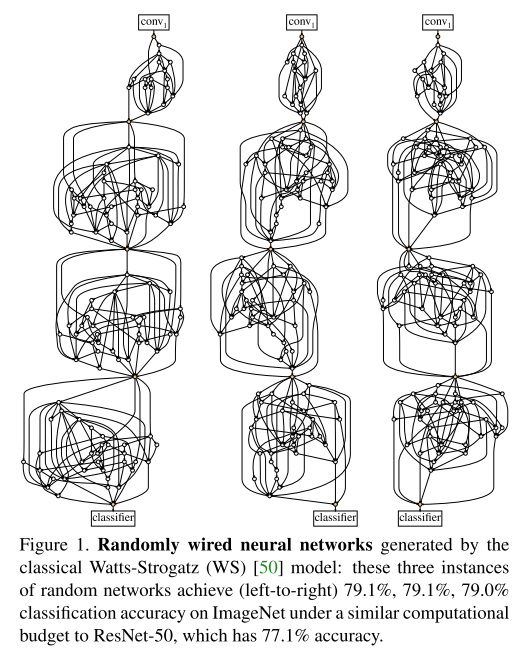
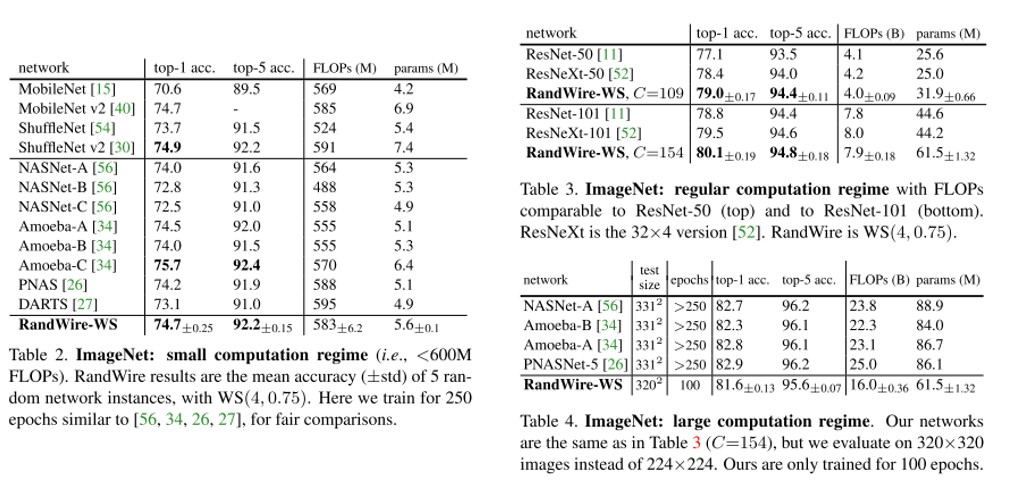
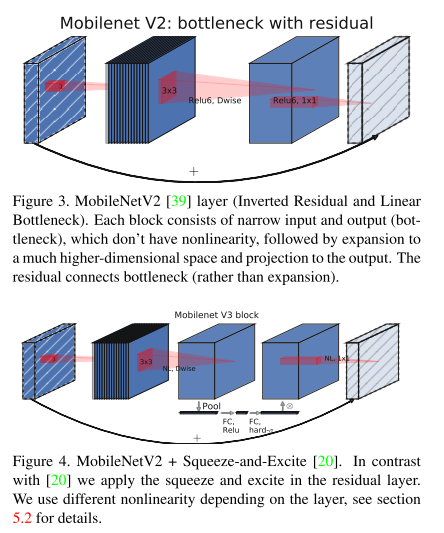
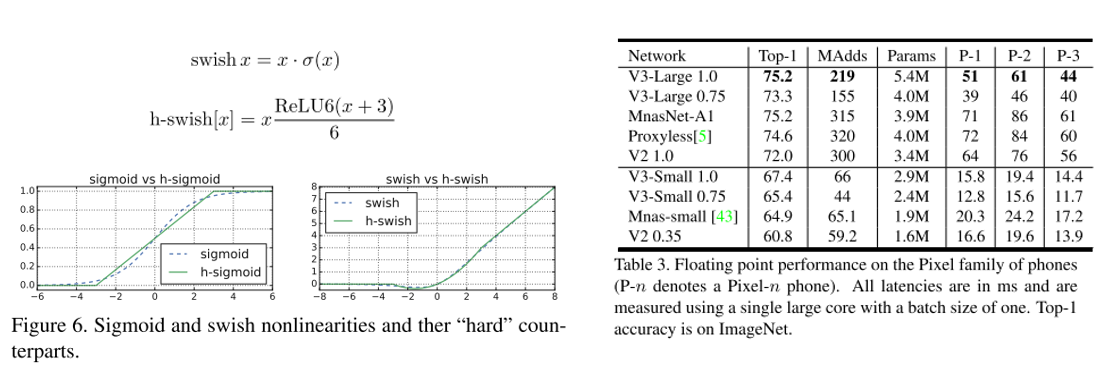
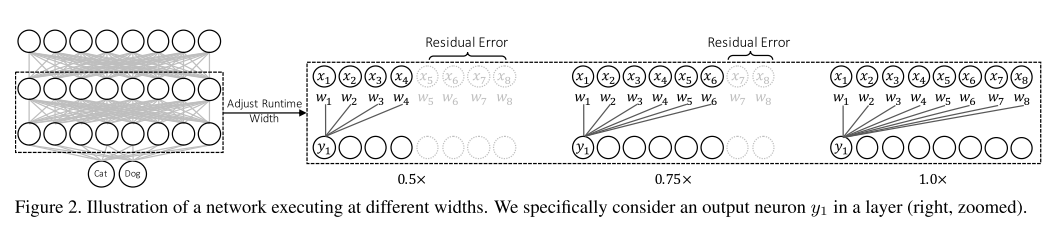
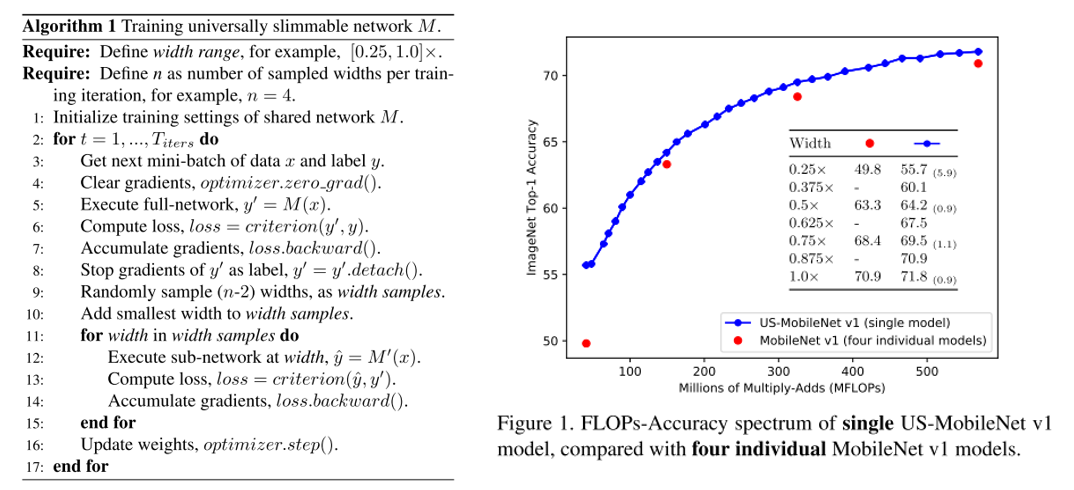
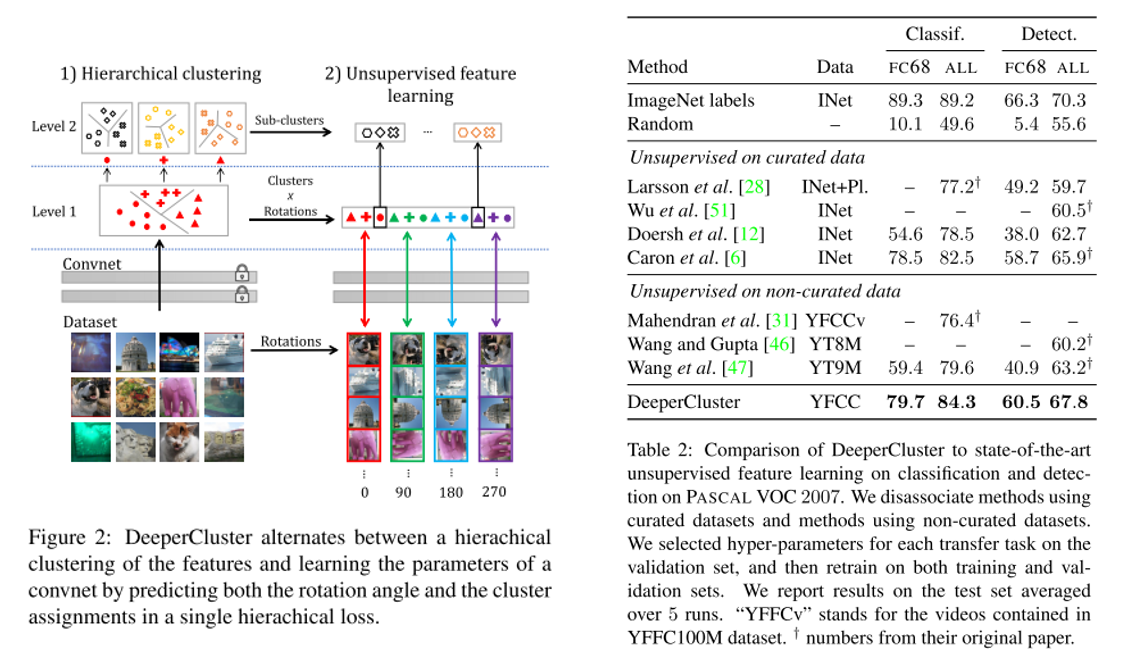

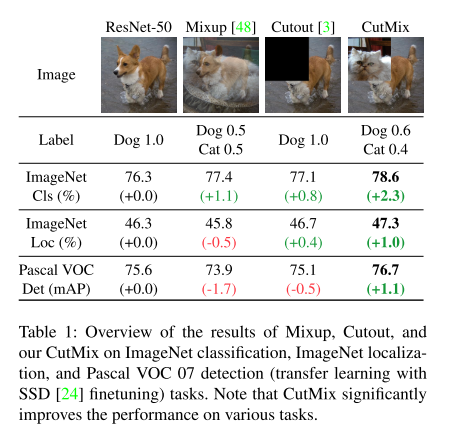
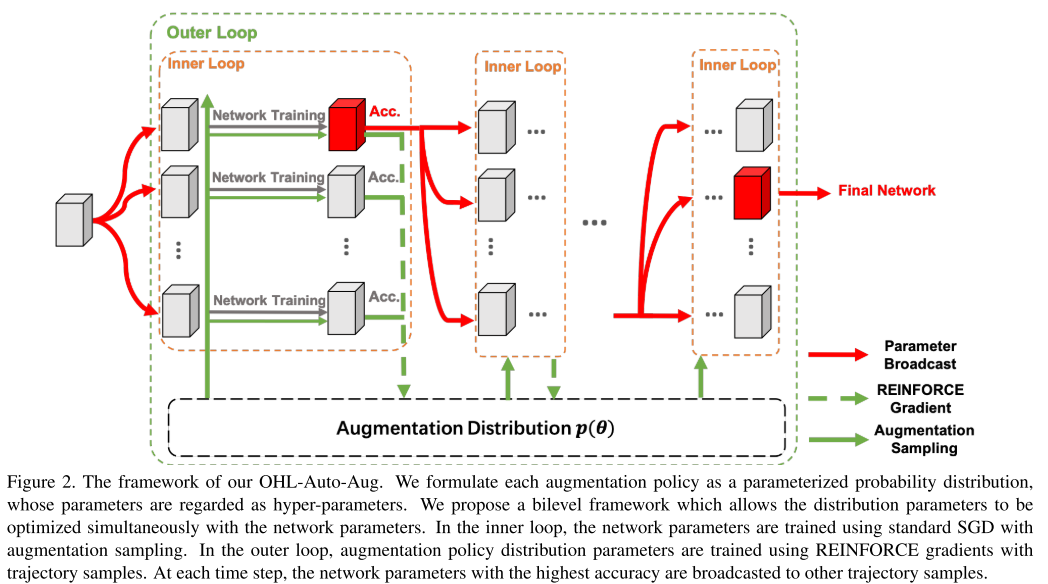
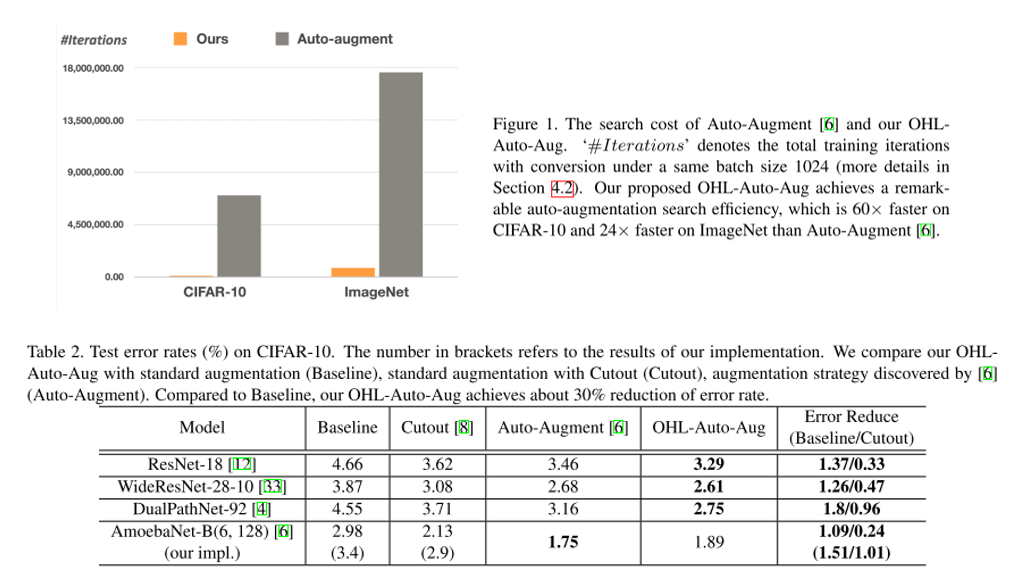
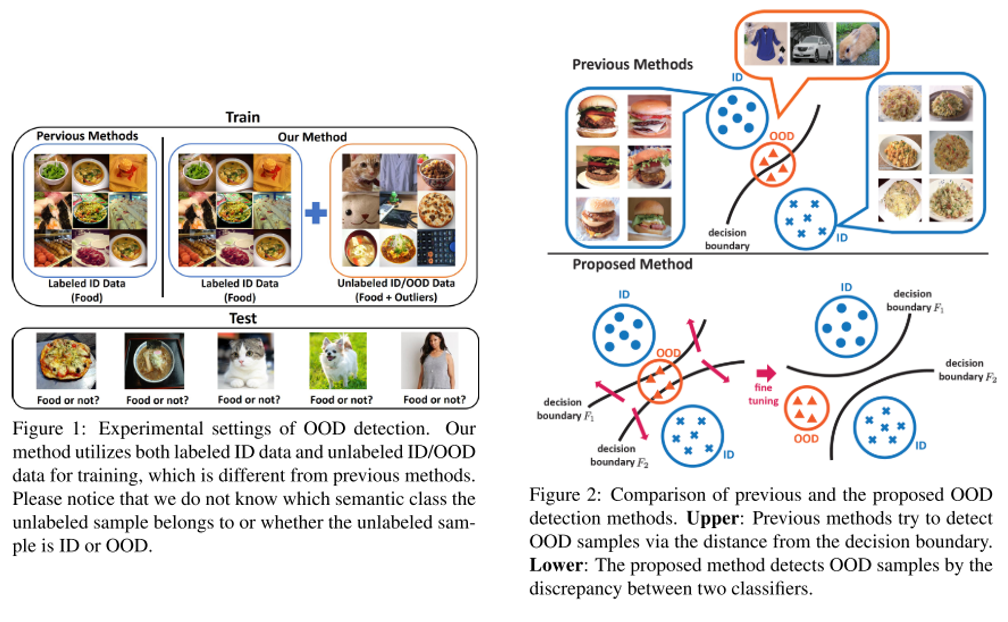
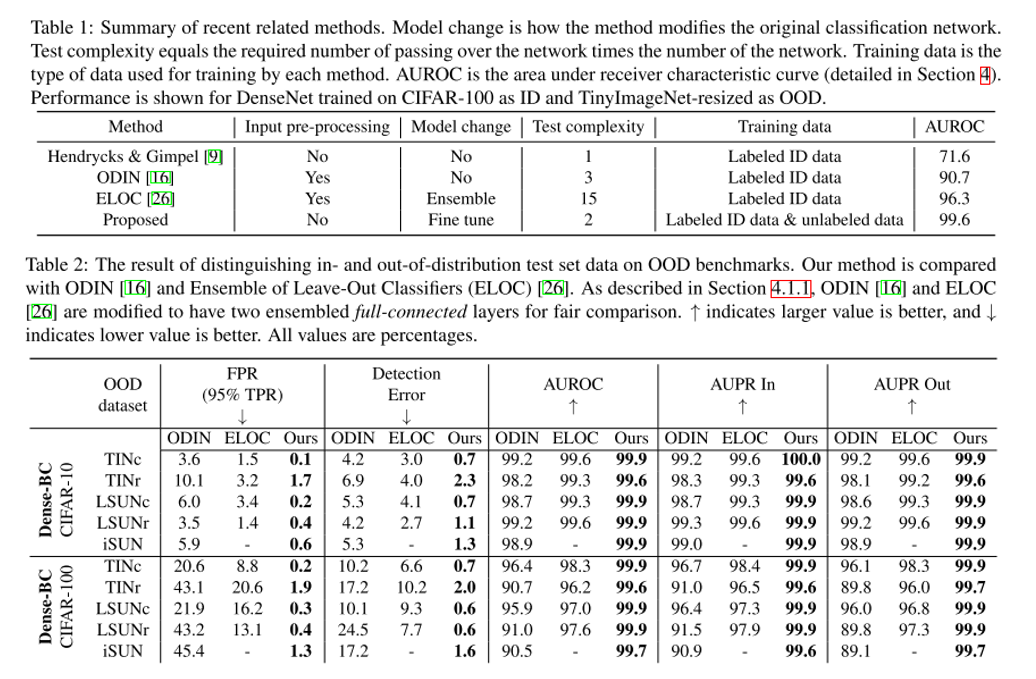
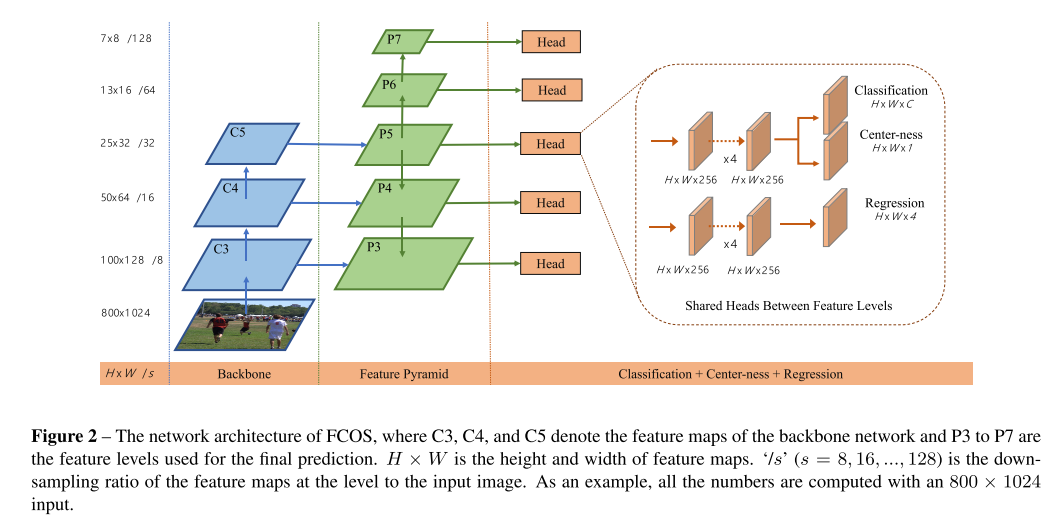
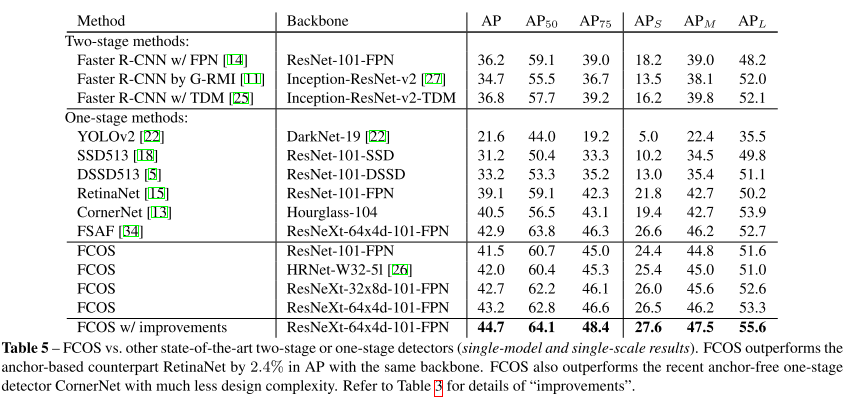
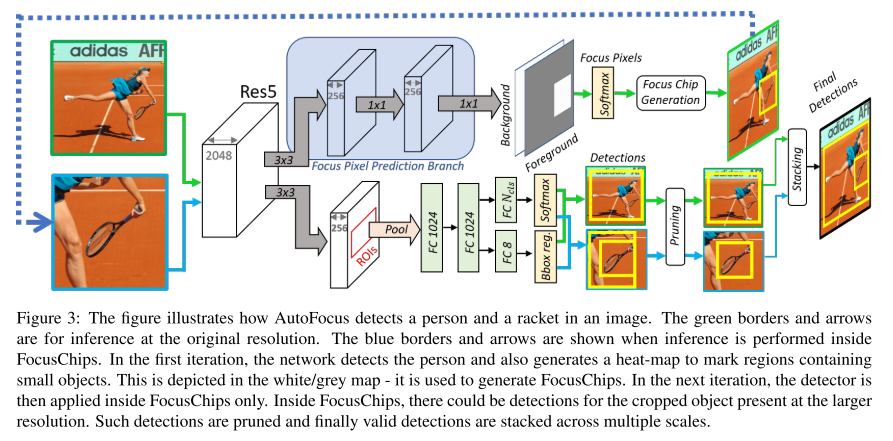
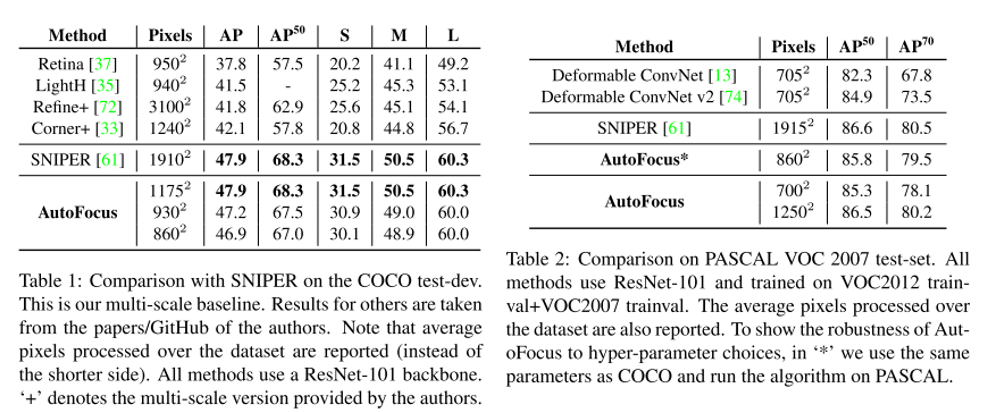
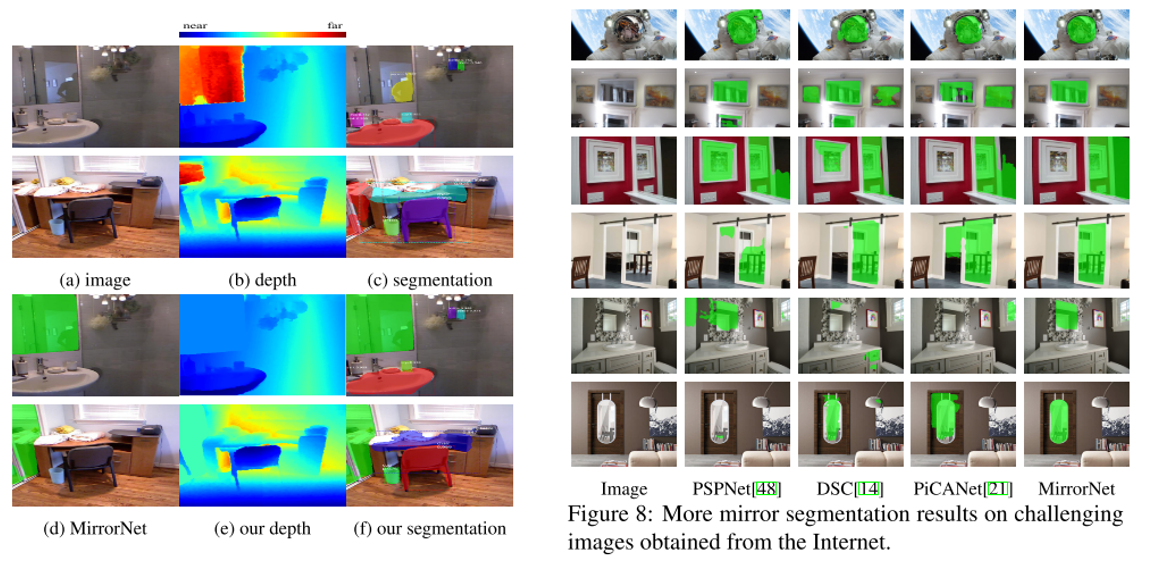
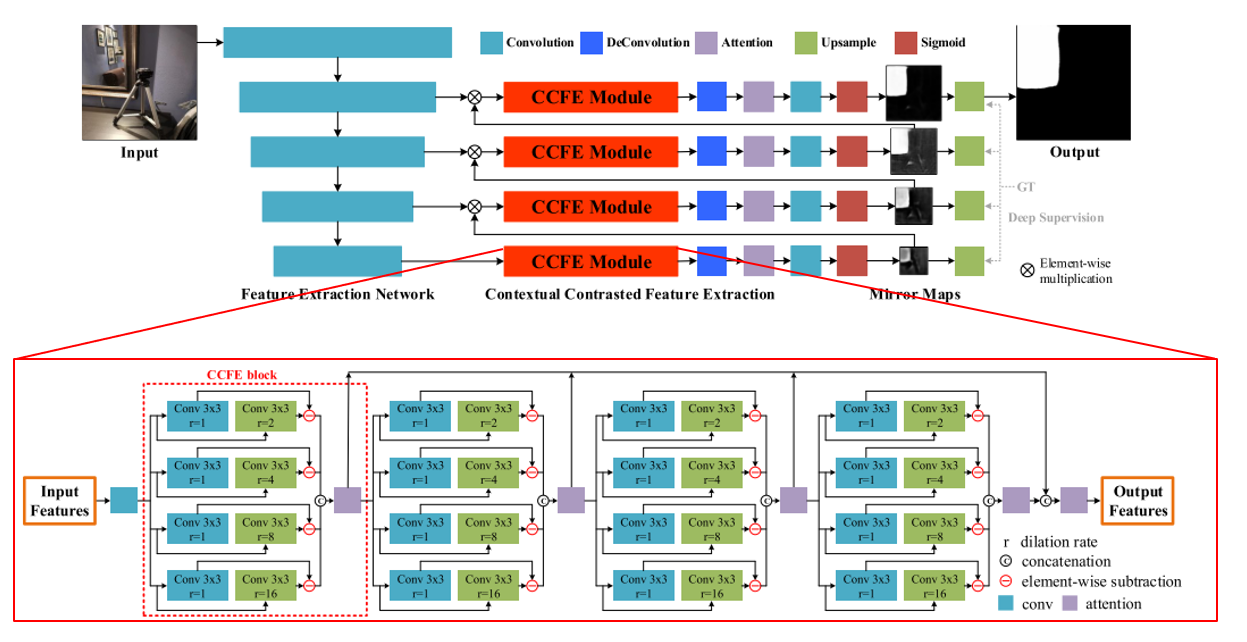
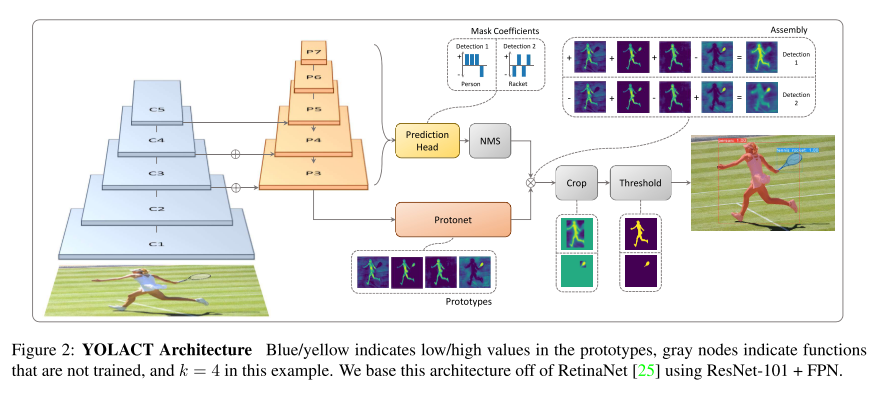
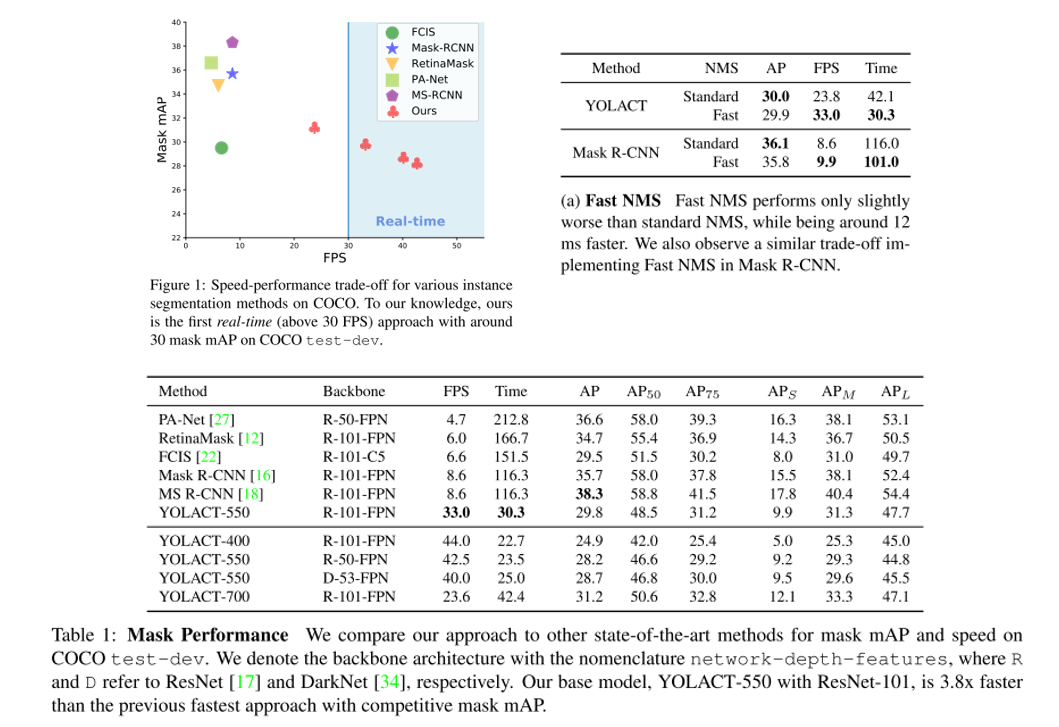
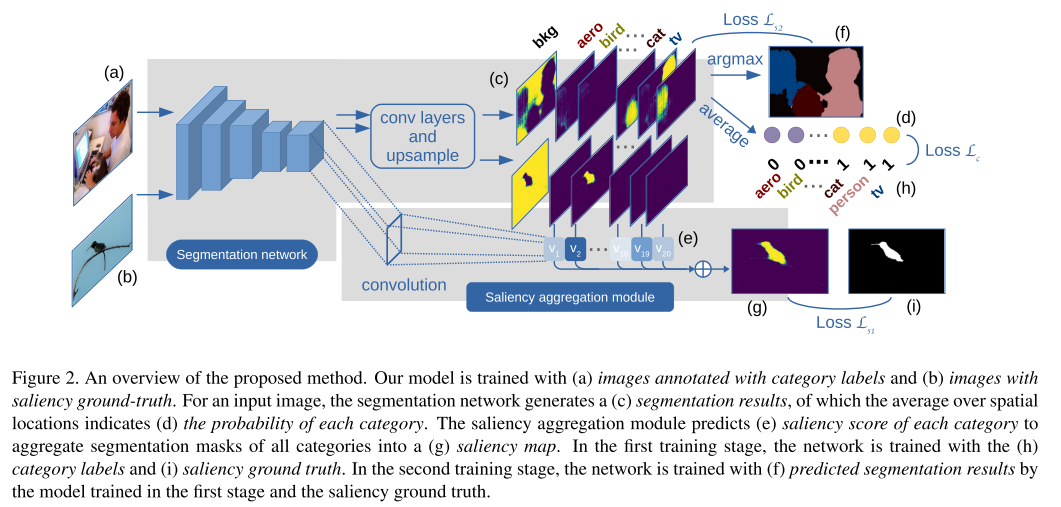
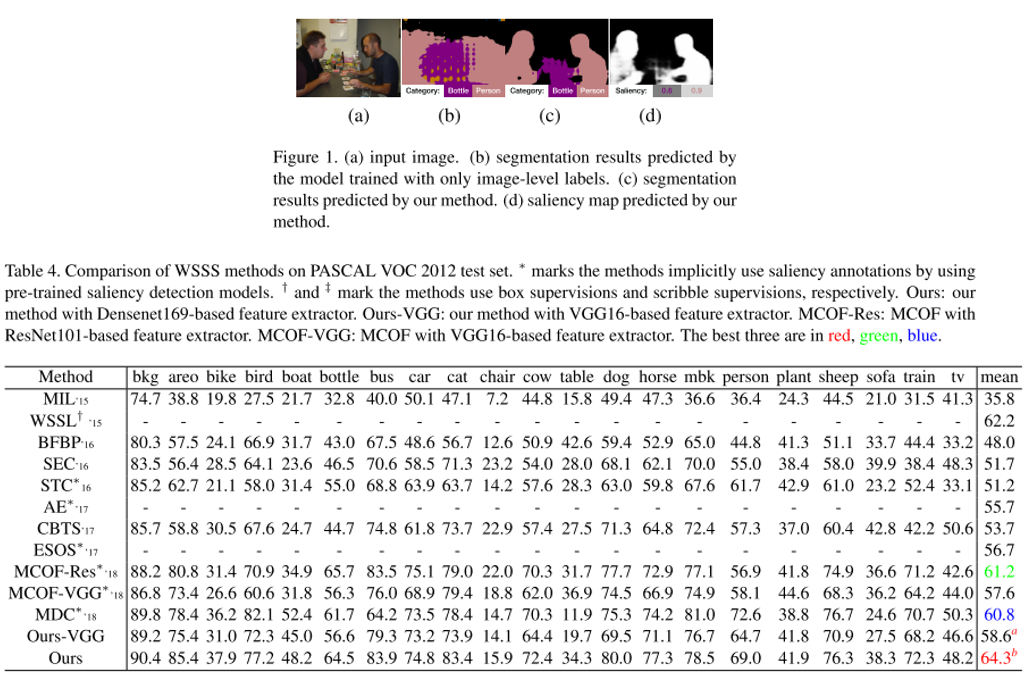
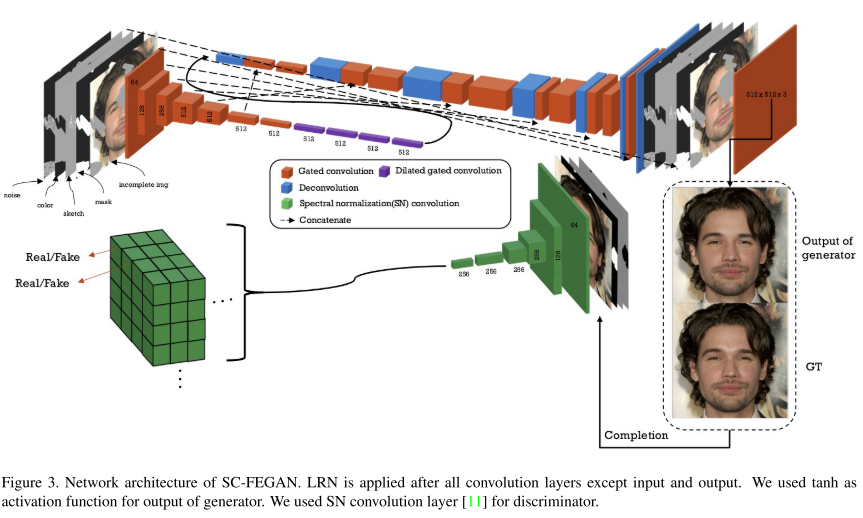

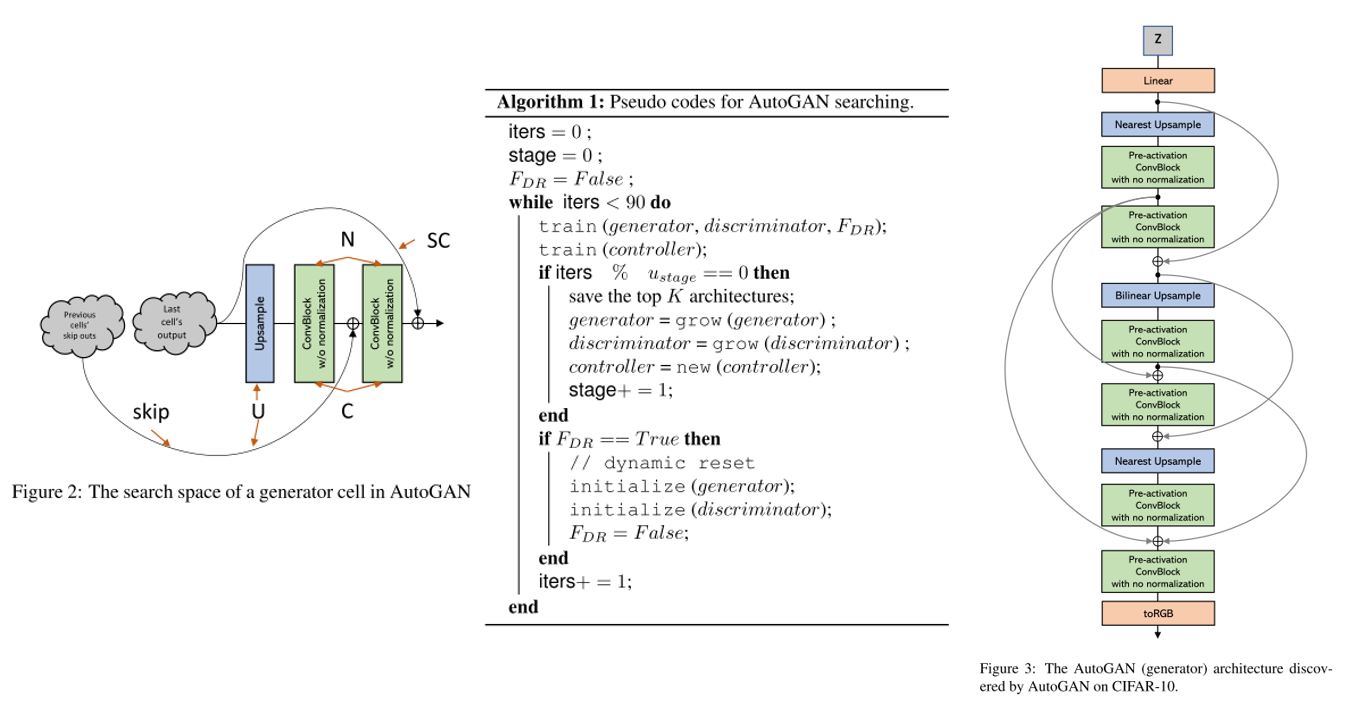
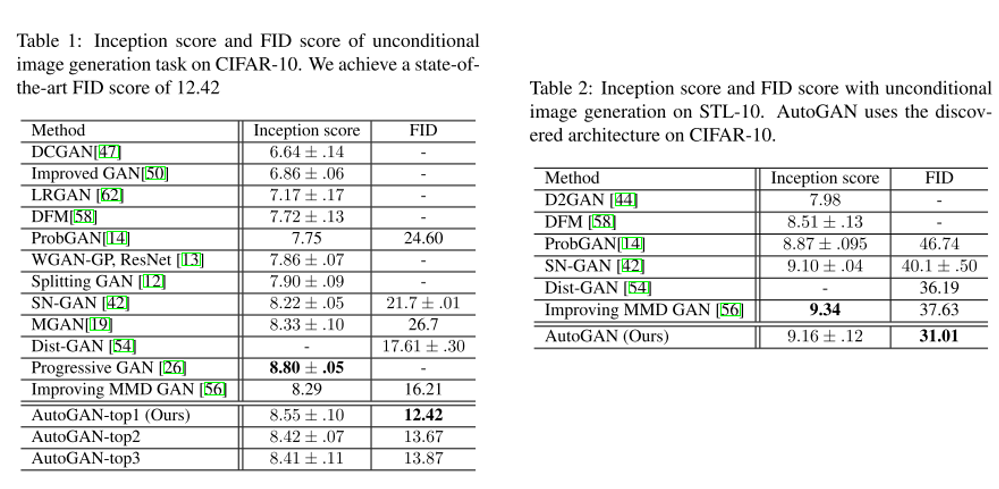
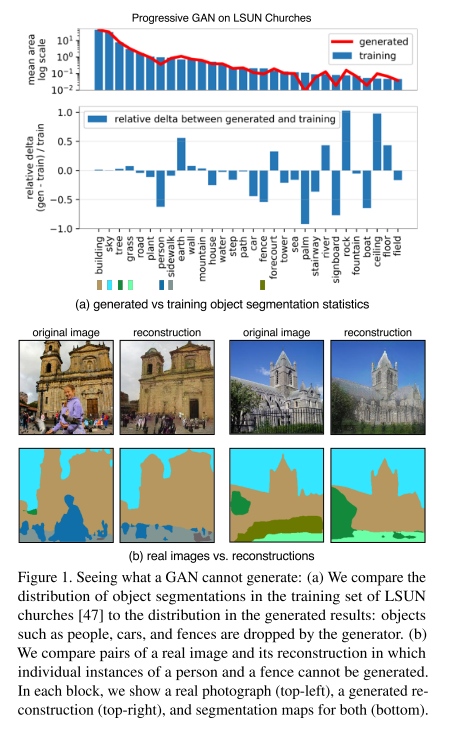

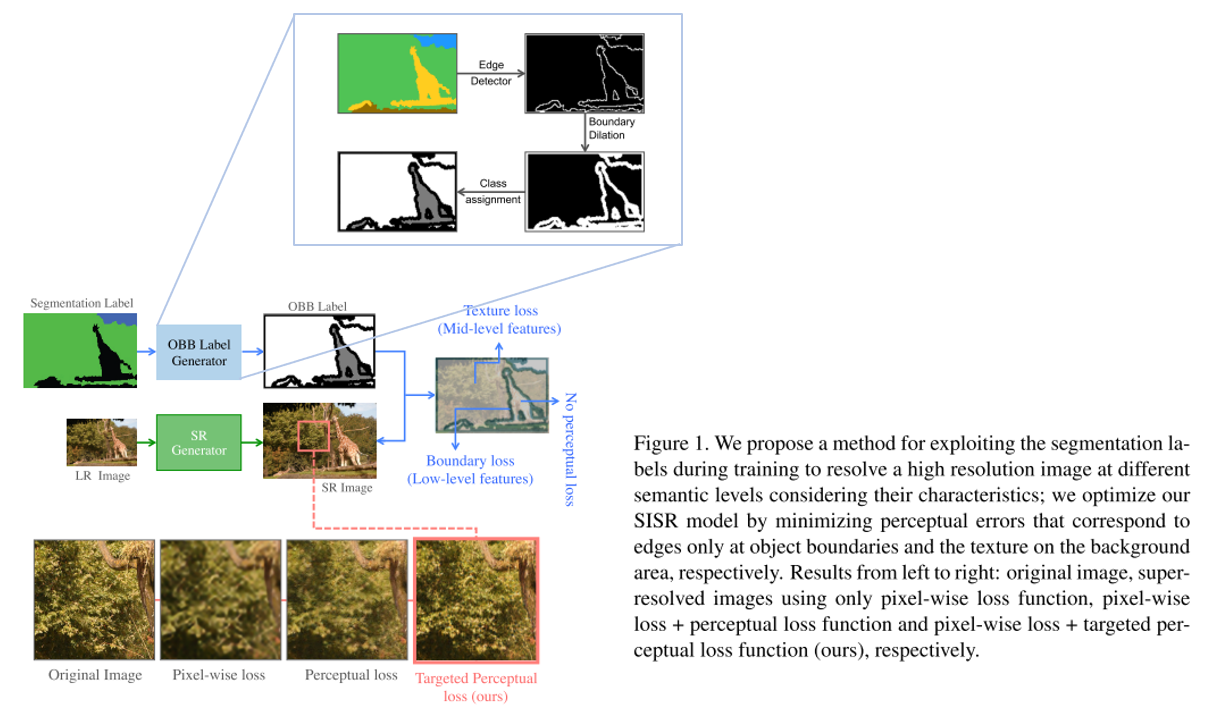
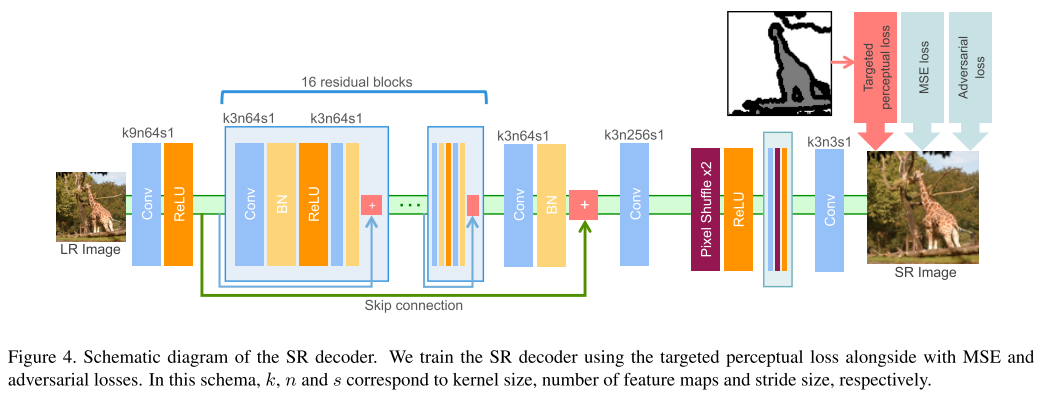
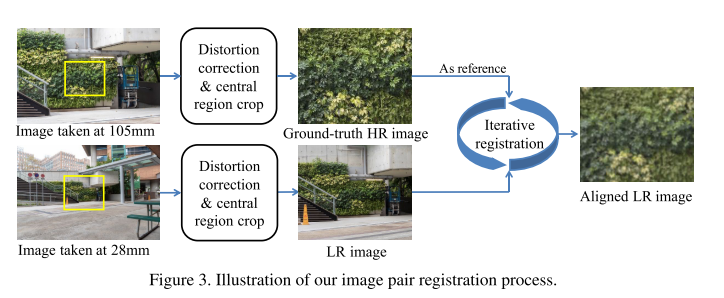
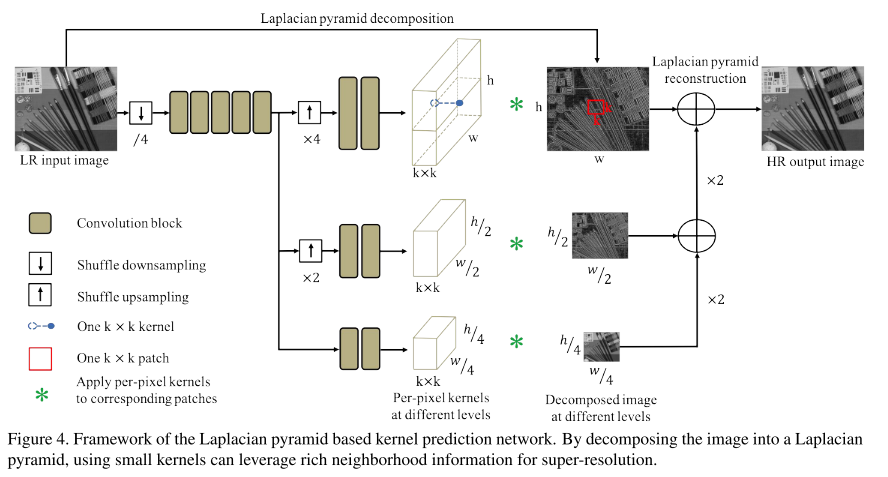

결론
이번 포스팅에서는 ICCV 2019에 대한 분석 및 주요 논문 22편에 대한 간단한 리뷰를 글로 작성해보았습니다.
제가 정리한 논문 외에도 이번 ICCV 2019에는 양질의 논문들이 많이 제출되었으니 관심있으신 분들은 다른 논문들도 읽어 보시는 것을 권장 드리며 이상으로 글을 마치겠습니다. 감사합니다!
https://www.facebook.com/groups/TensorFlowKR/permalink/997362213938170/
Paper: XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
Paper: SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size
Description :
지난 9월 29일 일요일에 Neural Network Quantization & Compact Network Design Study의 4번째 모임이 있었습니다.
이번 스터디에서는 BNN 학습을 Cost Function을 정의하고 최적화하여 접근하는 방식을 소개한 XNOR-Net과 1x1 Conv와 3x3 Conv의 조합을 통해 Network를 Reduction하는 SqueezeNet을 다루었습니다! 두 발표자분 모두 좋은 발표해주셔서 유익한 시간이었습니다 📷

:)
진행한 영상과 자료를 공유드립니다! 📷
즐거운 한 주 되세요! 🤩
https://www.facebook.com/groups/TensorFlowKR/permalink/997406130600445/
TensorFlow Korea 논문읽기모임 PR12 197번째 논문 review입니다
(2기 목표 200편까지 이제 3편이 남았습니다!!)
이번에 제가 발표한 논문은 FAIR(Facebook AI Research)에서 나온 One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers 입니다
한 장의 ticket으로 모든 복권에서 1등을 할 수 있다면 얼마나 좋을까요?
일반적인 network pruning 방법은 pruning 하기 이전에 학습된 network weight를 그대로 사용하면서 fine tuning하는 방법을 사용해왔습니다
pruning한 이후에 network에 weight를 random intialization한 후 학습하면 성능이 잘 나오지 않는 문제가 있었는데요
작년 MIT에서 나온 Lottery ticket hypothesis라는 논문에서는 이렇게 pruning된 이후의 network를 어떻게 random intialization하면 높은 성능을 낼 수 있는지
이 intialization 방법을 공개하며 lottery ticket의 winning ticket이라고 이름붙였습니다.
그런데 이 winning ticket이 혹시 다른 dataset이나 다른 optimizer를 사용하는 경우에도 잘 동작할 수 있을까요?
예를 들어 CIFAR10에서 찾은 winning ticket이 ImageNet에서도 winning ticket의 성능을 나타낼 수 있을까요?
이 논문은 이러한 질문에 대한 답을 실험을 통해서 확인하였고, initialization에 대한 여러가지 insight를 담고 있습니다.
자세한 내용은 발표 영상을 참고해주세요~!
영상링크: https://youtu.be/YmTNpF2OOjA
발표자료링크: https://www.slideshare.net/…/pr197-one-ticket-to-win-them-a…
논문링크: https://arxiv.org/abs/1906.02773
https://www.facebook.com/groups/TensorFlowKR/permalink/997343660606692/
안녕하세요 TF-KR 여러분
이번에는 tflite 및 모바일 딥러닝 관련 질문입니다.
예전에 keras모델(SavedModel)을 tflite 모델로 변환시키는 과정에서 bn(batch normalization)이 전부 빠져서 알아보니 tflite는 bn을 지원하지 않는다는 글을 본적이 있었습니다.
혹시 아직도 tflite는 bn을 지원하지 않는건가요?
그러면 혹시 bn이 포함되어 있는 tensorflow 모델을 안드로이드 혹은 IOS 에서 구동할 수 있는 방법은 없는건가요?
추론시간이 빠르지 않아도 괜찮아서(뭐.. 10초 기다려도 괜찮습니다 ㅠㅠ) 한번 구동하셔 보고 싶어서 자료를 찾는데 보이질 않아 질문합니다.
이승현 tflite에서 batchnorm을 지원하지 않는 것은 제가 사용해보지 않아서 정확하지 않지만
convolutional layer와 batch normalization의 parameter를 합쳐서 하나의 layer로 만들 수 있기 때문인 것 같습니다.
https://www.facebook.com/groups/TensorFlowKR/permalink/997795710561487/
텐서플로우 코리아 님들 안녕하세요!
2017년 8월에 인공지능을 처음 입문하였는데, 어느덧 2년이 지나 학교를 졸업했네요. 잠시 백수 라이프를 즐기고 있는데, 인공지능을 공부하면서 느꼈던 점들과 공부자료들을 공유하고 싶어 이렇게 글을 남깁니다.
1. 주변의 변화
저보다 더 오래되신 분들도 많으시겠지만, 2년 전만 하더라도 주변에 딥러닝을 하는 사람들이 많이 없었습니다. 그런데 요즘에는 기계/ 재료/ 화학 등 여러 학과에서 딥러닝을 많이 하고 있고, 딥러닝/ 데이터 사이언티스트로 취직하기위한 허들도 조금씩 낮아지고 있는 것 같습니다. 당장 저희 학교/ 학과만 보더라도 다들 딥러닝 한다고(작년이랑 올해 캡스톤 디자인 수상한 팀이 다 딥러닝을 사용한 팀이네요 ㅋㅋ)하고 있고, 대학교 마지막 학기인 저의 친형은 재료 물성치를 예측하는 딥러닝 모델을 만드는 데 도와달라고 하네요 ㅋㅋ. 정말 재미있는 현상 같습니다.
2. 수학 vs 코딩
6개월 전까지만 하더라도 저는 수학 파였는데, 요즘은 균형 잡힌 인재가 더 필요한 것 같습니다. 또한, 코딩보다 수학을 위주로 공부하여 취직하고 싶다면 석사 또는 박사의 학력이 필요한 것 같습니다. 이 부분에 대해서 결정을 하기위해서는 사이언티스트로 취업을 할지 엔지니어로 취직을 할지 먼저 결정하는게 좋을 것 같네요. 일반적으로 사이언티스트는 수학을 좀 더 공부하면 좋을 것 같고, 엔지니어는 전산과목을 좀 더 공부하면 좋을 것 같습니다. 인공지능에는 많은 통계/수학적 지식이 필요합니다. 물론 몰라도 코딩은 할 수 있고, 이를 응용하여 사용할 수 있지만, 수학을 모르고는 그 한계가 분명합니다. 반면에 수학을 잘하더라도, 이를 구현하지 못 하면 소용 없음으로, 둘 중에 하나를 정하여 집중하되 다른 한 쪽도 기초는 공부하는게 좋을 것 같네요ㅎ
개인적으로 수학은 선형대수학, 수리통계학, 회귀분석은 수강하는 게 좋다고 생각하며,
전산 과목은(잘 모르지만) 자료구조, 알고리즘, 컴퓨터 구조 정도는 알고 있어야 한다고 생각합니다(물론 제가 다 들었다는 것은 아닙니다. ㅋㅋ)
3. 텐서플로우 VS 파이토치
저는 지금도 텐서플로우를 사용하여 코딩하고 있습니다. 텐서플로우는 빠르고, 오픈 소스가 많다는 장점이 있지만, GPU버전을 설치하기가 힘들며, 병렬처리를 하기 힘들다는 단점을 가지고 있습니다. 반면 파이토치는 병렬처리가 텐서플로우에 비해서는 정말 쉽고 코드를 짜는 것도 편하다는 장점이 있습니다. 개인적으로는 한 라이브러리를 깊이 있게 공부하고, 나머지 다른 라이브러리는 읽을 수 있는 정도만 공부하면 될 것 같습니다.
4. 컴퓨터 비전 vs 자연어 처리 vs 강화학습
아주 예민한 주제인데, 저의 생각은 자신이 하고 싶은 거로 하되 각 분야의 유명 모델 정도는 공부하자 입니다(너무 식상한가요? ㅎ). 여기는 학생분들도 많이 계시니까 취업을 기준으로 먼저 말하면 현재 기준 자연어 처리 > 컴퓨터 비전 > 강화학습 순으로 일자리가 많지만, 각 분야에서 두각을 드러낸다면 이는 문제 될 일이 없는 것 같습니다. GAN은 컴퓨터 비전에서 유명한 모델입니다. 하지만 데이터의 확률분포를 학습하기 위한 방법으로 자연어처리 분야의 음성 합성 부분에서 자주 등장하며, 최근 자연어 처리의 핫 모델 BERT는 컴퓨터 비전의 SELFIE라는 사전학습 방법으로 응용되어 제안되기도 했습니다. 이처럼 자신이 원하는 도메인을 잡아 공부하되, 다른 분야의 핫 모델들도 같이 공부한다면 이를 응용하여 좋은 결과를 낼 수도 있다고 생각합니다.
5. 구현에 관한 생각
우리는 머신러닝 모델을 공부할 때 깃허브에서 “Generative adversarial networks tensorflow”라고 검색하여 나온 코드를 사용하곤 합니다. 하지만 공부를 하면서 느꼈던 것은 가짜 구현이 정말 많다는 것 이였습니다. 실제로 저의 경우, Spectral Normalization GANs의 코드가 필요해 깃허브 스타가 좀 있는 분의 구현을 다운받아서 연구에 사용했습니다. 나중에 안 사실이지만 이는 가짜 구현이었고, FID와 Inception score를 찍어본 결과 논문에서 제시하는 값들에 한 참 못 미치는 결과가 나왔습니다. 이처럼 다른 사람의 코드를 가지고 오거나 직접 코드를 짜서 연구할 때는 철저한 검증 절차가 필수적이라고 생각합니다.
6. 머신러닝 및 딥러닝 강의 목록
최근에는 영어만 잘한다면 들을 수 있는 명강의들이 정말 많습니다. 영어를 잘 못 하는 저는 눈물만 나지만 ㅠㅠ, 주제별로 괜찮다 싶은 강의들을 모아봤습니다.
모두를 위한 딥러닝 시즌 2
(제작해주신 모든 분들 정말 감사합니다. 딥러닝 입문 한국어 강좌들 중 원톱!)
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
머신러닝을 위한 Python 워밍업(한국어)
https://www.edwith.org/aipython
머신러닝을 위한 선형대수(한국어)
https://www.edwith.org/linearalgebra4ai
데이터 구조 및 분석(문일철 교수님)
https://kaist.edwith.org/datastructure-2019s
인공지능 및 기계학습 개론(문일철 교수님)
https://kaist.edwith.org/machinelearning1_17
영상이해를 위한 최적화 기법(김창익 교수님)
https://kaist.edwith.org/optimization2017
<영어>
UC Berkley 인공지능 강좌
https://www.youtube.com/watch?v=Va8WWRfw7Og&list=PLZSO_6-bSqHQHBCoGaObUljoXAyyqhpFW
CS231n
https://www.youtube.com/results?search_query=cs213n
Toronto Machine Learning course
https://www.youtube.com/watch?v=FvAibtlARQ8&list=PL-Mfq5QS-s8iS9XqKuApPE1TSlnZblFHF
CS224N(NLP 강좌)
https://www.youtube.com/playlist?list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z
Deep Learning for Natural Language Processing(Oxford, DeepMind)
https://www.youtube.com/watch?v=RP3tZFcC2e8&list=PL613dYIGMXoZBtZhbyiBqb0QtgK6oJbpm
Advanced Deep Learning, Reinforcement Learning(DeepMind)
https://www.youtube.com/watch?v=iOh7QUZGyiU&list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs&index=1
다들 즐거운 하루되세요 ㅎㅎ!



|
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
