Using [#ComputerVision](https://twitter.com/hashtag/ComputerVision?src=hashtag_click) to control a teddy [#robot](https://twitter.com/hashtag/robot?src=hashtag_click) avatar
This work is in continuous progress and update. We are adding new PWC everyday! Tweet me@fvzaur Usethisthread to request us your favorite conference to be added to our watchlist and to PWC list.
From ICCV 2019: Accurate, robust and fast method for registration of 3D scans
https://www.profillic.com/paper/arxiv:1904.05519
(approach significantly outperforms the state-of-the-art robust 3D registration method based on a line process in terms of both speed and accuracy) https://www.facebook.com/groups/TensorFlowKR/permalink/994510107556714/?sfnsn=mo
This example shows how to use Procrustes analysis to compare two handwritten number threes. Visually and analytically explore the effects of forcing size and reflection changes.
Load and Display the Original Data
Input landmark data for two handwritten number threes.
Use Procrustes analysis to find the transformation that minimizes distances between landmark data points.
[d,Z,tr] = procrustes(X,Y);
The outputs of the function are d (a standardized dissimilarity measure), Z (a matrix of the transformed landmarks), and tr (a structure array of the computed transformation with fields T , b , and c which correspond to the transformation equation).
Visualize the transformed shape, Z , using a dashed blue line.
Use two different numerical values, the dissimilarity measure d and the scaling measure b , to assess the similarity of the target shape and the transformed shape.
The dissimilarity measure d gives a number between 0 and 1 describing the difference between the target shape and the transformed shape. Values near 0 imply more similar shapes, while values near 1 imply dissimilarity.
d
d = 0.1502
The small value of d in this case shows that the two shapes are similar. procrustes calculates d by comparing the sum of squared deviations between the set of points with the sum of squared deviations of the original points from their column means.
The resulting measure d is independent of the scale of the size of the shapes and takes into account only the similarity of landmark data.
Examine the size similarity of the shapes.
tr.b
ans = 0.9291
The sizes of the target and comparison shapes in the previous figure appear similar. This visual impression is reinforced by the value of b = % 0.93, which implies that the best transformation results in shrinking the comparison shape by a factor .93 (only 7%).
Restrict the Form of the Transformations
Explore the effects of manually adjusting the scaling and reflection coefficients.
Force b to equal 1 (set 'Scaling' to false) to examine the amount of dissimilarity in size of the target and transformed figures.
ds = procrustes(X,Y,'Scaling',false)
ds = 0.1552
In this case, setting 'Scaling ' to false increases the calculated value of d only 0.0049, which further supports the similarity in the size of the two number threes. A larger increase in d would have indicated a greater size discrepancy.
This example requires only a rotation, not a reflection, to align the shapes. You can show this by observing that the determinant of the matrix T is 1 in this analysis.
det(tr.T)
ans = 1.0000
If you need a reflection in the transformation, the determinant of T is -1. You can force a reflection into the transformation as follows.
[dr,Zr,trr] = procrustes(X,Y,'Reflection',true); dr
dr = 0.8130
The d value increases dramatically, indicating that a forced reflection leads to a poor transformation of the landmark points. A plot of the transformed shape shows a similar result.
The landmark data points are now further away from their target counterparts. The transformed three is now an undesirable mirror image of the target three.
It appears that the shapes might be better matched if you flipped the transformed shape upside down. Flipping the shapes would make the transformation even worse, however, because the landmark data points would be further away from their target counterparts. From this example, it is clear that manually adjusting the scaling and reflection parameters is generally not optimal.
Read “Distinctive Image Features from Scale-Invariant Keypoints" by D. Lowe 14-SIFT-based object recognition (slides, video 1,2) Images: testSIFTimages.zip
Procrustes shape analysis is a statistical method for analysing the distribution of sets of shapes (see [1]). Let's suppose we pick up a pebble from the beach and want to know how close its shape matches the outline of an frisbee. Here is a plot of the frisbee and the beach pebble.
figure(1);
t=chebfun('x',[0,2*pi]);
f=3*(1.5*cos(t) + 1i*sin(t)); %frisbee
g=exp(1i*pi/3)*(1+cos(t)+1.5i*sin(t)+ .125*(1+1.5i)*sin(3*t).^2); %pebble
plot(f,'r','LineWidth',2), hold on, axis equal, plot(g,'k','LineWidth',2);
title('Frisbee and pebble','FontSize',16); hold off;
Two shapes are equivalent if one can be obtained from the other by translating, scaling and rotating. Before comparison we thus:
1. Translate the shapes so they have mean zero.
2. Scale so the shapes have Root Mean Squared Distance (RMSD) to the origin of one.
3. Rotate to align major axis.
Here is how the frisbee and the pebble compare after each stage.
function [f,g]=ShapeAnalysis(f,g)
% SHAPEANALYSIS(F,G) Plots the parameterised curves before and after% each stage of translating, scaling and aligning. Outputs are% parameterised curves ready for Procustes shape analysis.
LW = 'LineWidth'; FS = 'FontSize';
% Plot orignal
subplot(2,2,1)
plot(f,'r',LW,2), hold on, axis equal, plot(g,'k',LW,2)
title('Orignal',FS,16)
% Translate mean to 0.
f = f-mean(f); g = g-mean(g);
subplot(2,2,2)
plot(f,'r',LW,2), hold on, axis equal, plot(g,'k',LW,2)
title('After translation',FS,16)
% Scale so RMSD is 1.
f = f/norm(f); g = g/norm(g);
subplot(2,2,3)
plot(f,'r',LW,2), hold on, axis equal, plot(g,'k',LW,2)
title('After scaling',FS,16)
% Align major axis.
subplot(2,2,4)
% Find argument of major axis.
[~,fxmax]=max(abs(f)); [~,gxmax]=max(abs(g));
rotf=angle(f(fxmax)); rotg=angle(g(gxmax));
% Rotate both so major axis lies on the +ve real axis.
x = chebfun('x',[0,2*pi]);
f = exp(-1i*rotf)*f(mod(x+fxmax,2*pi));
g = exp(-1i*rotg)*g(mod(x+gxmax,2*pi));
plot(f,'r',LW,2), hold on, axis equal, plot(g,'k',LW,2)
title('After aligning',FS,16), hold offend
[f,g] = ShapeAnalysis(f,g);
To calculate the Procrustes distance we would measure the error between the two shapes at a finite number of reference points and compute the vector 2-norm. In this discrete case In Chebfun we calculate the continuous analogue:
norm(f-g)
ans =
0.072347575424997
A little warning
In the discrete version of Procrustes shape analysis statisticians choose reference points on the two shapes (to compare). They then work out the difference between corresponding reference points. The error computed depends on this correspondence. A different correspondence gives a different error. In the continuous case this correspondence becomes the parameterisation. A different parameterisation of the two curves gives a different error. This continuous version of Procrustes (as implemented in this example) is therefore more of an 'eye-ball' check than a robust statistical analysis.
A shape and its reflection
At the beach shapes reflect on the surface of the sea. An interesting question is: How close, in shape, is a pebble to its reflection? Here is a plot of a pebble and its reflection.
figure(2)
% pebble
f = exp(1i*pi/3)*(1+cos(t)+1.5i*sin(t)+.125*(1+1.5i)*sin(3*t).^2);
% reflection
g = exp(-1i*pi/3)*(1+cos(2*pi-t)-1.5i*sin(2*pi-t)+.125*(1-1.5i)*sin(3*(2*pi-t)).^2);
plot(f,'r','LineWidth',2), hold on, axis equal, plot(g,'k','LineWidth',2)
title('Pebble and its reflection','FontSize',16), hold off
Here is how the pebble and its reflection compare after each stage of translating, scaling and rotating.
[f,g]=ShapeAnalysis(f,g);
Now we calculate the continuous Procrustes distance.
norm(f-g)
ans =
0.097593759012228
Comparing this result to the Procrustes distance of the pebble and a frisbee shows that the pebble is closer in shape to a frisbee than its own reflection!
The sensitivity and specificity of a diagnostic test depends on more than just the "quality" of the test--they also depend on the definition of what constitutes an abnormal test. Look at the the idealized graph at right showing the number of patients with and without a disease arranged according to the value of a diagnostic test. This distributions overlap--the test (like most) does not distinguish normal from disease with 100% accuracy. The area of overlap indicates where the test cannot distinguish normal from disease. In practice, we choose a cutpoint (indicated by the vertical black line) above which we consider the test to be abnormal and below which we consider the test to be normal. The position of the cutpoint will determine the number of true positive, true negatives, false positives and false negatives. We may wish to use different cutpoints for different clinical situations if we wish to minimize one of the erroneous types of test results.
We can use the hypothyroidism data from the likelihood ratio section to illustrate how sensitivity and specificity change depending on the choice of T4 level that defines hypothyroidism. Recall the data on patients with suspected hypothyroidism reported by Goldstein and Mushlin (J Gen Intern Med 1987;2:20-24.). The data on T4 values in hypothyroid and euthyroid patients are shown graphically (below left) and in a simplified tabular form (below right).
T4 value
Hypothyroid
Euthyroid
5 or less
18
1
5.1 - 7
7
17
7.1 - 9
4
36
9 or more
3
39
Totals:
32
93
Suppose that patients with T4 values of 5 or less are considered to be hypothyroid. The data display then reduces to:
T4 value
Hypothyroid
Euthyroid
5 or less
18
1
> 5
14
92
Totals:
32
93
You should be able to verify that the sensivity is 0.56 and the specificity is 0.99.
Now, suppose we decide to make the definition of hypothyroidism less stringent and now consider patients with T4 values of 7 or less to be hypothyroid. The data display will now look like this:
T4 value
Hypothyroid
Euthyroid
7 or less
25
18
> 7
7
75
Totals:
32
93
You should be able to verify that the sensivity is 0.78 and the specificity is 0.81.
Lets move the cut point for hypothyroidism one more time:
T4 value
Hypothyroid
Euthyroid
< 9
29
54
9 or more
3
39
Totals:
32
93
You should be able to verify that the sensivity is 0.91 and the specificity is 0.42.
Now, take the sensitivity and specificity values above and put them into a table:
Cutpoint
Sensitivity
Specificity
5
0.56
0.99
7
0.78
0.81
9
0.91
0.42
Notice that you can improve the sensitivity by moving to cutpoint to a higher T4 value--that is, you can make the criterion for a positive test less strict. You can improve the specificity by moving the cutpoint to a lower T4 value--that is, you can make the criterion for a positive test more strict. Thus, there is a tradeoff between sensitivity and specificity. You can change the definition of a positive test to improve one but the other will decline.
The next section covers how to use the numbers we just calculated to draw and interpret an ROC curve. .
This section continues the hypothyroidism example started in the the previous section. We showed that the table at left can be summarized by the operating characteristics at right:
T4 value
Hypothyroid
Euthyroid
5 or less
18
1
5.1 - 7
7
17
7.1 - 9
4
36
9 or more
3
39
Totals:
32
93
Cutpoint
Sensitivity
Specificity
5
0.56
0.99
7
0.78
0.81
9
0.91
0.42
The operating characteristics (above right) can be reformulated slightly and then presented graphically as shown below to the right:
Cutpoint
True Positives
False Positives
5
0.56
0.01
7
0.78
0.19
9
0.91
0.58
This type of graph is called a Receiver Operating Characteristic curve (or ROC curve.) It is a plot of the true positive rate against the false positive rate for the different possible cutpoints of a diagnostic test.
An ROC curve demonstrates several things:
It shows the tradeoff between sensitivity and specificity (any increase in sensitivity will be accompanied by a decrease in specificity).
The closer the curve follows the left-hand border and then the top border of the ROC space, the more accurate the test.
The closer the curve comes to the 45-degree diagonal of the ROC space, the less accurate the test.
The slope of the tangent line at a cutpoint gives the likelihood ratio (LR) for that value of the test. You can check this out on the graph above. Recall that the LR for T4 < 5 is 52. This corresponds to the far left, steep portion of the curve. The LR for T4 > 9 is 0.2. This corresponds to the far right, nearly horizontal portion of the curve.
The area under the curve is a measure of text accuracy. This is discussed further in the next section.
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár, Microsoft COCO: Common Objects in Context, ECCV, 2014.
당신이 그림을 공부할 때, 그것에 대해 여러 가지 추측을 할 수있는 기회가 있습니다. 예를 들어 주제를 이해하는 것 외에도 기간, 스타일 및 아티스트별로 분류 할 수 있습니다. 컴퓨터 알고리즘은 사람처럼 쉽게 분류 작업을 수행 할 수있을 정도로 그림을 "이해"할 수 있습니까?
Rutgers 대학의 Art and Art Intelligence Laboratory의 동료들과 저는 MATLAB®, Statistics and Machine Learning Toolbox ™ 및 지난 6 세기의 수천 점의 그림 데이터베이스를 사용하여이 문제를 탐구했습니다. 우리는 또한 AI 알고리즘의 기능과 한계에 관한 흥미로운 두 가지 질문을 제기했습니다. 즉, 어떤 그림이 최신 아티스트에게 가장 큰 영향을 미치는지, 그리고 시각적 기능 만 사용하여 그림의 창의성을 측정 할 수 있는지 여부입니다.
그림 분류를위한 시각적 특징 추출하기
우리는 스타일 (예 : 입체파, 인상파, 추상 표현주의 또는 바로크), 장르 (예 : 풍경, 인물 또는 정물) 및 아티스트와 같이 대규모 그룹의 그림을 스타일별로 분류 할 수있는 알고리즘을 개발하고자했습니다. 이 분류에 대한 요구 사항 중 하나는 색상, 구성, 질감, 원근감, 주제 및 기타 시각적 기능을 인식하는 것입니다. 두 번째는 그림 간의 유사성을 가장 잘 나타내는 시각적 기능을 선택하는 기능입니다.
MATLAB 및 Image Processing Toolbox ™를 사용하여 페인팅의 시각적 기능을 추출하는 알고리즘을 개발했습니다. 특징 추출 알고리즘은 컴퓨터 비전에서 매우 일반적이며 구현하기 쉽습니다. 더 어려운 작업은 최고의 기계 학습 기술을 찾는 것이 었습니다. 우리는 통계 및 Machine Learning Toolbox에서 SVM (Support Vector Machine) 및 기타 분류 알고리즘을 테스트하여 스타일 분류에 유용한 시각적 기능을 식별하는 것으로 시작했습니다. MATLAB에서 우리는 거리 메트릭 학습 기법을 적용하여 특징을 평가하고 알고리즘의 그림 분류 능력을 향상 시켰습니다.
우리가 개발 한 알고리즘은 우리 데이터베이스의 회화 스타일을 60 %의 정확도로 분류했으며, 우연한 결과는 약 2 %였습니다. 예술 사학자는 60 % 이상의 정확성으로이 작업을 수행 할 수 있지만, 알고리즘은 일반적인 비전문가보다 뛰어나다.
예술적 영향을 밝히기 위해 기계 학습 사용
한 쌍의 그림들 사이의 유사점을 확실하게 식별 할 수있는 알고리즘을 갖추었을 때, 우리는 다음 과제를 해결할 준비가되었습니다. 기계 학습을 사용하여 예술적 영향을 나타냅니다. 우리의 가설은 스타일 분류 (감독 학습 문제)에 유용한 시각적 인 특징이 또한 영향 (감독되지 않은 문제)을 결정하는 데 사용될 수 있다는 것이었다.
예술 사학자들은 예술가들이 동시대 사람들과 함께 일하고, 여행했거나, 훈련 받았던 방식을 토대로 예술적 영향 이론을 개발합니다. MATLAB 기반 기계 학습 알고리즘은 시각적 요소와 구성 날짜 만 사용했습니다. 우리는 그림에서 물체와 기호를 고려한 알고리즘이 색상이나 질감과 같은 저수준 기능에 의존하는 알고리즘보다 효과적 일 것이라고 가정했습니다. 이를 염두에두고 Google은 특정 이미지를 식별하기 위해 Google 이미지에서 학습 한 분류 알고리즘을 사용했습니다.
우리는 550 년의 기간에 걸쳐 작업 한 66 명의 다른 아티스트의 1700 개 이상의 그림에 대한 알고리즘을 테스트했습니다. 이 알고리즘은 Diego Velazquez의 "Portrait of Pope Innocent X"가 Francis Bacon의 "Velazquez의 Portrait of Pope Innocent X"(그림 1)에 미치는 영향을 쉽게 확인했습니다.
그림 1. 왼쪽 : Diego Velázquez의 "Portrait of Pope innocent X."오른쪽 : Francis Bacon의 "Velázquez의 초상화 이후의 연구"
이 두 그림 사이의 구성과 주제의 유사점은 평신도가 쉽게 발견 할 수 있지만 알고리즘은 또한 우리가 함께 작업 한 예술 사학자를 놀라게 한 결과를 만들어 냈습니다. 예를 들어, 우리의 알고리즘은 "Bazille 's Studio; 9 rue de la Condamine ", 1870 년 프랑스 인상파 Frederic Bazille에 의해 그려진 Norman Rockwell의"Shuffleton 's Barbershop "에 대한 영향력으로 80 년 후에 완성되었습니다 (그림 2). 한눈에 보면 그림이 비슷하지는 않겠지 만, 각 작품의 오른쪽 하단에있는 히터, 가운데에있는 세 사람의 그룹, 실내에있는 의자와 삼각형 공간을 포함하여 구성과 주제의 유사점을 자세히 살펴볼 수 있습니다. 왼쪽 아래.
Rutgers_fig2_w.jpg 그림 2. 왼쪽 : Frederic Bazille의 "Bazille 's Studio; 9 rue de la Condamine "오른쪽 : Norman Rockwell의"Shuffleton 's Barbershop "노란색 원은 비슷한 물체를 나타내고 빨간색 선은 비슷한 구성을 나타내고 파란색 직사각형은 비슷한 구조 요소를 나타냅니다.
우리의 데이터 세트에서, 알고리즘은 예술 사학자가 인정한 55 가지 영향의 60 %를 정확하게 식별하여, 시각적 유사성만으로 많은 영향을 결정할 수있는 충분한 정보를 알고리즘에 제공합니다.
네트워크 중심성 문제를 해결함으로써 창의성 측정
최근 우리의 연구는 예술의 창의성을 측정하는 알고리즘 개발에 중점을두고 있습니다. 우리는이 프로젝트가 광범위하고 사용되는 정의에 기반을 두었습니다.이 정의는 객체가 새롭고 영향력있는 것이라면 창의적이라고 식별합니다. 이 점에서, 창조적 인 그림은 그 전에 (소설적인) 그림과 다르지만 그 뒤에 오는 그림 (유력한 것)과 유사합니다.
이 문제를 해결하기 위해 우리는 그림 사이의 유사점을 식별하기 위해 MATLAB 알고리즘을 적용 할 수있는 기회를 다시 한번 보았습니다. MATLAB에서 정점이 그림이고 각 모서리가 정점에서 두 그림 간의 유사성을 나타내는 네트워크를 만들었습니다. 이 네트워크의 일련의 변형을 통해 우리는 그러한 그래프에서 창의성에 대한 추론이 네트워크 중심성 문제이며 MATLAB을 사용하여 효율적으로 해결할 수 있음을 확인했습니다.
우리는 62,000 개 이상의 그림이 포함 된 두 가지 데이터 세트에서 창의성 알고리즘을 테스트했습니다. 이 알고리즘은 그림 3에 나와있는 작품 중 일부를 포함하여 미술 사학자들이 소설과 영향력으로 인정한 여러 작품에 높은 점수를주었습니다. 파블로 피카소의 "젊은 아가씨들"(1907)보다 높은 순위는 같은 기간에 여러 그림 Kazimir Malevich. Malevich의 작업에 대해 거의 알지 못했기 때문에이 결과는 처음에는 놀랐습니다. 나는 그가 추상적 예술의 가장 초기 발전 중 하나 인 Suprematism 운동의 창시자라는 것을 그 후 배웠다.
Rutgers_fig3_w.jpg 그림 3. 1400에서 2000 (x 축)까지의 회화에 대한 계산 된 창의성 점수 (y 축). 개별 기간 동안 가장 높은 점수를받은 그림을 보여줍니다.
알고리즘의 기본 검증을 수행하기 위해 특정 미술 작품의 날짜를 변경하여 효과적으로 시간을 앞뒤로 이동했습니다. 이 "타임 머신"실험에서 우리는 인상주의 미술이 1600 년대로 되돌아 가면서 상당한 창의성 점수 증가를 보았고 바로크 그림의 경우 상당한 감소가 1900 년대로 나아갔습니다. 알고리즘은 300 년 전에 창조적이었던 것이 오늘날 창조적이지 않다는 것을 정확하게 인식했으며, 과거에 도입 된 경우 창조적 인 무언가가 훨씬 창조적이었을 것입니다.
예술 분야의 지속적인 연구를위한 확장 가능하고 확장 가능한 프레임 워크
인간은 예술을 분류 할 수있는 선천적 인 지각 기술을 가지고 있으며 그림 쌍의 유사성을 식별하는 데 탁월하지만 수천 또는 수백만 개의 그림에 객관적으로 이러한 기술을 적용 할 시간과 인내가 없습니다. 이 규모에서 작업을 처리하는 것은 컴퓨터가 자체적으로 들어오는 곳입니다. 인간과 유사한 지각 능력을 가진 기계 학습 알고리즘을 개발함으로써, 우리의 목표는 예술 역사가에게 방대한 이미지 데이터베이스를 탐색 할 수있는 도구를 제공하는 것입니다.
유사점을 확인하고 창의성을 측정하기 위해 MATLAB에서 개발 한 프레임 워크는 예술에 국한되지 않습니다. 개별 저작물을 알고리즘에 액세스 할 수있는 방식으로 인코딩 할 수있는 한 문학, 음악 또는 거의 모든 다른 창의적 도메인에 적용 할 수 있습니다.
그러나 지금은 시각 예술에 중점을두고 있습니다. 우리는 기계 학습 알고리즘이 좋은 결과를 가져올뿐만 아니라 그러한 결과에 어떻게 도달하는지에 관심을 가지고 있습니다. 이 영역에서도 MATLAB은 결과를 쉽고 빠르게 시각화 할 수있는 많은 방법을 제공하므로 엄청난 이점입니다. 이러한 시각화를 통해 우리는 결과를 이해하고 진행중인 인공 지능 연구에이를 알릴 수 있습니다.
Creating Computer Vision and Machine Learning Algorithms That Can Analyze Works of Art
By Ahmed Elgammal, Rutgers University
When you study a painting, chances are that you can make several inferences about it. In addition to understanding the subject matter, for example, you may be able to classify it by period, style, and artist. Could a computer algorithm “understand” a painting well enough to perform these classification tasks as easily as a human being?
My colleagues and I at the Art and Artificial Intelligence Laboratory at Rutgers University explored this question using MATLAB®, Statistics and Machine Learning Toolbox™, and a database of thousands of paintings from the past six centuries. We also addressed two other intriguing questions about the capabilities and limitations of AI algorithms: whether they can identify which paintings have had the greatest influence on later artists, and whether they can measure a painting’s creativity using only its visual features.
Extracting Visual Features for Classifying Paintings
We wanted to develop algorithms capable of classifying large groups of paintings by style (for example, as Cubist, Impressionist, Abstract Expressionist, or Baroque), genre (for example, landscape, portrait, or still life), and artist. One requirement for this classification is the ability to recognize color, composition, texture, perspective, subject matter, and other visual features. A second is the ability to select those visual features that best indicate similarities between paintings.
Working with MATLAB and Image Processing Toolbox™, we developed algorithms to extract the visual features of a painting. The feature extraction algorithm is fairly common in computer vision, and straightforward to implement. The more challenging task was finding the best machine learning techniques. We began by testing support vector machines (SVMs) and other classification algorithms in Statistics and Machine Learning Toolbox to identify visual features that are useful in style classification. In MATLAB, we then applied distance metric learning techniques to weigh the features and thereby improve the algorithm’s ability to classify paintings.
The algorithms we developed classified the styles of paintings in our database with 60% accuracy, where chance performance would have been about 2%. While art historians can perform this task with much more than 60% accuracy, the algorithm outperforms typical non-expert humans.
Using Machine Learning to Uncover Artistic Influences
Once we had algorithms that could reliably identify similarities between pairs of paintings, we were ready to tackle our next challenge: using machine learning to reveal artistic influences. Our hypothesis was that visual features useful for style classification (a supervised learning problem) could also be used to determine influences (an unsupervised problem).
Art historians develop theories of artistic influence based on how the artists worked, traveled, or trained with contemporaries. Our MATLAB based machine learning algorithms used only visual elements and dates of composition. We hypothesized that an algorithm that took into account objects and symbols in the painting would be more effective than one that relied on low-level features such as color and texture. With this in mind, we used classification algorithms that were trained on Google images to identify specific objects.
We tested the algorithms on more than 1700 paintings from 66 different artists working over a span of 550 years. The algorithm readily identified the influence of Diego Velazquez's “Portrait of Pope Innocent X” on Francis Bacon's “Study After Velazquez's Portrait of Pope Innocent X” (Figure 1).
Figure 1. Left: Diego Velázquez’s “Portrait of Pope Innocent X.” Right: Francis Bacon’s “Study After Velázquez’s Portrait of Pope Innocent X.”
The similarities in composition and subject matter between these two paintings are easy even for a layman to spot, but the algorithm also produced results that surprised the art historians we worked with. For example, our algorithm identified “Bazille’s Studio; 9 rue de la Condamine,” painted by French Impressionist Frederic Bazille in 1870, as a possible influence on Norman Rockwell’s “Shuffleton’s Barbershop,” completed 80 years later (Figure 2). Although the paintings might not look similar at first glance, a closer examination reveals similarities in composition and subject matter, including the heaters in the lower right of each work, the group of three men in the center, and the chairs and triangular spaces in the lower left.
Figure 2. Left: Frederic Bazille’s “Bazille’s Studio; 9 rue de la Condamine.” Right: Norman Rockwell’s “Shuffleton’s Barbershop.” Yellow circles indicate similar objects, red lines indicate similar composition, and the blue rectangle indicates a similar structural element.
In our data set, the algorithms correctly identified 60% of the 55 influences recognized by art historians, suggesting that visual similarity alone provides sufficient information for algorithms (and possibly for humans) to determine many influences.
Measuring Creativity by Solving a Network Centrality Problem
Recently, our research has focused on developing algorithms to measure creativity in art. We based this project on a widely used definition that identifies an object as creative if it is both novel and influential. In these terms, a creative painting will be unlike the paintings that came before it (novel), but similar to those that came after it (influential).
In addressing this problem, we once again saw an opportunity to apply our MATLAB algorithms for identifying similarities between paintings. In MATLAB, we created a network in which the vertices are paintings and each edge represents the similarity between the two paintings at its vertices. Through a series of transformations on this network we saw that making inferences about creativity from such a graph is a network centrality problem, which can be solved efficiently using MATLAB.
We tested our creativity algorithms on two data sets containing more than 62,000 paintings. The algorithm gave high scores to several works recognized by art historians as both novel and influential, including some of the works shown in Figure 3. Ranking even higher than Pablo Picasso’s “Young Ladies of Avignon” (1907) in the same period were several paintings by Kazimir Malevich. This result initially surprised me, as I knew little about Malevich’s work. I have since learned that he was the founder of the Suprematism movement, one of the earliest developments in abstract art.
Figure 3. Computed creativity scores (y-axis) for paintings from 1400 to 2000 (x-axis), showing selected highest-scoring paintings for individual periods.
To perform a basic validation of our algorithm, we changed the date on specific works of art, effectively shifting them backwards or forwards in time. In these “time machine” experiments, we saw significant creativity score increases for Impressionist art moved back to the 1600s and significant reductions for Baroque paintings moved forward to the 1900s. The algorithms correctly perceived that what was creative 300 years ago is not creative today, and that something that is creative now would have been much more creative if introduced far in the past.
A Scalable and Extensible Framework for Ongoing Research in the Arts
Humans have the innate perceptual skills to classify art, and they excel at identifying similarities in pairs of paintings, but they lack the time and patience to apply these skills objectively to thousands or millions of paintings. Handling tasks at this scale is where computers come into their own. By developing machine learning algorithms that have perceptual capabilities similar to humans, our goal is to provide art historians with tools to navigate vast databases of images.
The framework we developed in MATLAB for identifying similarities and measuring creativity is not confined to art. It could be applied to literature, music, or virtually any other creative domain, as long as the individual works can be encoded in a way that is accessible to the algorithms.
For now, however, our focus remains on the visual arts. We are interested not only in ensuring that machine learning algorithms produce good results but also in how they arrive at those results. In this area, too, MATLAB is a tremendous advantage because it provides many ways to quickly and easily visualize results. These visualizations enable us to understand the results and use them to inform ongoing AI research.
Dr. Ahmed Elgammal is an associate professor in the department of computer science at Rutgers, the State University of New Jersey. His research interests include computer vision, visual learning, data science, digital humanities, and human motion analysis.
%Example t=0:0.01:10 y=sin(t) plot(t,y) %------------------------- dy=diff(y)./diff(t) k=220; % point number 220 tang=(t-t(k))*dy(k)+y(k) hold on plot(t,tang) scatter(t(k),y(k)) hold off
gradient(y,t) is better than diff(y)/diff(t), because it applies a 2nd order method. At least this is true for numerical differentiation. Does this concern symbolic operations also? I cannot test this, because I do not have the symbolic toolbox.
You could use the matlab's built in function to get the cosine distance:
pdist([u;v],'cosine')
which returns the "One minus the cosine of the included angle between points". You could then subtract the answer from one to get the 'cosine of the included angle' (similarity), like this:
Iris Recognition Algorithms Comparison between Daugman algorithm and Hough transform on Matlab.
DESCRIPTION:
Iris is one of the most important biometric approaches that can perform high confidence recognition. Iris contains rich and random Information. Most of commercial iris recognition systems are using the Daugman algorithm. The algorithms are using in this case from open sourse with modification, if you want to use the source code, please check the LICENSE.
Daugman algorithm:
where I(x,y) is the eye image, r is the radius to searches over the image (x,y), G(r) is a Gaussian smoothing function. The algorithm starts to search from the pupil, in order to detect the changing of maximum pixel values (partial derivative).
Hough transform:
The Hough transform is a feature extraction technique used in image analysis, computer vision, and digital image processing. where (xi, yi) are central coordinates, and r is the radius. Generally, and eye would be modeled by two circles, pupil and limbus (iris region), and two parabolas, upper and lower eyelids
Starts to detect the eyelids form the horizontal direction, then detects the pupil and iris boundary by the vertical direction.
NORMALIZATION AND FEATURE ENCODING:
From circles to oblong block By using the 1D Log-Gabor filter. In order to extract 9600 bits iris code, the upper and lower eyelids will be processed as a 9600 bits mask during the encoding.
MATCHING:
Hamming distance (HD): where A and B are subjects to compare, which contains 20480=9600 template bits and 20480=9600 mask bits, respectively, in order to calculate by using XOR and AND boolean operators.
These wiki pages are not necessarily related to the facerec framework, but serve as a place to put interesting links, ideas, algorithms or implementations to. Feel free to extend the list, add new wiki pages or request new features in the issue tracker.
Research
Eye Tracking, Image Alignment and Head Pose Estimation
F. Timm and E. Barth. Accurate eye centre localisation by means of gradients. In Proceedings of the Int. Conference on Computer Theory and Applications (VISAPP), volume 1, pages 125-130, Algarve, Portugal, 2011. INSTICC. (PDF Online available, C++ Code)
Feature Extraction
Lior Wolf, Tal Hassner and Yaniv Taigman, Descriptor Based Methods in the Wild, Faces in Real-Life Images workshop at the European Conference on Computer Vision (ECCV), Oct 2008. (PDF Online available), (Matlab Code)
Ojansivu V & Heikkilä J (2008) Blur insensitive texture classification using local phase quantization. Proc. Image and Signal Processing (ICISP 2008), 5099:236-243. (PDF Online available), (Matlab Code)
Free and open source face recognition with deep neural networks.
News
2016-01-19: OpenFace 0.2.0 released! See this blog post for more details.
OpenFace is a Python and Torch implementation of face recognition with deep neural networks and is based on the CVPR 2015 paper FaceNet: A Unified Embedding for Face Recognition and Clustering by Florian Schroff, Dmitry Kalenichenko, and James Philbin at Google. Torch allows the network to be executed on a CPU or with CUDA.
Crafted by Brandon Amos in Satya's research group at Carnegie Mellon University.
Development discussions and bugs reports are on the issue tracker.
This research was supported by the National Science Foundation (NSF) under grant number CNS-1518865. Additional support was provided by the Intel Corporation, Google, Vodafone, NVIDIA, and the Conklin Kistler family fund. Any opinions, findings, conclusions or recommendations expressed in this material are those of the authors and should not be attributed to their employers or funding sources.
Isn't face recognition a solved problem?
No! Accuracies from research papers have just begun to surpass human accuracies on some benchmarks. The accuracies of open source face recognition systems lag behind the state-of-the-art. See our accuracy comparisons on the famous LFW benchmark.
Please use responsibly!
We do not support the use of this project in applications that violate privacy and security. We are using this to help cognitively impaired users sense and understand the world around them.
Overview
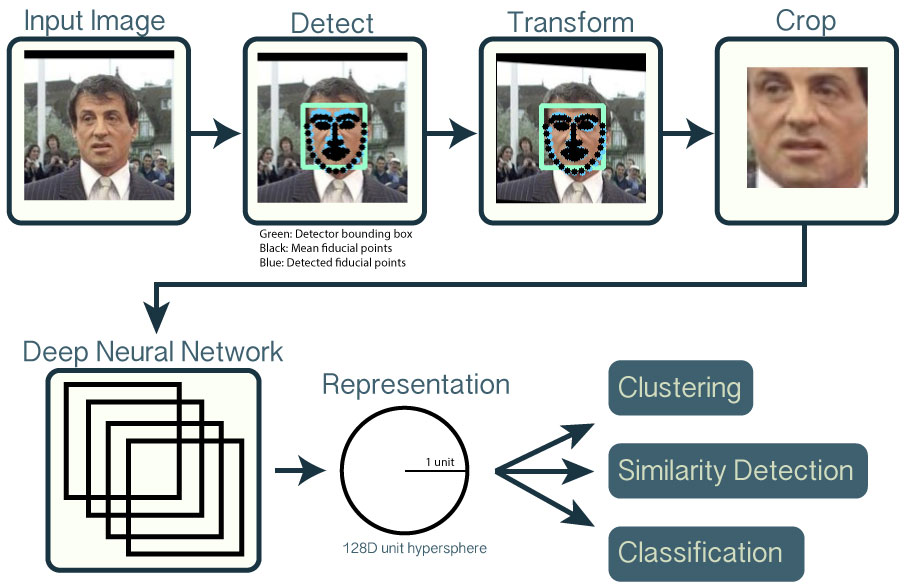
The following overview shows the workflow for a single input image of Sylvestor Stallone from the publicly available LFW dataset.
Detect faces with a pre-trained models from dlib or OpenCV.
Transform the face for the neural network. This repository uses dlib's real-time pose estimation with OpenCV's affine transformation to try to make the eyes and bottom lip appear in the same location on each image.
Use a deep neural network to represent (or embed) the face on a 128-dimensional unit hypersphere. The embedding is a generic representation for anybody's face. Unlike other face representations, this embedding has the nice property that a larger distance between two face embeddings means that the faces are likely not of the same person. This property makes clustering, similarity detection, and classification tasks easier than other face recognition techniques where the Euclidean distance between features is not meaningful.
Apply your favorite clustering or classification techniques to the features to complete your recognition task. See below for our examples for classification and similarity detection, including an online web demo.
The following is a BibTeX and plaintext reference for the OpenFace GitHub repository. The reference may change in the future. The BibTeX entry requires the url LaTeX package.
@misc{amos2016openface,
title = {{OpenFace: Face Recognition with Deep Neural Networks}},
author = {Amos, Brandon and Ludwiczuk, Bartosz and Harkes, Jan and
Pillai, Padmanabhan and Elgazzar, Khalid and Satyanarayanan, Mahadev},
howpublished = {\url{http://github.com/cmusatyalab/openface}},
note = {Accessed: 2016-01-11}
}
Brandon Amos, Bartosz Ludwiczuk, Jan Harkes, Padmanabhan Pillai,
Khalid Elgazzar, and Mahadev Satyanarayanan.
OpenFace: Face Recognition with Deep Neural Networks.
http://github.com/cmusatyalab/openface.
Accessed: 2016-01-11
Zhuo Chen, Kiryong Ha, Wenlu Hu, Rahul Sukthankar, and Junjue Wang for insightful discussions.
Licensing
Unless otherwise stated, the source code and trained Torch and Python model files are copyright Carnegie Mellon University and licensed under the Apache 2.0 License. Portions from the following third party sources have been modified and are included in this repository. These portions are noted in the source files and are copyright their respective authors with the licenses listed.
Development discussions and bugs reports are on the issue tracker.
This research was supported by the National Science Foundation (NSF) under grant number CNS-1518865. Additional support was provided by the Intel Corporation, Google, Vodafone, NVIDIA, and the Conklin Kistler family fund. Any opinions, findings, conclusions or recommendations expressed in this material are those of the authors and should not be attributed to their employers or funding sources.
The following is a BibTeX and plaintext reference for the OpenFace GitHub repository. The reference may change in the future. The BibTeX entry requires the url LaTeX package.
@misc{amos2016openface,
title = {{OpenFace: Face Recognition with Deep Neural Networks}},
author = {Amos, Brandon and Ludwiczuk, Bartosz and Harkes, Jan and
Pillai, Padmanabhan and Elgazzar, Khalid and Satyanarayanan, Mahadev},
howpublished = {\url{http://github.com/cmusatyalab/openface}},
note = {Accessed: 2016-01-11}
}
Brandon Amos, Bartosz Ludwiczuk, Jan Harkes, Padmanabhan Pillai,
Khalid Elgazzar, and Mahadev Satyanarayanan.
OpenFace: Face Recognition with Deep Neural Networks.
http://github.com/cmusatyalab/openface.
Accessed: 2016-01-11
Licensing
Unless otherwise stated, the source code and trained Torch and Python model files are copyright Carnegie Mellon University and licensed under the Apache 2.0 License. Portions from the following third party sources have been modified and are included in this repository. These portions are noted in the source files and are copyright their respective authors with the licenses listed.
An approximated structured output learning approach is developed to learn the appearance model from CLM overtime on low-powered portable devices, such as iPad 2, iPhon 4S, Galaxy S2.
Facial feature detection and tracking are very important in many applications such as face recognition, and face animation.
What has been done
Existing facial feature detectors like tree-structured SVM, Constrained Local Model (CLMs) achieve the state-of-the-art accuracy performance in many benchmarks (e.g. CMU MultiPIE, BioID etc.). However, when it comes to the low-powered device application, the trade-off among accuracy, speed and memory cost becomes apparently the main concern in the facial feature detection related application.
How to make facial feature detection efficient in speed and memory
There are two ways to address the speeding up problem. One is to use GPU(e.g. CUDA), and parallel computing (e.g. OpenMP) techniques to speed up the existing algorithms (e.g. AAM, CLM etc). Another is to improve the steps inside existing algorithms, or let’s say developing a new algorithm. In this paper, we explored how to speed up the facial feature detection with an approach called approximate structured output learning for constrained local model.
What we did
Within this paper we examine the learning of the appearance model in Constrained Local Models (CLM) technique. We have two contributions: firstly we examine an approximate method for doing structured learning, which jointly learns all the appearances of the landmarks. Even though this method has no guarantee of optimality we find it performs better than training the appearance models independently. This also allows for efficiently online learning of a particular instance of a face. Secondly we use a binary approximation of our learnt model that when combined with binary features, leads to efficient inference at runtime using bitwise AND operations. We quantify the generalization performance of our approximate SO-CLM, by training the model parameters on a single dataset, and testing on a total of five unseen benchmarks.
The speed at runtime is demonstrated on the ipad2 platform. Our results clearly show that our proposed system runs in real-time, yet still performs at state-of-the-art levels of accuracy.
An OpenCV based webcam gaze tracker based on a simple image gradient-based eye center algorithm by Fabian Timm.
DISCLAIMER
This does not track gaze yet.It is basically just a developer reference implementation of Fabian Timm's algorithm that shows some debugging windows with points on your pupils.
If you want cheap gaze tracking and don't mind hardware check outThe Eye Tribe. If you want webcam-based eye tracking contactXlabsor use their chrome plugin and SDK. If you're looking for open source your only real bet isPupilbut that requires an expensive hardware headset.
Status
The eye center tracking works well but I don't have a reference point like eye corner yet so it can't actually track where the user is looking.
If anyone with more experience than me has ideas on how to effectively track a reference point or head pose so that the gaze point on the screen can be calculated contact me.
Building
CMake is required to build eyeLike.
OSX or Linux with Make
# do things in the build directory so that we don't clog up the main directory
mkdir build
cd build
cmake ../
make
./bin/eyeLike # the executable file
On OSX with XCode
mkdir build
./cmakeBuild.sh
then open the XCode project in the build folder and run from there.
On Windows
There is some way to use CMake on Windows but I am not familiar with it.
Timm and Barth. Accurate eye centre localisation by means of gradients. In Proceedings of the Int. Conference on Computer Theory and Applications (VISAPP), volume 1, pages 125-130, Algarve, Portugal, 2011. INSTICC.
This code is entirely based on the published code [1]. This document is a tutorial that instructs how to exploit this code with the mixture of models in the original code replaced with yours.
[1] Xiangxin Zhu, Deva Ramanan. Face detection, pose estimation, and landmark localization in the wild. Computer Vision and Pattern Recognition (CVPR) Providence, Rhode Island, June 2012.
Design a mixture of models
We use a mixture of models for face detection. Let's first look into the original model implemented in the code. As for the original mixture of models, total of 13 models form a mixture. Model 1 to 3 have the same tree structure, and are of purpose of detecting human faces which are heading left. Model 4 to 10, in sequence, have the same tree structure, and these 7 are for detecting the frontal faces. The remaining 3 (model 11 to 13) have the same tree structure, and are for detecting the faces heading right.
For better understanding, structure of the model 7 is constructed like below:
Note that there are two kinds of labeling (numbering) systems. One is annotation order and the other is tree order. Annotation order is the ordering system under which the annotations (coordinates of landmark points) on the training images were made, while tree order is of the actual tree structure of a model used on the score evaluation stage.
If you want to use a new facial model, follow the next steps.
Construct a mixture of models. Decide how many models the mixture consists of.
Design a tree structure which fit to the human faces for each model.
Give labels to nodes of trees. As mentioned earlier, each node should be labeled with two numbers, one for annotation ordering system, and the other for tree ordering system.
Annotation order: If you have annotations within the training data, then you have to follow the labeling order of those annotations.
Tree order: Be aware that the id number of parent nodes should be larger than their children's.
For example, simpler model might be like:
The following material of this document is based on a mixture of models which consists of 3 models. Each of three models corresponds to viewpoints of 30, 0, -30 degree, respectively. And all the models have the same tree structure as shown above.
Prepare dataset
For training set, we need data of following files to be prepared:
Image files that include the human faces which we aim to detect.
Annotation files on images that include the coordinate values of landmark points (same as the center of parts in the models)
For each of all the image files, there should be an annotation file named "[Image file name]_lb.mat" in the certain directory for annotation files. These are .mat files, where the coordinate values of landmark points are stored using a matrix variable named "pts". As for our simple model, size of the matrix "pts" is 15 by 2, cause we have 15 landmark points per an image. The first column refers to the x values of landmark points, and the second column refers to the y values, and each of 15 rows corresponds to each landmark point.
opts.viewpoint is a list consisting of the viewpoint angles which the objects face towards. As for the original setting above, for example, it means that we aim to detect the human faces each of which is heading at 90 degree, 75 degree, ..., -90 degree respectively. (zero degree corresponds to the frontal view.)
opts.partpoolsize is a sum over the number of parts of every different model. In the original setting, we have total of 3 different models for detecting the left, front, and right side of faces. These three models are composed of 39, 68, and 39 parts respectively. Thus we have the value of 39+68+39 in result.
Change these two properly to work well with our model. Then the code above should be modified to be like:
And then, we specify mixture of models concretly. We have three models in our mixture of models, so what we have to do in this section is to define opts.mixture(1), opts.mixture(2), and opts.mixture(3) which correspond to our three models.
Let's define a opts.mixture(1) first.
At first, poolid should be a list of integer from 1 to 15, because every single model of our mixture has 15 parts.
Next, the variable I and J define a transformation relation between the annotation and tree order labels. Let I have a array of integer range from 1 to the number of parts. And then, take a close look at J. The k'th number in array J, say nk, means that the node labeled with k in tree order is labeled with nk in annotation order.
S in the next line should be modified to be the array consisting of ones that takes the number of parts as it's length.
Using the variables defined above, we set the anno2treeorder to represent the transformation matrix from annotation to tree order. Just replace the 4th, and 5th argument of the sparse() function with the number of parts.
Finally, pa specifies the id number of parent of each nodes. Note that you should follow the tree order in refering to a node here.
As a result, the original codes might be changed as follows:
% Global mixture 1 to 3, left, frontal, and right face
opts.mixture(1).poolid = 1:15;
I = 1:15;
J = [9 10 11 8 7 3 2 1 6 5 4 12 13 14 15];
S = ones(1,15);
opts.mixture(1).anno2treeorder = full(sparse(I,J,S,15,15)); % label transformation
opts.mixture(1).pa = [0 1 1 1 4 5 6 7 5 9 10 1 12 12 12];
opts.mixture(2) = opts.mixture(1);
opts.mixture(3) = opts.mixture(1);
Edit multipie_data.m
This "multipie_data.m" file does the data preparation work.
First, define what images in our dataset will be used for training set, and what images for test set. Modify the lists trainlist and testlist properly based on the prepared dataset.
Next, set the pathes where the image and annotation in the dataset are located. multipiedir is a path for image files, and annodir is a path for annotation files.
Edit multipie.mat
This .mat file includes a struct variable named multipie which includes the name of the image files classified by the models in our mixture. You may consult the "make_multipie_info" script in tools/ directory to make your own multipie variable more easily.
Run multipie_main.m
Run "compile.m" file first.
Run "multipie_main" file. This script trains the model using the prepared dataset, evaluate the trained model, and even shows the result graphically.
















 http_gim.unmc.edu_dxtests_ROC1.htm.pdf
http_gim.unmc.edu_dxtests_ROC1.htm.pdf The sensitivity and specificity of a diagnostic test depends on more than just the "quality" of the test--they also depend on the definition of what constitutes an abnormal test. Look at the the idealized graph at right showing the number of patients with and without a disease arranged according to the value of a diagnostic test. This distributions overlap--the test (like most) does not distinguish normal from disease with 100% accuracy. The area of overlap indicates where the test cannot distinguish normal from disease. In practice, we choose a cutpoint (indicated by the vertical black line) above which we consider the test to be abnormal and below which we consider the test to be normal. The position of the cutpoint will determine the number of true positive, true negatives, false positives and false negatives. We may wish to use different cutpoints for different clinical situations if we wish to minimize one of the erroneous types of test results.
The sensitivity and specificity of a diagnostic test depends on more than just the "quality" of the test--they also depend on the definition of what constitutes an abnormal test. Look at the the idealized graph at right showing the number of patients with and without a disease arranged according to the value of a diagnostic test. This distributions overlap--the test (like most) does not distinguish normal from disease with 100% accuracy. The area of overlap indicates where the test cannot distinguish normal from disease. In practice, we choose a cutpoint (indicated by the vertical black line) above which we consider the test to be abnormal and below which we consider the test to be normal. The position of the cutpoint will determine the number of true positive, true negatives, false positives and false negatives. We may wish to use different cutpoints for different clinical situations if we wish to minimize one of the erroneous types of test results.
























 eyeLike-master.zip
eyeLike-master.zip





.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}