구글 이미지를 통해서, 데이터셋 구축을 시도하시는 분들이 많을 것으로 생각 됩니다. 여러가지 방법이 있긴 하지만, fastai 학생 중 한명이 작성한 매우 단순하면서도, 꽤 괜찮은 방법이 있어서 소개해 드립니다.
매우 짧은 글로, 사용법을 익히시는데는 약 5분 미만의 시간이 소요됩니다. 그러면, 첨부그림1과 같이 구글 이미지 검색 결과에 대하여, 이미지들에 대한 URL을 몽땅 긁어올 수가 있습니다. 긁어와진 URL은 화면 우측하단에 표시됩니다. (추가적으로, 이미지를 선택/해제도 가능합니다)
이렇게 긁어와진 URL 들은 단순히 복사/붙여넣기 과정을 통해서 CSV 파일형태로 만들 수 있고, fastai 에서는 해당 CSV 파일을 참조하여 데이터셋을 생성하는 기능이 있습니다.
PS; 덧붙여, 현재 fastai 관련 글을 번역하여 저장하는 저장소를 개설하여 운영중에 있습니다. 번역 대상을 리스트업 하고, 차근차근 번역을 수행할 예정입니다. 누구든 참여가 가능하므로, 참여의사를 밝히신 후, 번역을 진행하시고 PR을 보내주시면 많은분들에게 큰 도움이 될 것 같습니다.
번역 저장소: https://github.com/fast-ai-kr/ko-translation
하지만, Public score 0.93정도 이상에서는 그렇게 큰 효과가 없었습니다. 또한, cutout을 적용하면 crop된 image가 성능이 더 높은 모습을 보여주었습니다. 그래서 저는 Bounding box로 crop된 이미지를 input으로 사용했습니다.
Image를 resize하는 방식을 사용했는데 위의 github에서는 squeeze하는 방식을 사용하면 더 좋은 성능을 보여준다고 합니다. 하지만, 저는 이것을 구현하지 못해서 적용하지 못했습니다.
Augmentation :
(saewon님의 kernel을 참고하였습니다.)
Random Resized Crop, Random Horizontal Flip, Random Rotation, AutoAgumentation(CIFAR-10), Normalize, Random Erasing(cutout)을 적용하였습니다. 여기에 mixup을 적용시켰습니다.
Cutmix를 mixup대신 적용시켜 보았지만, 저는 mixup을 사용했을 때 성능이 더 좋게 나타났습니다.
mixup의 alpha값은 0.2, 0.4, 1.0을 사용해보았는데 1.0에서 성능이 가장 좋게 나왔습니다.
rotation은 30도를 주었고 resized crop은 (0.8, 1.0) 다른 것들은 default 값으로 적용시켰습니다.
Sampler :
Class의 이미지 수들의 불균형이 존재했습니다. 균형을 맞추기 위해서 oversampling 방식을 통하여 한 epoch을 당 주어지는 class의 image 수를 같게 맞추었습니다.
Loss :
FocalLoss를 gamma를 0.5, 2, 3을 시도해 보았습니다. gamma가 0.5일 때 성능이 가장 좋았습니다. 하지만, 이것보다 그냥 cross entropy loss가 더 좋은 성능을 보여주었습니다. (제가 구현을 잘못한 것인가요…ㅠㅠ Focal loss가 더 좋을 것으로 예상을 했었는데…) 그렇기에 저는 loss로 cross entropy를 사용했습니다.
Label smoothing을 적용해서 실험해 보았지만 그럴듯한 성능 향상을 보여주지 않았습니다.
(Triplet loss구현을 시도해 보았지만, 시간 부족을 구현을 완료하지 못했습니다. 혹시 해보신 분 있으면 결과를 남겨주시면 좋겠습니다.)
Model :
저는 Efficientnet-B7, B6, B5, PNASNet, NASNet을 사용했습니다. 각 model head에 dropout(0.4~0.5)을 추가해서 사용했습니다. (IIdoo kim님이 discussion에 올렸던 model은 너무 train하기에 무거워서 결국 사용하지 못했습니다.)
WS-DAN(Weakly Supervised Data Augmentation Network)이라는 아주 흥미로운 구조를 실험해 보았습니다. 이것을 Efficientnet-B7 model에 적용시켰습니다. Training 시간은 3배로 걸리지만 성능은 크게 개선되지 않아서 이 구조를 버리게 되었습니다.’
Scheduler :
초반에는 CosineannealingLR, MultistepLR, StepLR을 사용해 보았습니다. 이중에서 적절한 값을 찾아본 결과 MultistepLR이 가장 좋은 성능을 보여주어서 이것을 사용했습니다. 후반기에 최종 model을 train할 때는 SuperConvergence라는 scheduler를 사용하여 train을 하였습니다.
Optimizer :
다양한 optimizer를 baseline에 실험해 보았는데 AdamW가 가장 성능이 좋았습니다. Efficientnet모델에는 AdamW를 사용하게 되었습니다. PNAS, NAS에서는 SGD + momentum이 성능이 좋은 모습을 보여주어 이것을 사용하였습니다.
누군가 "딥러닝 시작 할때 가장 좋은 강의는 무엇인가요?"라는 질문을 하시면, 전 "스탠포드 대학의 #CS231N 강좌인것 같아요" 라고 대답했습니다. 그러나 강의가 영어로 되어 있어서 조금 불편했던 분들이 있으실 겁니다. (이재원 (Jaewon Lee) 님이 CS231N 전체 강의에 한글자막 작업을 하신 것을 알고 있습니다. ^^ 정말 대단한 분 ^^ )
앞으로 전 위와 같은 질문을 받을 경우 #edwith 의 "[부스트코스]딥러닝 기초 강좌"요 라고 말할 수 있을 것 같습니다 😁
전체가 우리말로 되어 있으며 TensorFlow와 Pytorch 둘다 공부할 수 있도록 강좌가 나뉘어져 있습니다. 저의경우 이런 강좌는 아직까지 본적이 없습니다 😍
또한 코세라와 유다시티의 딥러닝 강좌처럼 직접 실습을 헤보고 제출도 할 수 있는 Jupyter notebook 기반의 프로젝트 코스가 있습니다. 😆 이 작업에 모두의연구소도 함께 참여했습니다.
이제부터 "딥러닝 기초과목은 무엇으로 공부하면 될까요?" 라는 질문을 받으면 "edwith의 부스트코로 시작하세요~" 라고 말하려고 합니다~^^
이 작업을 함께 해주신 커넥트재단 장지수 님과 이효은 (Annah Lee) 님께 너무 감사드립니다 🙇♂️ 그외 모두를위한 딥러닝 시즌2를 위하여 재능 기부해주신 분들 너무 감사드립니다. 강의 잘 보겠습니다. 강의가 이렇게 만들어질 수 있다는게 너무 멋진 일이란 생각이드네요.
그리고 추가로 이 강좌의 프로젝트 작성에 힘써 주신 모두연 소속 연구원 여러분 ~ 너무 수고하셨습니다. (박창대, 이재영, 오진우 (Jinwoo Matthew Oh) , 이일구 (Il Gu Yi)) 함께해서 즐거웠습니다~~^^
[CS230 Deep Learning ](https://scpd.stanford.edu/search/publicCourseSearchDetails.do?method=load&courseId=82209222)
[CS231A Computer Vision: From 3D Reconstruction to Recognition ](https://scpd.stanford.edu/search/publicCourseSearchDetails.do?method=load&courseId=10796915)
[CS231N Convolutional Neural Networks for Visual Recognition ](https://scpd.stanford.edu/search/publicCourseSearchDetails.do?method=load&courseId=42262144)
[AA228 Decision Making Under Uncertainty ](https://scpd.stanford.edu/search/publicCourseSearchDetails.do?method=load&courseId=39254289)
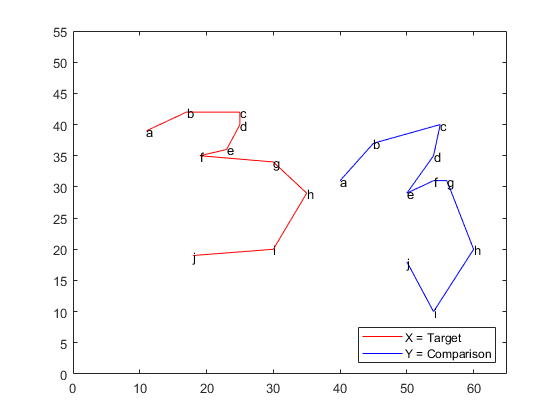
This example shows how to use Procrustes analysis to compare two handwritten number threes. Visually and analytically explore the effects of forcing size and reflection changes.
Load and Display the Original Data
Input landmark data for two handwritten number threes.
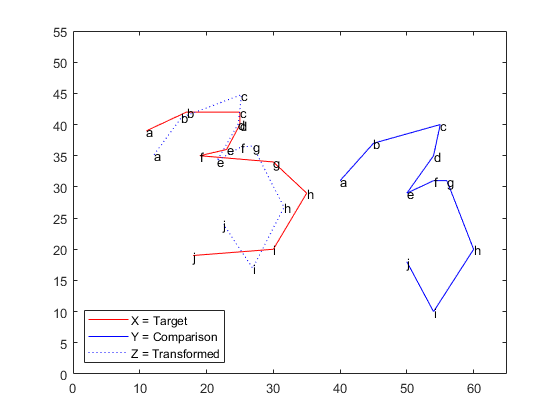
Use Procrustes analysis to find the transformation that minimizes distances between landmark data points.
[d,Z,tr] = procrustes(X,Y);
The outputs of the function are d (a standardized dissimilarity measure), Z (a matrix of the transformed landmarks), and tr (a structure array of the computed transformation with fields T , b , and c which correspond to the transformation equation).
Visualize the transformed shape, Z , using a dashed blue line.
Use two different numerical values, the dissimilarity measure d and the scaling measure b , to assess the similarity of the target shape and the transformed shape.
The dissimilarity measure d gives a number between 0 and 1 describing the difference between the target shape and the transformed shape. Values near 0 imply more similar shapes, while values near 1 imply dissimilarity.
d
d = 0.1502
The small value of d in this case shows that the two shapes are similar. procrustes calculates d by comparing the sum of squared deviations between the set of points with the sum of squared deviations of the original points from their column means.
The resulting measure d is independent of the scale of the size of the shapes and takes into account only the similarity of landmark data.
Examine the size similarity of the shapes.
tr.b
ans = 0.9291
The sizes of the target and comparison shapes in the previous figure appear similar. This visual impression is reinforced by the value of b = % 0.93, which implies that the best transformation results in shrinking the comparison shape by a factor .93 (only 7%).
Restrict the Form of the Transformations
Explore the effects of manually adjusting the scaling and reflection coefficients.
Force b to equal 1 (set 'Scaling' to false) to examine the amount of dissimilarity in size of the target and transformed figures.
ds = procrustes(X,Y,'Scaling',false)
ds = 0.1552
In this case, setting 'Scaling ' to false increases the calculated value of d only 0.0049, which further supports the similarity in the size of the two number threes. A larger increase in d would have indicated a greater size discrepancy.
This example requires only a rotation, not a reflection, to align the shapes. You can show this by observing that the determinant of the matrix T is 1 in this analysis.
det(tr.T)
ans = 1.0000
If you need a reflection in the transformation, the determinant of T is -1. You can force a reflection into the transformation as follows.
[dr,Zr,trr] = procrustes(X,Y,'Reflection',true); dr
dr = 0.8130
The d value increases dramatically, indicating that a forced reflection leads to a poor transformation of the landmark points. A plot of the transformed shape shows a similar result.
The landmark data points are now further away from their target counterparts. The transformed three is now an undesirable mirror image of the target three.
It appears that the shapes might be better matched if you flipped the transformed shape upside down. Flipping the shapes would make the transformation even worse, however, because the landmark data points would be further away from their target counterparts. From this example, it is clear that manually adjusting the scaling and reflection parameters is generally not optimal.
Read “Distinctive Image Features from Scale-Invariant Keypoints" by D. Lowe 14-SIFT-based object recognition (slides, video 1,2) Images: testSIFTimages.zip
MIT 18.065 Matrix Methods in Data Analysis, Signal Processing, and Machine Learning, Spring 2018 Instructor: Gilbert Strang View the complete course: https://ocw.mit.edu/18-065S18 YouTube Playlist: https://www.youtube.com/playlist?list=PLUl4u3cNGP63oMNUHXqIUcrkS2PivhN3k
안녕하세요. 텐서플로우 코리아! 이번에는 비전공자인 제가 어떻게 머신러닝을 공부했고, 제가 발견한 머신러닝 공부자료를 공유해드리고자 글을 씁니다.^^
시작하기에 앞서 제 소개를 조금 하자면, 저는 기계공학부에 재학 중인 학부생이며, 작년 8월부터 머신러닝 공부를 시작하였습니다. 당시 저는 학부 2학년 학생으로, 확률통계는 고등학교 때 배운 이상 공부하지 않았고, 프로그래밍 언어는 매트랩을 조금 다를 수 있는 것을 제외하고는 완전히 문외한 상태였습니다.
딥러닝에 대해 관심을 갖게 된 후 제일 처음 봤던 강의는 1. 유튜브 '생활코딩'님의 파이썬 강의였습니다. 파이썬을 하나도 모르는 상태였기에 이틀 동안 필요하다 싶은 강의만 골라서 수강을 하였지만, 파이썬을 처음 봐서 그런지 for 문 정도만 이해하였습니다. ** 딥러닝 공부를 하다 보면 아시겠지만, Class를 사용해서 코딩을 정말 많이 합니다. 반드시 파이썬 강의를 들으신다면 for문, Class, def는 이해하고 딥러닝 공부 시작하시는 게 좋습니다.
* 영어가 되시는 분들은 sentdex채널의 파이썬 강의를 들으면 좋다고 하네요! (Seungwoo Lee님 감사합니다!)
2. '생활코딩'강의를 듣고 나서 들은 것이 김성훈 교수님의 '모두의 딥러닝'강의입니다. 듣기 전부터 2회 독을 하자는 마음으로 들었고 제가 파이썬을 잘 몰랐기에 강의에 사용된 코드는 모조리 다 외워서 사용했습니다. (같은 문제에 대한 코딩만 10번 이상 한 것 같습니다.)
3. 그 다음 들었던 강의가 CS231N인데 제가 영알못이기도 했고, 모두의 딥러닝도 완벽히 이해하지 못한 상태여서 한번 완강을 했는데도(복습은 하지 않았습니다) 이해를 거의 하지 못했고 시간만 낭비했습니다. ㅠㅠ
이렇게 위의 3 강의를 듣는데 1달 반 정도 걸렸고, 이후로는 학기가 시작이 되어 학기 공부를 한다고 딥러닝 공부는 많이 못 한 것 같습니다.
5. 또한 학기 중에는 꾸준히 Tensorflow korea에서 올라오는 글들을 눈팅했는데, 눈팅한다고 딥러닝 실력이 느는 것은 아니지만 최신 딥러닝의 동향을 알 수 있었고, 제가 답할 수 있는 자료는 답변을 달면서 공부했던 것 같습니다.
이렇게 학기가 지나가고 겨울방학이 왔는데 이때부터는 다음과 같이 공부한 것 같습니다.
6. CS231N을 다시 공부하였습니다. 확실히 '라온피플'에서 batch_normalization, CNN의 역할, Overfitting의 이유 등 여러 가지 딥러닝 지식을 공부하고 강의를 들으니 옛날에 이해했던 것보다 더 많이 이해가 되더군요. 그래서 일주일에 3강씩 1달 안 걸려 CS231N을 다 공부한 것 같습니다.
7. CS231N을 공부하면서 같이 해본 것이 Backpropagation에 대해 수학적으로 증명을 해보았습니다. 수학적으로 증명을 해봤는데 수식은 이해를 했는데 내용은 아직도 잘 이해를 못 한 것 같네요...ㅠ 아무튼 제가 생각하기에 Backpropagation은 반드시 한번 정리할 필요가 있다고 생각합니다.
8.CS231N도 공부했겠다. 이제 논문을 읽으면서 공부를 해야겠다고 생각을 했고, 하필이면 처음 건드렸던 논문이 Restricted Boltzmann machine입니다. MLE, MAP, Likelihood가 무엇인지 전혀 몰랐던 저는 이를 공부하기 위해 구글링과 페북에 수많은 질문을 하며..(죄송합니다 ㅠㅠ) 조금씩 공부해나갔습니다.
9. RBM이 생각보다 만만치 않은 논문이었기에 최성준님의 강의도 보고, 여러 가지 블로그들을 찾아보며 공부를 했습니다 . 결론적으로 MLE, MAP 및 고전 딥러닝에 대해서도 알아야 되겠다고 생각했고, Kooc의 KAIST 문일철 교수님의 인공지능학개론1을 수강하였습니다.
이것이 제가 지금까지 공부한 과정이며, 앞으로는 Kooc 문일철 교수님 인공지능학개론2, 심화 인공지능학개론을 수강할 예정입니다.
------------------------------------------------------------------------------------------------------ 공부하면서 느낀 주관적인 생각과 공부 자료에 대해서 소개를 해드리자면 다음과 같습니다.
1.프로그래밍도 중요하지만 확률통계 '수학'도 상당히 중요한 것 같습니다. 특히 Generative model 또는 Reinforcement learning에서 수학을 많이 사용하는 것 같은데 이쪽으로 공부를 해보고 싶다고 생각하면 수학을 소홀히 하면 안 될 듯합니다.
2.Tensorflow ? Keras ? Pytorch? 어떤 것을 사용해야 할까요?? => 저는 Tensorflow를 쓰지만, 개인 취향인 것 같습니다. 하지만 들리는 소리에 의하면 놀 때는 pytorch, 연구할 때는 Tensorflow, 내 코드가 조금 더럽다 싶으면 Keras인 것 같습니다. 프레임 워크는 별로 안 중요한 것 같네요.(초보자의 생각입니다 ㅋㅋ)
3. 자신이 연구자가 될지 개발자가 될지를 선택하고 이에 따라 공부 방향을 선택하는 게 좋을 것 같습니다. 연구자는 수학 쪽이나 논리 쪽으로 더욱 공부하면 좋을 것 같고, 개발자는 코드짜는 것을 공부하는데 더욱 많은 시간을 할애하는 게 좋다고 생각합니다.
5. 테리의 딥러닝 토크:https://www.youtube.com/watch… ** 엄태웅 님의 딥러닝 관련 토크로 저는 안 봐서 잘 모르지만 쉬운 영상도 있고 어려운 영상도 있다고 알고 있습니다. 또한, 엄태웅님이 원래는 기계공학 전공이기에 기구학? 관련 강의도 있는데 흥미 있으신 분들에게는 추천합니다!
6. 최성준 님의 딥러닝 강의:http://www.edwith.org/search/show… ** 입문용은 아닌 것 같고, 약간 어렵습니다. 하지만 다양하고 대표적인 주제들을(RBM, LSTM, GAN, IMAGE CAPTIONING, CNN, Neural style 등)을 가지고 있기에 CS 231n을 듣고 나서 본격적으로 딥러닝 공부를 시작하겠다 하시는 분들이 듣기에는 정말 좋은 강의인 것 같습니다. 영어발음이 너무 좋으십니다. 리스릭 보츠만 뭐신... ㅋㅋ
7. CS231N: 스탠퍼드 딥러닝 강좌로 딥러닝의 처음부터 최근에 뜨고 있는 주제들에 대해서 강의가 진행됩니다. 매년 다루는 범위가 다르고, 강의해주시는 분들 실력도 엄청나게 출중하셔서 영어만 잘한다면 정말 추천해 드리는 강좌이고 영어를 잘 못해도 꼭 들어야 하는 강좌라고 생각합니다.
8. Natural language processing at stanford:https://www.youtube.com/watch… ** 컴퓨터 비전 분야에서는 CS231N이 있다면 Natural language processing에는 이 강좌가 있습니다!
9.Andrew NG 코세라 강의: 딥러닝의 대가 Andrew NG의 딥러닝 강의가 코세라에 있습니다. 강력하게 추천하지만 제가 안 들어봐서 난이도가 어떤지는 잘 모르겠습니다.
10.문일철 교수님 인공지능학개론1 :http://kooc.kaist.ac.kr/machinelearning1_17 **전통 머신러닝에 대한 강의로 기본적인 확률통계 MLE, MAP부터 시작해서 SVM까지 진도를 나갑니다. 내용은 살짝 어려울 수가 있으며 개인적으로 Generative model 공부하기 전에 들으면 좋다고 생각합니다. 기계학습에서 확률통계가 어떻게 사용됐는지를 느낄 수 있는 강의라고 생각합니다. 강력추천!
11.문일철 교수님 인공지능학개론2:http://kooc.kaist.ac.kr/machinelearning2__17 ** 베이지안 네트워크, clustering, Markov 체인, mcmc 방법 등을 다루며, 내용이 상당히 어렵지만, 논문을 읽다 보면 항상 나오는 그놈의 Markov 때문에 저는 수강하기로 했습니다.
12. 문일철 교수님기계학습 심화 강좌:https://www.youtube.com/watch… ** 대학원 수업 정도의 난이도를 가진 강좌입니다. 본분 추론 및 최근 유행하고?? 있는 Gaussian process에 대해 다루는 수업인데 아주 어렵습니다. ㅠㅠ(아직 안 들었지만 느낌상으로 그럼..)
13. 남세동님의 휴먼 러닝:https://www.youtube.com/watch… ** 안 들어 봐서 잘은 모르겠지만, 강의 시간이 그렇게 길지도 않고 남세동님이 워낙 똑똑하시고 자신만의 철학이 확고하시기에 들으면 정말 도움이 많이 될 것으로 생각합니다!!
<공부 깃허브>
1. 활석님의 Gan Github:https://github.com/…/tensorflow-generative-model-collections ** 두말할 필요가 없습니다.
2. 초짜 대학원 생입장에서 이해하는 ~ 블로그:http://jaejunyoo.blogspot.com/…/generative-adversarial-nets… ** '자칭' 초짜라고 말하시는 갓재준님께서 운영하는 블로그인데 쉽게 여러가지 딥러닝 이론들을 설명해놨다고 합니다. 솔찍히 쉽지는 않은 그런 블로그입니다. 그렇다고 그렇게 어렵지도 않아요 ㅎ
수화는 class 마다 길이가 다를테고, 사람마다 transient(다음 동작을 위한 손의 이동) 길이가 다를텐데 어떻게 RNN을 적용 할 수 있을까요?
바꿔서 질문드리면, 그림처럼 Real-world에서는 수화1 -> transient(손이 이동) -> 수화2 -> transient -> 수화3-... 이런식일텐데, 결과1과 4는 각각 수화1, 2하고 겹치는 영역이 많아 올바른 결과를 낼것 같은데, 결과 2,3 은 transient때문에 수화 n, m의 결과를 낼 것 같습니다. 이럴때 어떻게 해야하는걸까요?
crop된 데이터만 가지고 시계열을 하다가 real-world로 가려니 어떻게 해야하는지 모르겠습니다.
The 𝐋𝐚𝐧𝐝𝐦𝐚𝐫𝐤 𝐚𝐧𝐧𝐨𝐭𝐚𝐭𝐢𝐨𝐧 is used to detect shape variations. When can you use it? 1. Detecting and recognizing facial features 2. Human body-part in motion 3. For emotion and gesture recognition
머신러닝 공부를 시작하기 위해 구글 검색을 해보면 열이면 아홉은 Andrew Ng 교수의 머신러닝 강좌부터 볼 것을 추천하고 있다. 앤드류 응 교수는 구글 브래인팀을 이끌었던 세계적인 AI 권위자로 스탠포드 대학 교수이자 코세라 창립자이다.
참고로 코세라 강의는 월 $45를 결제하면 Specializations에 있는 모든 과목을 무제한을 들을 수 있는데, 유명한 머신러닝 강의는 대부분 코세라에 있다. 가입 후 7일 동안은 무료라서 일단 가입했다.

앤드류 응 교수의 강의는 머신러닝 기본 강의라고 보면 될 것 같다. 수업은 원하는 때에 들을 수 있었고, 다만 숙제가 있다. 숙제는 Octave(옥타브)라는 스크립트 언어로 나왔다. 개인적으로 이 강의를 보고 난 후 파이썬을 공부했는데, 파이썬을 이미 공부한 사람들은 강의 숙제를 할 때 GitHub에 파이썬 코드로 재작성된 자료를 참고하면 될 것이다.
2. 파이썬(Python) 공부
어떤 머신러닝 전문가는 머신러닝을 배울 때 코딩부터 배우지 말라고 한다. 그런데 필자는 앤드류 응 교수의 머신러닝 수업을 대강 마무리 하고 바로 파이썬 문법을 공부했다. 삽질부터 해보는 개발자여서 그런지 이론보다는 코드에 먼저 눈이 갔던 것 같다.
파이썬은 머신러닝에 즐겨 쓰이는 프로그래밍 언어이다. R이나 Matlab 같은 것도 있는데 머신러닝 언어 중 대세는 파이썬이라고 한다.
필자는 파이썬 공부를 하기 위해 파이썬 공식 사이트로 가서 문서들을 한 번 쭉 훑어보고 유데미(Udemy)에서 제일 짧은 강의부터 찾았다. 강의 이름은 김왼손의 유기농냠냠파이썬이라는 강좌였는데 파이썬 문법 부분만 빠르게 넘겨 보았다. 여러가지 프로그래밍 언어를 다뤄봐서 그런지 몇몇 파이썬 만의 독특한 문법들 빼고는 크게 어렵지는 않았다. 개인적으로 파이썬 문법 공부는 하루면 충분했던 것 같다.
만약 이미 코세라를 구독하고 있고 프로그래밍이 처음이거나 파이썬을 기초부터 제대로 배우고 싶다면 Python 3 Programming 강의를 추천한다.
3. 그래프 모형, 인공신경망 강의
머신러닝을 공부할 때는 머신러닝 개론 -> 그래프 모형 -> 인공신경망 순으로 공부하면 된다고 한다. 그래프 모형(Graphical Model)이란 머신러닝의 근간을 이루는 모델로 변수간 상호 의존 관계를 설명한다.

그래프 모형에 대한 강의는 Daphne Koller 교수의 Probabilistic Graphical Models 강의가 가장 유명하다. 이 역시 코세라 강의이다.
다음으로 최근 머신러닝의 대세가 된 알고리즘인 인공신경망(Neural Network) & 딥러닝(Deep Learning) 공부를 했다. AI, 머신러닝, 인공신경망, 딥러닝 개념이 어렵다면 아래 그림과 같은 관계라고 보면 된다.

AI(Artificial Intelligence)란 인간의 지능을 기계로 만든 것을 의미하며, 그 구체적인 방법 중 하나가 머신러닝(Machine Learning)인 것이다. 그리고 머신러닝을 구현하는 알고리즘 중의 하나가 인공신경망(Neural Network)과 딥러닝(Deep Learning)인 것이다.
딥러닝은 인공신경망에서 발전된 형태로 심화신경망 또는 개선된 인공신경망 등으로 불리기도 한다.
인공신경망 강의 역시 앤드류 응 교수의 코세라 강의인 Neural Networks and Deep Learning 강의를 들었다. 참고로 아직 보지는 않았지만 인공신경망 쪽에서 휴고 라로첼(Hugo Larochelle)의 유튜브 강의도 괜찮다고 한다.
4. 머신러닝 실습 강의
코세라 강의를 들으면서 잘 이해되지 않은 부분도 있고, 영어로 수업이 진행되다 보니 놓치는 부분도 많았던 것 같다. 그래서 조금 더 쉽고 실용적인 강의가 없나 찾다가 추가로 유데미에 있는 머신러닝 강의를 들었다.
참고로 유데미 강의는 프로그래밍을 전혀 해보지 않은 사람은 다소 따라가기 어려워 보였다. 강의는 텐서플로우와 케라스를 통해 인공 신경망 개발 환경을 구축해보고 딥러닝을 통한 이미지, 데이터 분류 실습을 해본다.
또한 강화학습에 대한 내용과 Apache Sparks MLlib을 통한 대량 데이터 머신러닝 처리에 대한 내용도 배울 수 있었다.
5. 추가 학습
유데미 강의는 아직도 틈틈히 수강하고 있다. 그 와중에 다른 머신러닝/딥러닝 강의를 알아보다가 홍콩과기대 김성 교수님의 강의를 보게 되었다. 뭔가 이전에 배웠던 내용을 recap 하는 차원에서 보게 되었는데 머신러닝 이론에 대해 깔금하게 정리되어 있다. 머신러닝 공부를 시작하거나 공부 중이라면 참고하면 괜찮은 강의이지 않을까 싶다.
6. 머신러닝 공부에 도움 될 만한 URL 모음
머신러닝 공부에 도움 될 만한 사이트나 자료에 대한 URL은 이곳에 계속 업데이트할 예정이다.
- 딥러닝을 위한 기초 수학 : https://www.slideshare.net/theeluwin/ss-69596991 - 텐서플로우 연습 코드 모음 : https://github.com/golbin/TensorFlow-Tutorials - 구글 딥러닝 강의 : https://www.udacity.com/course/deep-learning--ud730 - 머신러닝 오픈소스 튜토리얼 : https://scikit-learn.org/stable/tutorial/ - 옥스포드 머신러닝 수업자료 : https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/ - 머신러닝 용어집 : https://developers.google.com/machine-learning/glossary/?hl=ko
아리스토텔레스의 "시작이 반이다" 라는 명언이 있다. 그런데 영어 원문은 "Well begun, is half done." 이다. 한국어로 번역되면서 Well의 의미가 삭제된 것 같다. 제대로 해석하면 "좋은"시작이 반을 차지한다는 것이지 무작정 시작만 하면 된다는 의미는 아니다.
머신러닝, 딥러닝 공부 역시 마찬가지인 것 같다. 제대로 된 강의와 가이드로 공부를 시작해야 한다. 그리고 그 첫 시작은 앤드류 응 교수의 coursera 강의라고 생각한다. 아직도 머신러닝 공부를 망설이고 있다면, 일단 코세라에 접속해서 무료 강의부터 들어보자.
Learn: 1. linear algebra well (e.g. matrix math) 2. calculus to an ok level (not advanced stuff) 3. prob. theory and stats to a good level 4. theoretical computer science basics 5. to code well in Python and ok in C++
Then read and implement ML papers and *play* with stuff! :-)
Machine Learning all resources in one place for you to get started. This playlist ( https://www.youtube.com/playlist?list=PLqrmzsjOpq5iBQEtgHSeF4WaVzII_ycBn ) contains of: 1. Complete Machine learning video lessons 2. Complete Mathematics video lessons 3. Some advance topic on machine learning 4. Some interesting project ideas. 5. Coming Soon with more videos and topics. Subscribe to keep yourself warm with ML: ( https://www.youtube.com/channel/UCq8JbYayUHvKvjimPV0TCqQ?sub_confirmation=1 )
3. 생명 정보학(원제: Fundamental Concepts of Bioinformatics), 조재창 역, Dan E. Krane, Michael L. Raymer (2007), 월드 사이언스: 번역본. 기본적으로 알아야할 내용이 정리가 잘 되어 있다고 함음. 이것도 바이오를 아예 몰라서 읽어야만 했다.
Particle Swarm Optimization – A Tutorial Dear all here is a tutorial paper on one of the optimization algorithms, is called particle swarm optimization (PSO). It is one of the most well-known optimization algorithms. In this paper: • Introduction to PSO. • Detailed explanation for the PSO algorithm with a good visualization. • Two neumerical examples, o The first example explains in a step-by-step approach how the PSO works. o The second example explains how the PSO suffers from the local minima problem. • Another experiment to explain fastly how the PSO can be used for optimizing some classifiers such as Support vector Machine (SVM) • The paper includes Matlab code
Your comments are highly appreciated.
Here is the link of the pdf https://www.academia.edu/36712310/Particle_Swarm_Optimization_-A_Tutorial or here on researchgate https://www.researchgate.net/publication/325575025_Particle_Swarm_Optimization-A_Tutorial?_sg=ClpsRLk5klozmA85qNOSIg2eNn_d1WDbh1yDUouQVJ7DTHmxP4DQuCK42YkJHtmQyc6U7zLXAwGAYbzWm6E03QtSGm18_jZG71IS6P9z.yGITB4_GJRnwIchxQM63qJvdswe4sGcmi9e4odn0gB2lL6nqWNdPYzTJsGI0Afo0xn-OWZMLXFIhmMTeLtuDaQ
The code is here https://de.mathworks.com/matlabcentral/fileexchange/62998-particle-swarm-optimization--pso--tutorial























 trans_mat2pts_openVer.zip
trans_mat2pts_openVer.zip



.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}