케라스 강좌 내용
https://tykimos.github.io/Keras/lecture/
https://www.facebook.com/groups/TensorFlowKR/permalink/498759757131754/
https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/
https://www.gitbook.com/book/leonardoaraujosantos/artificial-inteligence/details
안녕하세요.
오늘 공유드릴 것은 머신러닝/딥러닝 전반의 내용을 담고 있는 ebook입니다.
선형대수부터 해서, classification 계열의 정복자들 (residual net 등), detection 계열의 정복자들 (Yolo 등), 강화학습 뭐 거의 다 다루고 있다고 해도 무방하네요.
https://leonardoaraujosantos.gitbooks.io/artificial-inte…/…/
pdf로 다운 받으셔서 보실 수도 있습니다.
https://www.gitbook.com/…/le…/artificial-inteligence/details
대략 살펴보니 입문자에게도 부담없을 정도로 자세하게 설명이 되어 있는 것 같습니다.
한 사람이 정리한 듯 한데, 만약 맞다면 대단한 정리네요;;;
https://www.facebook.com/nextobe1/posts/341026106333391
LSTM을 이용한 감정 분석 w/ Tensorflow
O'Reilly의 서버에서 미리 빌드된 환경에서 이 코드를 셀 단위로 실행하거나 자신의 컴퓨터에서 이 파일을 실행할 수 있습니다. 또한 사전 에 Pre-Trained LSTM.ipynb로 자신 만의 텍스트를 입력하고 훈련된 네트워크의 출력을 볼 수 있습니다.
| deploy a CNN that could understand 10 signs or hand gestures. (0) | 2018.02.22 |
|---|---|
| Quick complete Tensorflow tutorial to understand and run Alexnet, VGG, Inceptionv3, Resnet and squeezeNet networks (0) | 2017.07.26 |
| Python TensorFlow Tutorial – Build a Neural Network (0) | 2017.04.11 |
| Time Series Forecasting with Python 7-Day Mini-Course (0) | 2017.03.24 |
| TensorFlow: training on my own image (0) | 2017.03.21 |
https://kr.mathworks.com/help/images/ref/imhistmatch.html
imhistmatch
Adjust histogram of 2-D image to match histogram of reference image
B = imhistmatch(A,ref)B = imhistmatch(A,ref,nbins)[B,hgram] = imhistmatch(___)B = imhistmatch(A,ref)A returning output image B whose histogram approximately matches the histogram of the reference image ref.
If both A and ref are truecolor RGB images, imhistmatch matches each color channel of A independently to the corresponding color channel of ref.
If A is a truecolor RGB image and ref is a grayscale image, imhistmatch matches each channel of A against the single histogram derived from ref.
If A is a grayscale image, ref must also be a grayscale image.
Images A and ref can be any of the permissible data types and need not be equal in size.
B = imhistmatch(A,ref,nbins)nbins equally spaced bins within the appropriate range for the given image data type. The returned image B has no more than nbins discrete levels.
If the data type of the image is either single or double, the histogram range is [0, 1].
If the data type of the image is uint8, the histogram range is [0, 255].
If the data type of the image is uint16, the histogram range is [0, 65535].
If the data type of the image is int16, the histogram range is [-32768, 32767].
[ returns the histogram of the reference image B,hgram] = imhistmatch(___)ref used for matching in hgram. hgram is a 1-by-nbins (when ref is grayscale) or a 3-by-nbins (when ref is truecolor) matrix, where nbins is the number of histogram bins. Each row in hgram stores the histogram of a single color channel of ref.
These aerial images, taken at different times, represent overlapping views of the same terrain in Concord, Massachusetts. This example demonstrates that input images A and Ref can be of different sizes and image types.
Load an RGB image and a reference grayscale image.
A = imread('concordaerial.png'); Ref = imread('concordorthophoto.png');
Get the size of A.
size(A)
ans =
2036 3060 3
Get the size of Ref.
size(Ref)
ans =
2215 2956
Note that image A and Ref are different in size and type. Image A is a truecolor RGB image, while image Ref is a grayscale image. Both images are of data type uint8.
Generate the histogram matched output image. The example matches each channel of A against the single histogram of Ref. Output image B takes on the characteristics of image A - it is an RGB image whose size and data type is the same as image A. The number of distinct levels present in each RGB channel of image B is the same as the number of bins in the histogram built from grayscale image Ref. In this example, the histogram of Ref and B have the default number of bins, 64.
B = imhistmatch(A,Ref);
Display the RGB image A, the reference image Ref, and the histogram matched RGB image B. The images are resized before display.
figure
imshow(imresize(A, 0.25))
title('RGB Image with Color Cast')
figure
imshow(imresize(Ref, 0.25))
title('Reference Grayscale Image')
figure
imshow(imresize(B, 0.25))
title('Histogram Matched RGB Image')
In this example, you will see the effect on output image B of varying the number of equally spaced bins in the target histogram of image Ref, from its default value 64 to the maximum value of 256 for uint8 pixel data.
The following images were taken with a digital camera and represent two different exposures of the same scene.
A = imread('office_2.jpg'); % Dark Image Ref = imread('office_4.jpg'); % Reference image
Image A, being the darker image, has a preponderance of its pixels in the lower bins. The reference image, Ref, is a properly exposed image and fully populates all of the available bins values in all three RGB channels: as shown in the table below, all three channels have 256 unique levels for 8–bit pixel values.

The unique 8-bit level values for the red channel is 205 for A and 256 for Ref. The unique 8-bit level values for the green channel is 193 for A and 256 for Ref. The unique 8-bit level values for the blue channel is 224 for A and 256 for Ref.
The example generates the output image B using three different values of nbins: 64, 128 and 256. The objective of function imhistmatch is to transform image A such that the histogram of output image B is a match to the histogram of Ref built with nbins equally spaced bins. As a result, nbins represents the upper limit of the number of discrete data levels present in image B.
[B64, hgram] = imhistmatch(A, Ref, 64); [B128, hgram] = imhistmatch(A, Ref, 128); [B256, hgram] = imhistmatch(A, Ref, 256);

The unique 8-bit level values for the red channel for nbins=[64 128 256] are 57 for output image B64, 101 for output image B128, and 134 for output image B256. The unique 8-bit level values for the green channel for nbins=[64 128 256] are 57 for output image B64, 101 for output image B128, and 134 for output image B256. The unique 8-bit level values for the blue channel for nbins=[64 128 256] are 57 for output image B64, 101 for output image B128, and 134 for output image B256. Note that as nbins increases, the number of levels in each RGB channel of output image B also increases.
This example shows how to perform histogram matching with different numbers of bins.
Load a 16-bit DICOM image of a knee imaged via MRI.
K = dicomread('knee1.dcm'); % read in original 16-bit image LevelsK = unique(K(:)); % determine number of unique code values disp(['image K: ',num2str(length(LevelsK)),' distinct levels']);
image K: 448 distinct levels
disp(['max level = ' num2str( max(LevelsK) )]);max level = 473
disp(['min level = ' num2str( min(LevelsK) )]);min level = 0
All 448 discrete values are at low code values, which causes the image to look dark. To rectify this, scale the image data to span the entire 16-bit range of [0, 65535].
Kdouble = double(K); % cast uint16 to double kmult = 65535/(max(max(Kdouble(:)))); % full range multiplier Ref = uint16(kmult*Kdouble); % full range 16-bit reference image
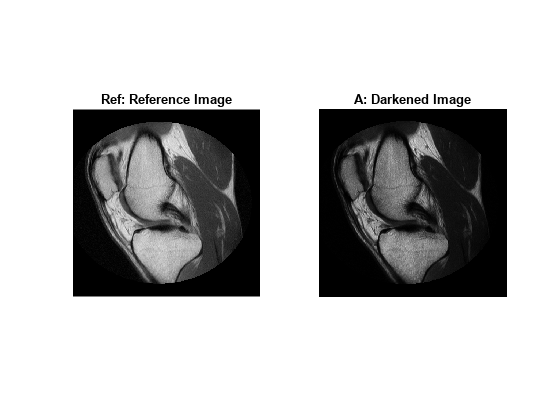
Darken the reference image Ref to create an image A that can be used in the histogram matching operation.
%Build concave bow-shaped curve for darkening |Ref|. ramp = [0:65535]/65535; ppconcave = spline([0 .1 .50 .72 .87 1],[0 .025 .25 .5 .75 1]); Ybuf = ppval( ppconcave, ramp); Lut16bit = uint16( round( 65535*Ybuf ) ); % Pass image |Ref| through a lookup table (LUT) to darken the image. A = intlut(Ref,Lut16bit);
View the reference image Ref and the darkened image A. Note that they have the same number of discrete code values, but differ in overall brightness.
subplot(1,2,1) imshow(Ref) title('Ref: Reference Image') subplot(1,2,2) imshow(A) title('A: Darkened Image');
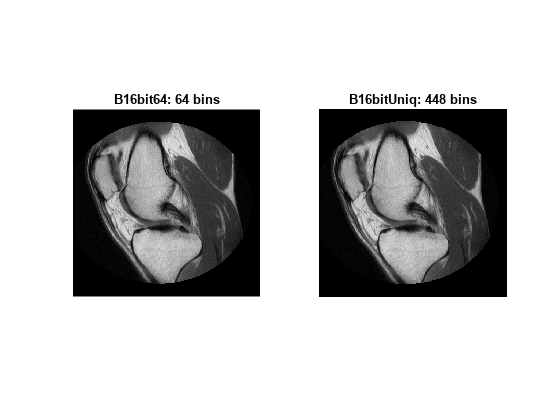
Generate histogram-matched output images using histograms with different number of bins. First use the default number of bins, 64. Then use the number of values present in image A, 448 bins.
B16bit64 = imhistmatch(A(:,:,1),Ref(:,:,1)); % default: 64 bins N = length(LevelsK); % number of unique 16-bit code values in image A. B16bitUniq = imhistmatch(A(:,:,1),Ref(:,:,1),N);
View the results of the two histogram matching operations.
figure subplot(1,2,1) imshow(B16bit64) title('B16bit64: 64 bins') subplot(1,2,2) imshow(Ref) title(['B16bitUniq: ',num2str(N),' bins'])
The objective of imhistmatch is to transform image A such that the histogram of image B matches the histogram derived from image ref. It consists of nbins equally spaced bins which span the full range of the image data type. A consequence of matching histograms in this way is that nbins also represents the upper limit of the number of discrete data levels present in image B.
An important behavioral aspect of this algorithm to note is that as nbins increases in value, the degree of rapid fluctuations between adjacent populated peaks in the histogram of image B tends to increase. This can be seen in the following histogram plots taken from the 16–bit grayscale MRI example.

An optimal value for nbins represents a trade-off between more output levels (larger values of nbins) while minimizing peak fluctuations in the histogram (smaller values of nbins).
histeq | imadjust | imhist | imhistmatchn
| matlab code - convert face landmarks matlab .mat to .pts file (0) | 2018.06.07 |
|---|---|
| matlab audio read write (0) | 2017.12.20 |
| matlab figure 파일을 300dpi로 저장하는 법 - How can I save a figure to a TIFF image with resolution 300 dpi in MATLAB? (0) | 2017.03.27 |
| matlab TreeBagger 예제 나와있는 페이지 (0) | 2017.03.11 |
| MATLAB Treebagger and Random Forests (0) | 2017.03.11 |
| 머신러닝 용어 https://developers.google.com/machine-learning/glossary/ (0) | 2017.09.28 |
|---|---|
| 30개의 필수 데이터과학, 머신러닝, 딥러닝 치트시트 (0) | 2017.09.26 |
| Beginning Machine Learning – A few Resources [Subjective] (0) | 2017.06.20 |
| SNU TF 스터디 모임 1기 때부터 쭉 모아온 발표자료들 (0) | 2017.04.14 |
| List of Free Must-Read Books for Machine Learning (0) | 2017.04.06 |
http://cristivlad.com/beginning-machine-learning-a-few-resources-subjective/

I’ve been meaning to write this post for a while now, because many people following the scikit-learn video tutorials and the ML group are asking for direction, as in resources for those who are just starting out.
So, I decided to put up a short and subjective list with some of the resources I’d recommend for this purpose. I’ve used some of these resources when I started out with ML. Practically, there are unlimited free resources online. You just have to search, pick something, and start putting in the work, which is probably one of the most important aspects of learning and developing any skill.
Since most of these resources involve knowledge of programming (especially Python), I am assuming you have decent skills. If you don’t, I’d suggest learning to program first. I’ll write a post about that in the future, but until then, you could start, hands-on, with the free Sololearn platform.
The following resources include, but are not limited to books, courses, lectures, posts, and Jupyter notebooks, just to name a few.
In my opinion, skill development with more than one type of resource can be fruitful. Spreading yourself too thin by trying to learn from too many places at once could be detrimental though. To illustrate, here’s what I think of a potentially good approach to study ML in any given day (and I’d try to do skill development 6-7 days a week, for several hours each day):
– 1-2 hours reading from a programming book and coding along
– 1 hour watching a lecture, or a talk, or reading a research paper
– 30 minutes to 1 hour working through a course
– optional: reading 1-2 posts.
This would be a very intensive approach and it may lead to good results. These results are dependent of good sleep – in terms of quality (at night, at the right hours) and quantity (7-8 hours consistently).
Now, the short-list…
1.1. Machine Learning with Python – From CognitiveClass.ai
I put this on the top of the list because it not only goes through the basics of ML such as supervised vs. unsupervised learning, types of algorithms and popular models, but it also provides LABs, which are Jupyter notebooks where you practice what you learned during the video lectures. If you pass all weekly quizes and the final exam, you’ll obtain a free course certificate. I took this course a while ago.
1.2. Intro to Machine Learning – From Udacity
Taught by Sebastian Thrun and Katie Malone, this is a ~10-week, self-paced, very interactive course. The videos are very short, but engaging; there are more than 400 videos that you have to go through. I specifically like this one because it is very hands-on and engaging, so it requires your active input. I enjoyed going through the Enron dataset.
1.3. Machine Learning – From Udacity
Taught by Michael Littman, Charles Isbell, and Pushkar Kolhe, this is a ~4-month, self-paced course, offered as CS7641 at Georgia Tech and it’s part of their Online Masters Degree.
1.4. Principles of Machine Learning – From EDX, part of a Microsoft Program
Taught by Dr. Steve Elston and Cynthia Rudin. It’s a 6-week, intermediate level course.
1.5. Machine Learning Crash Course – from Berkeley
A 3-part series going through some of the most important concepts of ML. The accompanying graphics are ‘stellar’ and aid the learning process tremendously.
Of course, there are many more ML courses on these online learning platforms and on other platforms as well (do a search with your preferred search engine).
If you’re ML savvy, you may be wondering why I am not mentioning Ng’s course. It’s not that I don’t recommend it; on the contrary, I do. But I’d suggest going through it only after you have a solid knowledge of the basics.
Additionally, here are the materials from Stanford and MIT‘s two courses on machine learning. Some video lectures can be found in their Youtube playlists. Other big universities provide their courses on the open on Youtube or via other video sharing platforms. Find one or two and go through them diligently.
2.1. Python for Data Analysis – Wes Mckiney
– to lay the foundation of working with ML related tools and libraries
2.2. Python Machine Learning – Sebastian Raschka
– reference book.
2.3. Introduction to Machine Learning with Python – Andreas Muller and Sarah Guido
– I’ve been using this book as inspiration material in my ML Youtube video series.
Going through these books hands-on (coding along) is critical. Each of them have their github repository of Jupyter notebooks, which makes it even easier to get your hands on the code.
Strong ML skills imply solid knowledge of the mathematics, statistics and probability theory behind the algorithms, atop of the programming skills. Once you get the conceptualized knowledge of ML, you should be studying the complexities of it.
Here’s a list of free books and resources to help you along. It is relevant to ML and data mining, deep learning, natural language processing, neural networks, linear algebra (!!!), and probability and statistics (!!!).
3.1. Luis Serrano – A friendly Introduction to Machine Learning
– one of the most well explained video tutorials that I went through. No wonder Luis teaches with Udacity. His other videos on neural networks bring the same level of quality!
3.2. Roshan – Machine Learning – Video Series
– from setting up the environment to hands-on. Notebooks are also available.
3.3. Machine Learning with Scikit-Learn (Scipy 2016) – Part 1 and Part 2
– taught, hands-on, by Muller and Raschka. Notebooks are available in the description of the videos. Similar videos by these authors are available in the ‘recommended’ section (on the right of the video).
At this point I realized I’ve been using the word ‘hands-on’ way too much. But that’s okay. I guess you get the point.
3.4. Machine Learning with Python – Sentdex Playlist
– Sentdex needs no introduction. His current ML playlist consists of 72 videos.
3.5. Machine Learning with Scikit-Learn – Cristi Vlad Playlist
This is my own playlist. It currently has 27 videos and I’m posting new ones every few days. I’m working with scikit-learn on the cancer dataset and I explore different ML algorithms and models.
3.6. Machine Learning APIs by Example – Google Developers
– presented at the 2017 Google I/O Conference.
3.7. Practical Introduction to Machine Learning – Same Hames
– tutorial from 2016 PyCon Australia.
3.8. Machine Learning Recipes – with Josh Gordon
– from Google Developers.
To find similar channels you can search for anything related to ‘pycon’, ‘pydata’, ‘enthought python’, etc. I also remind you that many top universities and companies posts their courses, lectures, and talks on their video channels. Look them up.
4.1. Machine Learning 101 – from BigML
“In this page you will find a set of useful articles, videos and blog posts from independent experts around the world that will gently introduce you to the basic concepts and techniques of Machine Learning.”
4.2. Learning Machine Learning – EliteDataScience
4.3. Top-down learning path: Machine Learning for Software Engineers
– a collection of resources from a self-taught software engineer, Nam Vu, who purposed to study roughly 4 hours a night.
4.4. Machine Learning Mastery – by Dr. Jason Brownlee
To reiterate, there is an unlimited number of free and paid resources that you can learn from. To try to include too many is futile and could be counterproductive. Here I only presented a few personal picks and I suggested ways to search for others if these do not appeal to you.
Remember, to be successful in skill development, I’d recommend an eclectic approach by learning and practicing from a combination of different types of resources at the same time (just a few) for a couple of hours everyday.
Learning from courses, hands-on lectures, talks, and presentations, books (hands-on) and Jupyter notebooks is a very demanding and intensive approach that could lead to good results if you are consistent. Good sleep is crucial for skill development. Enjoy the ride!
Image: here.
| 30개의 필수 데이터과학, 머신러닝, 딥러닝 치트시트 (0) | 2017.09.26 |
|---|---|
| 데이터과학 및 딥러닝을 위한 데이터세트 (0) | 2017.07.04 |
| SNU TF 스터디 모임 1기 때부터 쭉 모아온 발표자료들 (0) | 2017.04.14 |
| List of Free Must-Read Books for Machine Learning (0) | 2017.04.06 |
| Regularization resources in matlab (0) | 2017.04.05 |
| Machine Learning · Artificial Inteligence 웹북. 딥러닝 기초 도움 (0) | 2017.10.31 |
|---|---|
| Deep Learning Lecture Collection (Spring 2017): http://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv (0) | 2017.08.13 |
| NumPy for Matlab Users (0) | 2017.05.29 |
| Python Numpy Tutorial (0) | 2017.05.29 |
| Videos to learn about AI, Machine Learning & Deep Learning (0) | 2017.05.09 |
| India’s IIS and NIT Develops AI To Identify Protesters With Their Faces Partly Covered With Scarves or Hat (0) | 2017.09.10 |
|---|---|
| 머신러닝/딥러닝 전반의 내용을 담고 있는 ebook (0) | 2017.07.07 |
| PyTorch Tutorial (0) | 2017.05.13 |
| TensorFlow Tutorial #16 Reinforcement Learning (0) | 2017.04.24 |
| How to Use Timesteps in LSTM Networks for Time Series Forecasting - Machine Learning Mastery (0) | 2017.04.18 |
https://kr.mathworks.com/help/images/ref/tformfwd.html
http://web.mit.edu/emeyers/www/warping/warp.html
https://gist.github.com/jack06215/b8af25d366bf4c2307f2
https://kr.mathworks.com/help/images/ref/projective2d-class.html
https://kr.mathworks.com/discovery/affine-transformation.html
https://stackoverflow.com/questions/30437467/how-imwarp-transfer-points-in-matlab
http://www.openu.ac.il/home/hassner/projects/cnn_agegender/
https://github.com/GilLevi/AgeGenderDeepLearning/issues/1
http://www.openu.ac.il/home/hassner/Adience/EidingerEnbarHassner_tifs.pdf
https://kr.mathworks.com/matlabcentral/answers/168461-help-with-imwarp-and-affine2d
https://kr.mathworks.com/help/images/ref/imtransform.html
https://stackoverflow.com/questions/25205635/how-to-register-face-by-landmark-points
https://stackoverflow.com/questions/18925181/procrustes-analysis-with-numpy
https://stackoverflow.com/questions/20242826/matlab-face-alignment-code
http://www.cse.wustl.edu/~taoju/cse554/lectures/lect07_Alignment.pdf
https://kr.mathworks.com/help/images/ref/fitgeotrans.html
https://kr.mathworks.com/help/images/ref/imregtform.html
https://kr.mathworks.com/help/images/ref/imtransform.html
https://cmusatyalab.github.io/openface/
http://elijah.cs.cmu.edu/DOCS/CMU-CS-16-118.pdf
https://kr.mathworks.com/matlabcentral/fileexchange/3025-affine-transformation
https://kr.mathworks.com/matlabcentral/fileexchange/4364-procrustes-problem
https://www.mathworks.com/examples/matlab/community/20690-procrustes-shape-analysis
https://kr.mathworks.com/matlabcentral/newsreader/view_thread/311960http://kr.mathworks.com/help/stats/procrustes.html
https://cmusatyalab.github.io/openface/
http://what-when-how.com/face-recognition/face-alignment-models-face-image-modeling-and-representation-face-recognition-part-1/https://kr.mathworks.com/matlabcentral/answers/287058-face-normalisation-using-affine-transform
https://kr.mathworks.com/matlabcentral/fileexchange/35106-the-phd-face-recognition-toolbox?focused=5217480&tab=function
| keras Sequential, Functional, and Model Subclassing 설명 사이트 (0) | 2021.02.15 |
|---|---|
| skin detection (0) | 2017.03.29 |
| 파이참 설치 및 사용법법 & Jupyter 서버 설치 및 실행법 (0) | 2017.03.27 |
| 20170228_roc curve area under of them (0) | 2017.03.01 |
| 20170212 mssql 테이블 수정 (0) | 2017.02.12 |
https://github.com/GilLevi/AgeGenderDeepLearning/issues/1
Hi,
Thank you for your interest in our work.
Alignment is done by detecting about 68 facial landmark and applying an affine transformation to a predefined set of locations for those 68 landmarks.
I didn't understand what you mean by the size of the face in the image. Can you please elaborate?
Best,
Gil
| Compare Handwritten Shapes Using Procrustes Analysis (0) | 2019.07.02 |
|---|---|
| GrabCut, GraphCut matlab Source code (0) | 2018.06.18 |
| Procrustes shape analysis 설명 잘 돼 있음 (0) | 2017.06.02 |
| Plotting and Intrepretating an ROC Curve (0) | 2017.03.01 |
| awesome-object-proposals (0) | 2017.02.28 |
Alex Townsend, August 2011
(Chebfun Example geom/Procrustes.m)
Procrustes shape analysis is a statistical method for analysing the distribution of sets of shapes (see [1]). Let's suppose we pick up a pebble from the beach and want to know how close its shape matches the outline of an frisbee. Here is a plot of the frisbee and the beach pebble.

Two shapes are equivalent if one can be obtained from the other by translating, scaling and rotating. Before comparison we thus:
1. Translate the shapes so they have mean zero.
2. Scale so the shapes have Root Mean Squared Distance (RMSD) to the origin of one.
3. Rotate to align major axis.
Here is how the frisbee and the pebble compare after each stage.

To calculate the Procrustes distance we would measure the error between the two shapes at a finite number of reference points and compute the vector 2-norm. In this discrete case In Chebfun we calculate the continuous analogue:
In the discrete version of Procrustes shape analysis statisticians choose reference points on the two shapes (to compare). They then work out the difference between corresponding reference points. The error computed depends on this correspondence. A different correspondence gives a different error. In the continuous case this correspondence becomes the parameterisation. A different parameterisation of the two curves gives a different error. This continuous version of Procrustes (as implemented in this example) is therefore more of an 'eye-ball' check than a robust statistical analysis.
At the beach shapes reflect on the surface of the sea. An interesting question is: How close, in shape, is a pebble to its reflection? Here is a plot of a pebble and its reflection.

Here is how the pebble and its reflection compare after each stage of translating, scaling and rotating.

Now we calculate the continuous Procrustes distance.
Comparing this result to the Procrustes distance of the pebble and a frisbee shows that the pebble is closer in shape to a frisbee than its own reflection!
Contents
MATLAB® and !NumPy/!SciPy have a lot in common. But there are many differences. NumPy and SciPy were created to do numerical and scientific computing in the most natural way with Python, not to be MATLAB® clones. This page is intended to be a place to collect wisdom about the differences, mostly for the purpose of helping proficient MATLAB® users become proficient NumPy and SciPy users. NumPyProConPage is another page for curious people who are thinking of adopting Python with NumPy and SciPy instead of MATLAB® and want to see a list of pros and cons.
|
In MATLAB®, the basic data type is a multidimensional array of double precision floating point numbers. Most expressions take such arrays and return such arrays. Operations on the 2-D instances of these arrays are designed to act more or less like matrix operations in linear algebra. |
In NumPy the basic type is a multidimensional array. Operations on these arrays in all dimensionalities including 2D are elementwise operations. However, there is a special matrix type for doing linear algebra, which is just a subclass of the array class. Operations on matrix-class arrays are linear algebra operations. |
|
MATLAB® uses 1 (one) based indexing. The initial element of a sequence is found using a(1). See note 'INDEXING' |
Python uses 0 (zero) based indexing. The initial element of a sequence is found using a[0]. |
|
MATLAB®'s scripting language was created for doing linear algebra. The syntax for basic matrix operations is nice and clean, but the API for adding GUIs and making full-fledged applications is more or less an afterthought. |
NumPy is based on Python, which was designed from the outset to be an excellent general-purpose programming language. While Matlab's syntax for some array manipulations is more compact than NumPy's, NumPy (by virtue of being an add-on to Python) can do many things that Matlab just cannot, for instance subclassing the main array type to do both array and matrix math cleanly. |
|
In MATLAB®, arrays have pass-by-value semantics, with a lazy copy-on-write scheme to prevent actually creating copies until they are actually needed. Slice operations copy parts of the array. |
In NumPy arrays have pass-by-reference semantics. Slice operations are views into an array. |
|
In MATLAB®, every function must be in a file of the same name, and you can't define local functions in an ordinary script file or at the command-prompt (inlines are not real functions but macros, like in C). |
NumPy code is Python code, so it has no such restrictions. You can define functions wherever you like. |
|
MATLAB® has an active community and there is lots of code available for free. But the vitality of the community is limited by MATLAB®'s cost; your MATLAB® programs can be run by only a few. |
!NumPy/!SciPy also has an active community, based right here on this web site! It is smaller, but it is growing very quickly. In contrast, Python programs can be redistributed and used freely. See Topical_Software for a listing of free add-on application software, Mailing_Lists for discussions, and the rest of this web site for additional community contributions. We encourage your participation! |
|
MATLAB® has an extensive set of optional, domain-specific add-ons ('toolboxes') available for purchase, such as for signal processing, optimization, control systems, and the whole SimuLink® system for graphically creating dynamical system models. |
There's no direct equivalent of this in the free software world currently, in terms of range and depth of the add-ons. However the list in Topical_Software certainly shows a growing trend in that direction. |
|
MATLAB® has a sophisticated 2-d and 3-d plotting system, with user interface widgets. |
Addon software can be used with Numpy to make comparable plots to MATLAB®. Matplotlib is a mature 2-d plotting library that emulates the MATLAB® interface. PyQwt allows more robust and faster user interfaces than MATLAB®. And mlab, a "matlab-like" API based on Mayavi2, for 3D plotting of Numpy arrays. See the Topical_Software page for more options, links, and details. There is, however, no definitive, all-in-one, easy-to-use, built-in plotting solution for 2-d and 3-d. This is an area where Numpy/Scipy could use some work. |
|
MATLAB® provides a full development environment with command interaction window, integrated editor, and debugger. |
Numpy does not have one standard IDE. However, the IPython environment provides a sophisticated command prompt with full completion, help, and debugging support, and interfaces with the Matplotlib library for plotting and the Emacs/XEmacs editors. |
|
MATLAB® itself costs thousands of dollars if you're not a student. The source code to the main package is not available to ordinary users. You can neither isolate nor fix bugs and performance issues yourself, nor can you directly influence the direction of future development. (If you are really set on Matlab-like syntax, however, there is Octave, another numerical computing environment that allows the use of most Matlab syntax without modification.) |
NumPy and SciPy are free (both beer and speech), whoever you are. |
Use arrays.
The only disadvantage of using the array type is that you will have to use dot instead of * to multiply (reduce) two tensors (scalar product, matrix vector multiplication etc.).
Numpy contains both an array class and a matrix class. The array class is intended to be a general-purpose n-dimensional array for many kinds of numerical computing, while matrix is intended to facilitate linear algebra computations specifically. In practice there are only a handful of key differences between the two.
Operator *, dot(), and multiply():
For array, '*' means element-wise multiplication, and the dot() function is used for matrix multiplication.
For matrix, '*' means matrix multiplication, and the multiply() function is used for element-wise multiplication.
For array, the vector shapes 1xN, Nx1, and N are all different things. Operations like A[:,1] return a rank-1 array of shape N, not a rank-2 of shape Nx1. Transpose on a rank-1 array does nothing.
For matrix, rank-1 arrays are always upconverted to 1xN or Nx1 matrices (row or column vectors). A[:,1] returns a rank-2 matrix of shape Nx1.
Handling of higher-rank arrays (rank > 2)
array objects can have rank > 2.
matrix objects always have exactly rank 2.
array has a .T attribute, which returns the transpose of the data.
matrix also has .H, .I, and .A attributes, which return the conjugate transpose, inverse, and asarray() of the matrix, respectively.
The array constructor takes (nested) Python sequences as initializers. As in, array([[1,2,3],[4,5,6]]).
The matrix constructor additionally takes a convenient string initializer. As in matrix("[1 2 3; 4 5 6]").
There are pros and cons to using both:
array
![]() You can treat rank-1 arrays as either row or column vectors. dot(A,v) treats v as a column vector, while dot(v,A) treats v as a row vector. This can save you having to type a lot of transposes.
You can treat rank-1 arrays as either row or column vectors. dot(A,v) treats v as a column vector, while dot(v,A) treats v as a row vector. This can save you having to type a lot of transposes.
![]() Having to use the dot() function for matrix-multiply is messy -- dot(dot(A,B),C) vs. A*B*C.
Having to use the dot() function for matrix-multiply is messy -- dot(dot(A,B),C) vs. A*B*C.
![]() Element-wise multiplication is easy: A*B.
Element-wise multiplication is easy: A*B.
![]() array is the "default" NumPy type, so it gets the most testing, and is the type most likely to be returned by 3rd party code that uses NumPy.
array is the "default" NumPy type, so it gets the most testing, and is the type most likely to be returned by 3rd party code that uses NumPy.
![]() Is quite at home handling data of any rank.
Is quite at home handling data of any rank.
![]() Closer in semantics to tensor algebra, if you are familiar with that.
Closer in semantics to tensor algebra, if you are familiar with that.
![]() All operations (*, /, +, ** etc.) are elementwise
All operations (*, /, +, ** etc.) are elementwise
matrix
![]() Behavior is more like that of MATLAB® matrices.
Behavior is more like that of MATLAB® matrices.
![]() Maximum of rank-2. To hold rank-3 data you need array or perhaps a Python list of matrix.
Maximum of rank-2. To hold rank-3 data you need array or perhaps a Python list of matrix.
![]() Minimum of rank-2. You cannot have vectors. They must be cast as single-column or single-row matrices.
Minimum of rank-2. You cannot have vectors. They must be cast as single-column or single-row matrices.
![]() Since array is the default in NumPy, some functions may return an array even if you give them a matrix as an argument. This shouldn't happen with NumPy functions (if it does it's a bug), but 3rd party code based on NumPy may not honor type preservation like NumPy does.
Since array is the default in NumPy, some functions may return an array even if you give them a matrix as an argument. This shouldn't happen with NumPy functions (if it does it's a bug), but 3rd party code based on NumPy may not honor type preservation like NumPy does.
![]() A*B is matrix multiplication, so more convenient for linear algebra.
A*B is matrix multiplication, so more convenient for linear algebra.
![]() Element-wise multiplication requires calling a function, multipy(A,B).
Element-wise multiplication requires calling a function, multipy(A,B).
![]() The use of operator overloading is a bit illogical: * does not work elementwise but / does.
The use of operator overloading is a bit illogical: * does not work elementwise but / does.
The array is thus much more advisable to use, but in the end, you don't really have to choose one or the other. You can mix-and-match. You can use array for the bulk of your code, and switch over to matrix in the sections where you have nitty-gritty linear algebra with lots of matrix-matrix multiplications.
Numpy has some features that facilitate the use of the matrix type, which hopefully make things easier for Matlab converts.
A matlib module has been added that contains matrix versions of common array constructors like ones(), zeros(), empty(), eye(), rand(), repmat(), etc. Normally these functions return arrays, but the matlib versions return matrix objects.
mat has been changed to be a synonym for asmatrix, rather than matrix, thus making it concise way to convert an array to a matrix without copying the data.
Some top-level functions have been removed. For example numpy.rand() now needs to be accessed as numpy.random.rand(). Or use the rand() from the matlib module. But the "numpythonic" way is to use numpy.random.random(), which takes a tuple for the shape, like other numpy functions.
The table below gives rough equivalents for some common MATLAB® expressions. These are not exact equivalents, but rather should be taken as hints to get you going in the right direction. For more detail read the built-in documentation on the NumPy functions.
Some care is necessary when writing functions that take arrays or matrices as arguments --- if you are expecting an array and are given a matrix, or vice versa, then '*' (multiplication) will give you unexpected results. You can convert back and forth between arrays and matrices using
asarray: always returns an object of type array
asmatrix or mat: always return an object of type matrix
asanyarray: always returns an array object or a subclass derived from it, depending on the input. For instance if you pass in a matrix it returns a matrix.
These functions all accept both arrays and matrices (among other things like Python lists), and thus are useful when writing functions that should accept any array-like object.
In the table below, it is assumed that you have executed the following commands in Python:
from numpy import *
import scipy as Sci
import scipy.linalg
Also assume below that if the Notes talk about "matrix" that the arguments are rank 2 entities.
THIS IS AN EVOLVING WIKI DOCUMENT. If you find an error, or can fill in an empty box, please fix it! If there's something you'd like to see added, just add it.
|
MATLAB |
numpy |
Notes | |
|
help func |
info(func) or help(func) or func? (in Ipython) |
get help on the function func | |
|
which func |
find out where func is defined | ||
|
type func |
source(func) or func?? (in Ipython) |
print source for func (if not a native function) | |
|
a && b |
a and b |
short-circuiting logical AND operator (Python native operator); scalar arguments only | |
|
a || b |
a or b |
short-circuiting logical OR operator (Python native operator); scalar arguments only | |
|
1*i,1*j,1i,1j |
1j |
complex numbers | |
|
eps |
spacing(1) |
Distance between 1 and the nearest floating point number | |
|
ode45 |
scipy.integrate.ode(f).set_integrator('dopri5') |
integrate an ODE with Runge-Kutta 4,5 | |
|
ode15s |
scipy.integrate.ode(f).\ |
integrate an ODE with BDF | |
The notation mat(...) means to use the same expression as array, but convert to matrix with the mat() type converter.
The notation asarray(...) means to use the same expression as matrix, but convert to array with the asarray() type converter.
|
MATLAB |
numpy.array |
numpy.matrix |
Notes |
|
ndims(a) |
ndim(a) or a.ndim |
get the number of dimensions of a (tensor rank) | |
|
numel(a) |
size(a) or a.size |
get the number of elements of an array | |
|
size(a) |
shape(a) or a.shape |
get the "size" of the matrix | |
|
size(a,n) |
a.shape[n-1] |
get the number of elements of the nth dimension of array a. (Note that MATLAB® uses 1 based indexing while Python uses 0 based indexing, See note 'INDEXING') | |
|
[ 1 2 3; 4 5 6 ] |
array([[1.,2.,3.], |
mat([[1.,2.,3.], |
2x3 matrix literal |
|
[ a b; c d ] |
vstack([hstack([a,b]), |
bmat('a b; c d') |
construct a matrix from blocks a,b,c, and d |
|
a(end) |
a[-1] |
a[:,-1][0,0] |
access last element in the 1xn matrix a |
|
a(2,5) |
a[1,4] |
access element in second row, fifth column | |
|
a(2,:) |
a[1] or a[1,:] |
entire second row of a | |
|
a(1:5,:) |
a[0:5] or a[:5] or a[0:5,:] |
the first five rows of a | |
|
a(end-4:end,:) |
a[-5:] |
the last five rows of a | |
|
a(1:3,5:9) |
a[0:3][:,4:9] |
rows one to three and columns five to nine of a. This gives read-only access. | |
|
a([2,4,5],[1,3]) |
a[ix_([1,3,4],[0,2])] |
rows 2,4 and 5 and columns 1 and 3. This allows the matrix to be modified, and doesn't require a regular slice. | |
|
a(3:2:21,:) |
a[ 2:21:2,:] |
every other row of a, starting with the third and going to the twenty-first | |
|
a(1:2:end,:) |
a[ ::2,:] |
every other row of a, starting with the first | |
|
a(end:-1:1,:) or flipud(a) |
a[ ::-1,:] |
a with rows in reverse order | |
|
a([1:end 1],:) |
a[r_[:len(a),0]] |
a with copy of the first row appended to the end | |
|
a.' |
a.transpose() or a.T |
transpose of a | |
|
a' |
a.conj().transpose() or a.conj().T |
a.H |
conjugate transpose of a |
|
a * b |
dot(a,b) |
a * b |
matrix multiply |
|
a .* b |
a * b |
multiply(a,b) |
element-wise multiply |
|
a./b |
a/b |
element-wise divide | |
|
a.^3 |
a**3 |
power(a,3) |
element-wise exponentiation |
|
(a>0.5) |
(a>0.5) |
matrix whose i,jth element is (a_ij > 0.5) | |
|
find(a>0.5) |
nonzero(a>0.5) |
find the indices where (a > 0.5) | |
|
a(:,find(v>0.5)) |
a[:,nonzero(v>0.5)[0]] |
a[:,nonzero(v.A>0.5)[0]] |
extract the columms of a where vector v > 0.5 |
|
a(:,find(v>0.5)) |
a[:,v.T>0.5] |
a[:,v.T>0.5)] |
extract the columms of a where column vector v > 0.5 |
|
a(a<0.5)=0 |
a[a<0.5]=0 |
a with elements less than 0.5 zeroed out | |
|
a .* (a>0.5) |
a * (a>0.5) |
mat(a.A * (a>0.5).A) |
a with elements less than 0.5 zeroed out |
|
a(:) = 3 |
a[:] = 3 |
set all values to the same scalar value | |
|
y=x |
y = x.copy() |
numpy assigns by reference | |
|
y=x(2,:) |
y = x[1,:].copy() |
numpy slices are by reference | |
|
y=x(:) |
y = x.flatten(1) |
turn array into vector (note that this forces a copy) | |
|
1:10 |
arange(1.,11.) or |
mat(arange(1.,11.)) or |
create an increasing vector see note 'RANGES' |
|
0:9 |
arange(10.) or |
mat(arange(10.)) or |
create an increasing vector see note 'RANGES' |
|
[1:10]' |
arange(1.,11.)[:, newaxis] |
r_[1.:11.,'c'] |
create a column vector |
|
zeros(3,4) |
zeros((3,4)) |
mat(...) |
3x4 rank-2 array full of 64-bit floating point zeros |
|
zeros(3,4,5) |
zeros((3,4,5)) |
mat(...) |
3x4x5 rank-3 array full of 64-bit floating point zeros |
|
ones(3,4) |
ones((3,4)) |
mat(...) |
3x4 rank-2 array full of 64-bit floating point ones |
|
eye(3) |
eye(3) |
mat(...) |
3x3 identity matrix |
|
diag(a) |
diag(a) |
mat(...) |
vector of diagonal elements of a |
|
diag(a,0) |
diag(a,0) |
mat(...) |
square diagonal matrix whose nonzero values are the elements of a |
|
rand(3,4) |
random.rand(3,4) |
mat(...) |
random 3x4 matrix |
|
linspace(1,3,4) |
linspace(1,3,4) |
mat(...) |
4 equally spaced samples between 1 and 3, inclusive |
|
[x,y]=meshgrid(0:8,0:5) |
mgrid[0:9.,0:6.] or |
mat(...) |
two 2D arrays: one of x values, the other of y values |
|
ogrid[0:9.,0:6.] or |
mat(...) |
the best way to eval functions on a grid | |
|
[x,y]=meshgrid([1,2,4],[2,4,5]) |
meshgrid([1,2,4],[2,4,5]) |
mat(...) |
|
|
ix_([1,2,4],[2,4,5]) |
mat(...) |
the best way to eval functions on a grid | |
|
repmat(a, m, n) |
tile(a, (m, n)) |
mat(...) |
create m by n copies of a |
|
[a b] |
concatenate((a,b),1) or |
concatenate((a,b),1) |
concatenate columns of a and b |
|
[a; b] |
concatenate((a,b)) or |
concatenate((a,b)) |
concatenate rows of a and b |
|
max(max(a)) |
a.max() |
maximum element of a (with ndims(a)<=2 for matlab) | |
|
max(a) |
a.max(0) |
maximum element of each column of matrix a | |
|
max(a,[],2) |
a.max(1) |
maximum element of each row of matrix a | |
|
max(a,b) |
maximum(a, b) |
compares a and b element-wise, and returns the maximum value from each pair | |
|
norm(v) |
sqrt(dot(v,v)) or |
sqrt(dot(v.A,v.A)) or |
L2 norm of vector v |
|
a & b |
logical_and(a,b) |
element-by-element AND operator (Numpy ufunc) see note 'LOGICOPS' | |
|
a | b |
logical_or(a,b) |
element-by-element OR operator (Numpy ufunc) see note 'LOGICOPS' | |
|
bitand(a,b) |
a & b |
bitwise AND operator (Python native and Numpy ufunc) | |
|
bitor(a,b) |
a | b |
bitwise OR operator (Python native and Numpy ufunc) | |
|
inv(a) |
linalg.inv(a) |
inverse of square matrix a | |
|
pinv(a) |
linalg.pinv(a) |
pseudo-inverse of matrix a | |
|
rank(a) |
linalg.matrix_rank(a) |
rank of a matrix a | |
|
a\b |
linalg.solve(a,b) if a is square |
solution of a x = b for x | |
|
b/a |
Solve a.T x.T = b.T instead |
solution of x a = b for x | |
|
[U,S,V]=svd(a) |
U, S, Vh = linalg.svd(a), V = Vh.T |
singular value decomposition of a | |
|
chol(a) |
linalg.cholesky(a).T |
cholesky factorization of a matrix (chol(a) in matlab returns an upper triangular matrix, but linalg.cholesky(a) returns a lower triangular matrix) | |
|
[V,D]=eig(a) |
D,V = linalg.eig(a) |
eigenvalues and eigenvectors of a | |
|
[V,D]=eig(a,b) |
V,D = Sci.linalg.eig(a,b) |
eigenvalues and eigenvectors of a,b | |
|
[V,D]=eigs(a,k) |
find the k largest eigenvalues and eigenvectors of a | ||
|
[Q,R,P]=qr(a,0) |
Q,R = Sci.linalg.qr(a) |
mat(...) |
QR decomposition |
|
[L,U,P]=lu(a) |
L,U = Sci.linalg.lu(a) or |
mat(...) |
LU decomposition (note: P(Matlab) == transpose(P(numpy)) ) |
|
conjgrad |
Sci.linalg.cg |
mat(...) |
Conjugate gradients solver |
|
fft(a) |
fft(a) |
mat(...) |
Fourier transform of a |
|
ifft(a) |
ifft(a) |
mat(...) |
inverse Fourier transform of a |
|
sort(a) |
sort(a) or a.sort() |
mat(...) |
sort the matrix |
|
[b,I] = sortrows(a,i) |
I = argsort(a[:,i]), b=a[I,:] |
sort the rows of the matrix | |
|
regress(y,X) |
linalg.lstsq(X,y) |
multilinear regression | |
|
decimate(x, q) |
Sci.signal.resample(x, len(x)/q) |
downsample with low-pass filtering | |
|
unique(a) |
unique(a) |
||
|
squeeze(a) |
a.squeeze() |
||
Submatrix: Assignment to a submatrix can be done with lists of indexes using the ix_ command. E.g., for 2d array a, one might do: ind=[1,3]; a[np.ix_(ind,ind)]+=100.
HELP: There is no direct equivalent of MATLAB's which command, but the commands help and source will usually list the filename where the function is located. Python also has an inspect module (do import inspect) which provides a getfile that often works.
INDEXING: MATLAB® uses one based indexing, so the initial element of a sequence has index 1. Python uses zero based indexing, so the initial element of a sequence has index 0. Confusion and flamewars arise because each has advantages and disadvantages. One based indexing is consistent with common human language usage, where the "first" element of a sequence has index 1. Zero based indexing simplifies indexing. See also a text by prof.dr. Edsger W. Dijkstra.
RANGES: In MATLAB®, 0:5 can be used as both a range literal and a 'slice' index (inside parentheses); however, in Python, constructs like 0:5 can only be used as a slice index (inside square brackets). Thus the somewhat quirky r_ object was created to allow numpy to have a similarly terse range construction mechanism. Note that r_ is not called like a function or a constructor, but rather indexed using square brackets, which allows the use of Python's slice syntax in the arguments.
LOGICOPS: & or | in Numpy is bitwise AND/OR, while in Matlab & and | are logical AND/OR. The difference should be clear to anyone with significant programming experience. The two can appear to work the same, but there are important differences. If you would have used Matlab's & or | operators, you should use the Numpy ufuncs logical_and/logical_or. The notable differences between Matlab's and Numpy's & and | operators are:
Non-logical {0,1} inputs: Numpy's output is the bitwise AND of the inputs. Matlab treats any non-zero value as 1 and returns the logical AND. For example (3 & 4) in Numpy is 0, while in Matlab both 3 and 4 are considered logical true and (3 & 4) returns 1.
Precedence: Numpy's & operator is higher precedence than logical operators like < and >; Matlab's is the reverse.
If you know you have boolean arguments, you can get away with using Numpy's bitwise operators, but be careful with parentheses, like this: z = (x > 1) & (x < 2). The absence of Numpy operator forms of logical_and and logical_or is an unfortunate consequence of Python's design.
RESHAPE and LINEAR INDEXING: Matlab always allows multi-dimensional arrays to be accessed using scalar or linear indices, Numpy does not. Linear indices are common in Matlab programs, e.g. find() on a matrix returns them, whereas Numpy's find behaves differently. When converting Matlab code it might be necessary to first reshape a matrix to a linear sequence, perform some indexing operations and then reshape back. As reshape (usually) produces views onto the same storage, it should be possible to do this fairly efficiently. Note that the scan order used by reshape in Numpy defaults to the 'C' order, whereas Matlab uses the Fortran order. If you are simply converting to a linear sequence and back this doesn't matter. But if you are converting reshapes from Matlab code which relies on the scan order, then this Matlab code: z = reshape(x,3,4); should become z = x.reshape(3,4,order='F').copy() in Numpy.
In MATLAB® the main tool available to you for customizing the environment is to modify the search path with the locations of your favorite functions. You can put such customizations into a startup script that MATLAB will run on startup.
NumPy, or rather Python, has similar facilities.
To modify your Python search path to include the locations of your own modules, define the PYTHONPATH environment variable.
To have a particular script file executed when the interactive Python interpreter is started, define the PYTHONSTARTUP environment variable to contain the name of your startup script.
Unlike MATLAB®, where anything on your path can be called immediately, with Python you need to first do an 'import' statement to make functions in a particular file accessible.
For example you might make a startup script that looks like this (Note: this is just an example, not a statement of "best practices"):
# Make all numpy available via shorter 'num' prefix
import numpy as num
# Make all matlib functions accessible at the top level via M.func()
import numpy.matlib as M
# Make some matlib functions accessible directly at the top level via, e.g. rand(3,3)
from numpy.matlib import rand,zeros,ones,empty,eye
# Define a Hermitian function
def hermitian(A, **kwargs):
return num.transpose(A,**kwargs).conj()
# Make some shorcuts for transpose,hermitian:
# num.transpose(A) --> T(A)
# hermitian(A) --> H(A)
T = num.transpose
H = hermitian
Plotting: matplotlib provides a workalike interface for 2D plotting; Mayavi provides 3D plotting
Symbolic calculation: swiginac appears to be the most complete current option. sympy is a project aiming at bringing the basic symbolic calculus functionalities to Python. Also to be noted is PyDSTool which provides some basic symbolic functionality.
Linear algebra: scipy.linalg provides the LAPACK routines
Interpolation: [/ScipyPackages/Interpolate scipy.interpolate] provides several spline interpolation tools
Numerical integration: scipy.integrate provides several tools for integrating functions as well as some basic ODE integrators. Convert XML vector field specifications automatically using VFGEN.
Dynamical systems: PyDSTool provides a large dynamical systems and modeling package, including good ODE/DAE integrators. Convert XML vector field specifications automatically using VFGEN.
Simulink: no alternative is currently available.
See http://mathesaurus.sf.net/ for another MATLAB®/NumPy cross-reference.
See http://urapiv.wordpress.com for an open-source project (URAPIV) that attempts to move from MATLAB® to Python (PyPIV http://sourceforge.net/projects/pypiv) with SciPy / NumPy.
In order to create a programming environment similar to the one presented by MATLAB®, the following are useful:
IPython: an interactive environment with many features geared towards efficient work in typical scientific usage very similar (with some enhancments) to MATLAB® console.
Matplotlib: a 2D ploting package with a list of commands similar to the ones found in matlab. Matplotlib is very well integrated with IPython.
Spyder a free and open-source Python development environment providing a MATLAB®-like interface and experience
SPE is a good free IDE for python. Has an interactive prompt.
Eclipse: is one nice option for python code editing via the pydev plugin.
Wing IDE: a commercial IDE available for multiple platforms. The professional version has an interactive debugging prompt similar to MATLAB's.
Python(x,y) scientific and engineering development software for numerical computations, data analysis and data visualization. The installation includes, among others, Spyder, Eclipse and a lot of relevant Python modules for scientific computing.
Python Tools for Visual Studio: a rich IDE plugin for Visual Studio that supports CPython, IronPython, the IPython REPL, Debugging, Profiling, including running debugging MPI program on HPC clusters.
An extensive list of tools for scientific work with python is in the link: Topical_Software.
MATLAB® and SimuLink® are registered trademarks of The MathWorks.
CategoryCookbook CategoryTemplate CategoryTemplate CategoryCookbook CategorySciPyPackages CategoryCategory
SciPy: NumPy_for_Matlab_Users (last edited 2015-10-24 17:48:26 by anonymous)
| Deep Learning Lecture Collection (Spring 2017): http://www.youtube.com/playlist?list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv (0) | 2017.08.13 |
|---|---|
| Learn Python in 3 days : Step by Step Guide - Data Science Central (0) | 2017.06.11 |
| Python Numpy Tutorial (0) | 2017.05.29 |
| Videos to learn about AI, Machine Learning & Deep Learning (0) | 2017.05.09 |
| 초짜 대학원생의 입장에서 이해하는 GAN 시리즈 (0) | 2017.04.02 |
This tutorial was contributed by Justin Johnson.
We will use the Python programming language for all assignments in this course. Python is a great general-purpose programming language on its own, but with the help of a few popular libraries (numpy, scipy, matplotlib) it becomes a powerful environment for scientific computing.
We expect that many of you will have some experience with Python and numpy; for the rest of you, this section will serve as a quick crash course both on the Python programming language and on the use of Python for scientific computing.
Some of you may have previous knowledge in Matlab, in which case we also recommend the numpy for Matlab users page.
You can also find an IPython notebook version of this tutorial here created by Volodymyr Kuleshov and Isaac Caswell for CS 228.
Table of contents:
Python is a high-level, dynamically typed multiparadigm programming language. Python code is often said to be almost like pseudocode, since it allows you to express very powerful ideas in very few lines of code while being very readable. As an example, here is an implementation of the classic quicksort algorithm in Python:
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) / 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
print quicksort([3,6,8,10,1,2,1])
# Prints "[1, 1, 2, 3, 6, 8, 10]"
There are currently two different supported versions of Python, 2.7 and 3.4. Somewhat confusingly, Python 3.0 introduced many backwards-incompatible changes to the language, so code written for 2.7 may not work under 3.4 and vice versa. For this class all code will use Python 2.7.
You can check your Python version at the command line by running python --version.
Like most languages, Python has a number of basic types including integers, floats, booleans, and strings. These data types behave in ways that are familiar from other programming languages.
Numbers: Integers and floats work as you would expect from other languages:
x = 3
print type(x) # Prints "<type 'int'>"
print x # Prints "3"
print x + 1 # Addition; prints "4"
print x - 1 # Subtraction; prints "2"
print x * 2 # Multiplication; prints "6"
print x ** 2 # Exponentiation; prints "9"
x += 1
print x # Prints "4"
x *= 2
print x # Prints "8"
y = 2.5
print type(y) # Prints "<type 'float'>"
print y, y + 1, y * 2, y ** 2 # Prints "2.5 3.5 5.0 6.25"
Note that unlike many languages, Python does not have unary increment (x++) or decrement (x--) operators.
Python also has built-in types for long integers and complex numbers; you can find all of the details in the documentation.
Booleans: Python implements all of the usual operators for Boolean logic, but uses English words rather than symbols (&&, ||, etc.):
t = True
f = False
print type(t) # Prints "<type 'bool'>"
print t and f # Logical AND; prints "False"
print t or f # Logical OR; prints "True"
print not t # Logical NOT; prints "False"
print t != f # Logical XOR; prints "True"
Strings: Python has great support for strings:
hello = 'hello' # String literals can use single quotes
world = "world" # or double quotes; it does not matter.
print hello # Prints "hello"
print len(hello) # String length; prints "5"
hw = hello + ' ' + world # String concatenation
print hw # prints "hello world"
hw12 = '%s %s %d' % (hello, world, 12) # sprintf style string formatting
print hw12 # prints "hello world 12"
String objects have a bunch of useful methods; for example:
s = "hello"
print s.capitalize() # Capitalize a string; prints "Hello"
print s.upper() # Convert a string to uppercase; prints "HELLO"
print s.rjust(7) # Right-justify a string, padding with spaces; prints " hello"
print s.center(7) # Center a string, padding with spaces; prints " hello "
print s.replace('l', '(ell)') # Replace all instances of one substring with another;
# prints "he(ell)(ell)o"
print ' world '.strip() # Strip leading and trailing whitespace; prints "world"
You can find a list of all string methods in the documentation.
Python includes several built-in container types: lists, dictionaries, sets, and tuples.
A list is the Python equivalent of an array, but is resizeable and can contain elements of different types:
xs = [3, 1, 2] # Create a list
print xs, xs[2] # Prints "[3, 1, 2] 2"
print xs[-1] # Negative indices count from the end of the list; prints "2"
xs[2] = 'foo' # Lists can contain elements of different types
print xs # Prints "[3, 1, 'foo']"
xs.append('bar') # Add a new element to the end of the list
print xs # Prints "[3, 1, 'foo', 'bar']"
x = xs.pop() # Remove and return the last element of the list
print x, xs # Prints "bar [3, 1, 'foo']"
As usual, you can find all the gory details about lists in the documentation.
Slicing: In addition to accessing list elements one at a time, Python provides concise syntax to access sublists; this is known as slicing:
nums = range(5) # range is a built-in function that creates a list of integers
print nums # Prints "[0, 1, 2, 3, 4]"
print nums[2:4] # Get a slice from index 2 to 4 (exclusive); prints "[2, 3]"
print nums[2:] # Get a slice from index 2 to the end; prints "[2, 3, 4]"
print nums[:2] # Get a slice from the start to index 2 (exclusive); prints "[0, 1]"
print nums[:] # Get a slice of the whole list; prints "[0, 1, 2, 3, 4]"
print nums[:-1] # Slice indices can be negative; prints "[0, 1, 2, 3]"
nums[2:4] = [8, 9] # Assign a new sublist to a slice
print nums # Prints "[0, 1, 8, 9, 4]"
We will see slicing again in the context of numpy arrays.
Loops: You can loop over the elements of a list like this:
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print animal
# Prints "cat", "dog", "monkey", each on its own line.
If you want access to the index of each element within the body of a loop, use the built-in enumerate function:
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):
print '#%d: %s' % (idx + 1, animal)
# Prints "#1: cat", "#2: dog", "#3: monkey", each on its own line
List comprehensions: When programming, frequently we want to transform one type of data into another. As a simple example, consider the following code that computes square numbers:
nums = [0, 1, 2, 3, 4]
squares = []
for x in nums:
squares.append(x ** 2)
print squares # Prints [0, 1, 4, 9, 16]
You can make this code simpler using a list comprehension:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print squares # Prints [0, 1, 4, 9, 16]
List comprehensions can also contain conditions:
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print even_squares # Prints "[0, 4, 16]"
A dictionary stores (key, value) pairs, similar to a Map in Java or an object in Javascript. You can use it like this:
d = {'cat': 'cute', 'dog': 'furry'} # Create a new dictionary with some data
print d['cat'] # Get an entry from a dictionary; prints "cute"
print 'cat' in d # Check if a dictionary has a given key; prints "True"
d['fish'] = 'wet' # Set an entry in a dictionary
print d['fish'] # Prints "wet"
# print d['monkey'] # KeyError: 'monkey' not a key of d
print d.get('monkey', 'N/A') # Get an element with a default; prints "N/A"
print d.get('fish', 'N/A') # Get an element with a default; prints "wet"
del d['fish'] # Remove an element from a dictionary
print d.get('fish', 'N/A') # "fish" is no longer a key; prints "N/A"
You can find all you need to know about dictionaries in the documentation.
Loops: It is easy to iterate over the keys in a dictionary:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:
legs = d[animal]
print 'A %s has %d legs' % (animal, legs)
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
If you want access to keys and their corresponding values, use the iteritems method:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.iteritems():
print 'A %s has %d legs' % (animal, legs)
# Prints "A person has 2 legs", "A cat has 4 legs", "A spider has 8 legs"
Dictionary comprehensions: These are similar to list comprehensions, but allow you to easily construct dictionaries. For example:
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print even_num_to_square # Prints "{0: 0, 2: 4, 4: 16}"
A set is an unordered collection of distinct elements. As a simple example, consider the following:
animals = {'cat', 'dog'}
print 'cat' in animals # Check if an element is in a set; prints "True"
print 'fish' in animals # prints "False"
animals.add('fish') # Add an element to a set
print 'fish' in animals # Prints "True"
print len(animals) # Number of elements in a set; prints "3"
animals.add('cat') # Adding an element that is already in the set does nothing
print len(animals) # Prints "3"
animals.remove('cat') # Remove an element from a set
print len(animals) # Prints "2"
As usual, everything you want to know about sets can be found in the documentation.
Loops: Iterating over a set has the same syntax as iterating over a list; however since sets are unordered, you cannot make assumptions about the order in which you visit the elements of the set:
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print '#%d: %s' % (idx + 1, animal)
# Prints "#1: fish", "#2: dog", "#3: cat"
Set comprehensions: Like lists and dictionaries, we can easily construct sets using set comprehensions:
from math import sqrt
nums = {int(sqrt(x)) for x in range(30)}
print nums # Prints "set([0, 1, 2, 3, 4, 5])"
A tuple is an (immutable) ordered list of values. A tuple is in many ways similar to a list; one of the most important differences is that tuples can be used as keys in dictionaries and as elements of sets, while lists cannot. Here is a trivial example:
d = {(x, x + 1): x for x in range(10)} # Create a dictionary with tuple keys
t = (5, 6) # Create a tuple
print type(t) # Prints "<type 'tuple'>"
print d[t] # Prints "5"
print d[(1, 2)] # Prints "1"
The documentation has more information about tuples.
Python functions are defined using the def keyword. For example:
def sign(x):
if x > 0:
return 'positive'
elif x < 0:
return 'negative'
else:
return 'zero'
for x in [-1, 0, 1]:
print sign(x)
# Prints "negative", "zero", "positive"
We will often define functions to take optional keyword arguments, like this:
def hello(name, loud=False):
if loud:
print 'HELLO, %s!' % name.upper()
else:
print 'Hello, %s' % name
hello('Bob') # Prints "Hello, Bob"
hello('Fred', loud=True) # Prints "HELLO, FRED!"
There is a lot more information about Python functions in the documentation.
The syntax for defining classes in Python is straightforward:
class Greeter(object):
# Constructor
def __init__(self, name):
self.name = name # Create an instance variable
# Instance method
def greet(self, loud=False):
if loud:
print 'HELLO, %s!' % self.name.upper()
else:
print 'Hello, %s' % self.name
g = Greeter('Fred') # Construct an instance of the Greeter class
g.greet() # Call an instance method; prints "Hello, Fred"
g.greet(loud=True) # Call an instance method; prints "HELLO, FRED!"
You can read a lot more about Python classes in the documentation.
Numpy is the core library for scientific computing in Python. It provides a high-performance multidimensional array object, and tools for working with these arrays. If you are already familiar with MATLAB, you might find this tutorial useful to get started with Numpy.
A numpy array is a grid of values, all of the same type, and is indexed by a tuple of nonnegative integers. The number of dimensions is the rank of the array; the shape of an array is a tuple of integers giving the size of the array along each dimension.
We can initialize numpy arrays from nested Python lists, and access elements using square brackets:
import numpy as np
a = np.array([1, 2, 3]) # Create a rank 1 array
print type(a) # Prints "<type 'numpy.ndarray'>"
print a.shape # Prints "(3,)"
print a[0], a[1], a[2] # Prints "1 2 3"
a[0] = 5 # Change an element of the array
print a # Prints "[5, 2, 3]"
b = np.array([[1,2,3],[4,5,6]]) # Create a rank 2 array
print b.shape # Prints "(2, 3)"
print b[0, 0], b[0, 1], b[1, 0] # Prints "1 2 4"
Numpy also provides many functions to create arrays:
import numpy as np
a = np.zeros((2,2)) # Create an array of all zeros
print a # Prints "[[ 0. 0.]
# [ 0. 0.]]"
b = np.ones((1,2)) # Create an array of all ones
print b # Prints "[[ 1. 1.]]"
c = np.full((2,2), 7) # Create a constant array
print c # Prints "[[ 7. 7.]
# [ 7. 7.]]"
d = np.eye(2) # Create a 2x2 identity matrix
print d # Prints "[[ 1. 0.]
# [ 0. 1.]]"
e = np.random.random((2,2)) # Create an array filled with random values
print e # Might print "[[ 0.91940167 0.08143941]
# [ 0.68744134 0.87236687]]"
You can read about other methods of array creation in the documentation.
Numpy offers several ways to index into arrays.
Slicing: Similar to Python lists, numpy arrays can be sliced. Since arrays may be multidimensional, you must specify a slice for each dimension of the array:
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Use slicing to pull out the subarray consisting of the first 2 rows
# and columns 1 and 2; b is the following array of shape (2, 2):
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
# A slice of an array is a view into the same data, so modifying it
# will modify the original array.
print a[0, 1] # Prints "2"
b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1]
print a[0, 1] # Prints "77"
You can also mix integer indexing with slice indexing. However, doing so will yield an array of lower rank than the original array. Note that this is quite different from the way that MATLAB handles array slicing:
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Two ways of accessing the data in the middle row of the array.
# Mixing integer indexing with slices yields an array of lower rank,
# while using only slices yields an array of the same rank as the
# original array:
row_r1 = a[1, :] # Rank 1 view of the second row of a
row_r2 = a[1:2, :] # Rank 2 view of the second row of a
print row_r1, row_r1.shape # Prints "[5 6 7 8] (4,)"
print row_r2, row_r2.shape # Prints "[[5 6 7 8]] (1, 4)"
# We can make the same distinction when accessing columns of an array:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print col_r1, col_r1.shape # Prints "[ 2 6 10] (3,)"
print col_r2, col_r2.shape # Prints "[[ 2]
# [ 6]
# [10]] (3, 1)"
Integer array indexing: When you index into numpy arrays using slicing, the resulting array view will always be a subarray of the original array. In contrast, integer array indexing allows you to construct arbitrary arrays using the data from another array. Here is an example:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
# An example of integer array indexing.
# The returned array will have shape (3,) and
print a[[0, 1, 2], [0, 1, 0]] # Prints "[1 4 5]"
# The above example of integer array indexing is equivalent to this:
print np.array([a[0, 0], a[1, 1], a[2, 0]]) # Prints "[1 4 5]"
# When using integer array indexing, you can reuse the same
# element from the source array:
print a[[0, 0], [1, 1]] # Prints "[2 2]"
# Equivalent to the previous integer array indexing example
print np.array([a[0, 1], a[0, 1]]) # Prints "[2 2]"
One useful trick with integer array indexing is selecting or mutating one element from each row of a matrix:
import numpy as np
# Create a new array from which we will select elements
a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
print a # prints "array([[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9],
# [10, 11, 12]])"
# Create an array of indices
b = np.array([0, 2, 0, 1])
# Select one element from each row of a using the indices in b
print a[np.arange(4), b] # Prints "[ 1 6 7 11]"
# Mutate one element from each row of a using the indices in b
a[np.arange(4), b] += 10
print a # prints "array([[11, 2, 3],
# [ 4, 5, 16],
# [17, 8, 9],
# [10, 21, 12]])
Boolean array indexing: Boolean array indexing lets you pick out arbitrary elements of an array. Frequently this type of indexing is used to select the elements of an array that satisfy some condition. Here is an example:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
bool_idx = (a > 2) # Find the elements of a that are bigger than 2;
# this returns a numpy array of Booleans of the same
# shape as a, where each slot of bool_idx tells
# whether that element of a is > 2.
print bool_idx # Prints "[[False False]
# [ True True]
# [ True True]]"
# We use boolean array indexing to construct a rank 1 array
# consisting of the elements of a corresponding to the True values
# of bool_idx
print a[bool_idx] # Prints "[3 4 5 6]"
# We can do all of the above in a single concise statement:
print a[a > 2] # Prints "[3 4 5 6]"
For brevity we have left out a lot of details about numpy array indexing; if you want to know more you should read the documentation.
Every numpy array is a grid of elements of the same type. Numpy provides a large set of numeric datatypes that you can use to construct arrays. Numpy tries to guess a datatype when you create an array, but functions that construct arrays usually also include an optional argument to explicitly specify the datatype. Here is an example:
import numpy as np
x = np.array([1, 2]) # Let numpy choose the datatype
print x.dtype # Prints "int64"
x = np.array([1.0, 2.0]) # Let numpy choose the datatype
print x.dtype # Prints "float64"
x = np.array([1, 2], dtype=np.int64) # Force a particular datatype
print x.dtype # Prints "int64"
You can read all about numpy datatypes in the documentation.
Basic mathematical functions operate elementwise on arrays, and are available both as operator overloads and as functions in the numpy module:
import numpy as np
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# Elementwise sum; both produce the array
# [[ 6.0 8.0]
# [10.0 12.0]]
print x + y
print np.add(x, y)
# Elementwise difference; both produce the array
# [[-4.0 -4.0]
# [-4.0 -4.0]]
print x - y
print np.subtract(x, y)
# Elementwise product; both produce the array
# [[ 5.0 12.0]
# [21.0 32.0]]
print x * y
print np.multiply(x, y)
# Elementwise division; both produce the array
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print x / y
print np.divide(x, y)
# Elementwise square root; produces the array
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print np.sqrt(x)
Note that unlike MATLAB, * is elementwise multiplication, not matrix multiplication. We instead use the dot function to compute inner products of vectors, to multiply a vector by a matrix, and to multiply matrices. dot is available both as a function in the numpy module and as an instance method of array objects:
import numpy as np
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
v = np.array([9,10])
w = np.array([11, 12])
# Inner product of vectors; both produce 219
print v.dot(w)
print np.dot(v, w)
# Matrix / vector product; both produce the rank 1 array [29 67]
print x.dot(v)
print np.dot(x, v)
# Matrix / matrix product; both produce the rank 2 array
# [[19 22]
# [43 50]]
print x.dot(y)
print np.dot(x, y)
Numpy provides many useful functions for performing computations on arrays; one of the most useful is sum:
import numpy as np
x = np.array([[1,2],[3,4]])
print np.sum(x) # Compute sum of all elements; prints "10"
print np.sum(x, axis=0) # Compute sum of each column; prints "[4 6]"
print np.sum(x, axis=1) # Compute sum of each row; prints "[3 7]"
You can find the full list of mathematical functions provided by numpy in the documentation.
Apart from computing mathematical functions using arrays, we frequently need to reshape or otherwise manipulate data in arrays. The simplest example of this type of operation is transposing a matrix; to transpose a matrix, simply use the T attribute of an array object:
import numpy as np
x = np.array([[1,2], [3,4]])
print x # Prints "[[1 2]
# [3 4]]"
print x.T # Prints "[[1 3]
# [2 4]]"
# Note that taking the transpose of a rank 1 array does nothing:
v = np.array([1,2,3])
print v # Prints "[1 2 3]"
print v.T # Prints "[1 2 3]"
Numpy provides many more functions for manipulating arrays; you can see the full list in the documentation.
Broadcasting is a powerful mechanism that allows numpy to work with arrays of different shapes when performing arithmetic operations. Frequently we have a smaller array and a larger array, and we want to use the smaller array multiple times to perform some operation on the larger array.
For example, suppose that we want to add a constant vector to each row of a matrix. We could do it like this:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # Create an empty matrix with the same shape as x
# Add the vector v to each row of the matrix x with an explicit loop
for i in range(4):
y[i, :] = x[i, :] + v
# Now y is the following
# [[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]
print y
This works; however when the matrix x is very large, computing an explicit loop in Python could be slow. Note that adding the vector v to each row of the matrix x is equivalent to forming a matrix vv by stacking multiple copies of v vertically, then performing elementwise summation of x and vv. We could implement this approach like this:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
vv = np.tile(v, (4, 1)) # Stack 4 copies of v on top of each other
print vv # Prints "[[1 0 1]
# [1 0 1]
# [1 0 1]
# [1 0 1]]"
y = x + vv # Add x and vv elementwise
print y # Prints "[[ 2 2 4
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
Numpy broadcasting allows us to perform this computation without actually creating multiple copies of v. Consider this version, using broadcasting:
import numpy as np
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # Add v to each row of x using broadcasting
print y # Prints "[[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
The line y = x + v works even though x has shape (4, 3) and v has shape (3,) due to broadcasting; this line works as if v actually had shape (4, 3), where each row was a copy of v, and the sum was performed elementwise.
Broadcasting two arrays together follows these rules:
If this explanation does not make sense, try reading the explanation from the documentation or this explanation.
Functions that support broadcasting are known as universal functions. You can find the list of all universal functions in the documentation.
Here are some applications of broadcasting:
import numpy as np
# Compute outer product of vectors
v = np.array([1,2,3]) # v has shape (3,)
w = np.array([4,5]) # w has shape (2,)
# To compute an outer product, we first reshape v to be a column
# vector of shape (3, 1); we can then broadcast it against w to yield
# an output of shape (3, 2), which is the outer product of v and w:
# [[ 4 5]
# [ 8 10]
# [12 15]]
print np.reshape(v, (3, 1)) * w
# Add a vector to each row of a matrix
x = np.array([[1,2,3], [4,5,6]])
# x has shape (2, 3) and v has shape (3,) so they broadcast to (2, 3),
# giving the following matrix:
# [[2 4 6]
# [5 7 9]]
print x + v
# Add a vector to each column of a matrix
# x has shape (2, 3) and w has shape (2,).
# If we transpose x then it has shape (3, 2) and can be broadcast
# against w to yield a result of shape (3, 2); transposing this result
# yields the final result of shape (2, 3) which is the matrix x with
# the vector w added to each column. Gives the following matrix:
# [[ 5 6 7]
# [ 9 10 11]]
print (x.T + w).T
# Another solution is to reshape w to be a column vector of shape (2, 1);
# we can then broadcast it directly against x to produce the same
# output.
print x + np.reshape(w, (2, 1))
# Multiply a matrix by a constant:
# x has shape (2, 3). Numpy treats scalars as arrays of shape ();
# these can be broadcast together to shape (2, 3), producing the
# following array:
# [[ 2 4 6]
# [ 8 10 12]]
print x * 2
Broadcasting typically makes your code more concise and faster, so you should strive to use it where possible.
This brief overview has touched on many of the important things that you need to know about numpy, but is far from complete. Check out the numpy reference to find out much more about numpy.
Numpy provides a high-performance multidimensional array and basic tools to compute with and manipulate these arrays. SciPy builds on this, and provides a large number of functions that operate on numpy arrays and are useful for different types of scientific and engineering applications.
The best way to get familiar with SciPy is to browse the documentation. We will highlight some parts of SciPy that you might find useful for this class.
SciPy provides some basic functions to work with images. For example, it has functions to read images from disk into numpy arrays, to write numpy arrays to disk as images, and to resize images. Here is a simple example that showcases these functions:
from scipy.misc import imread, imsave, imresize
# Read an JPEG image into a numpy array
img = imread('assets/cat.jpg')
print img.dtype, img.shape # Prints "uint8 (400, 248, 3)"
# We can tint the image by scaling each of the color channels
# by a different scalar constant. The image has shape (400, 248, 3);
# we multiply it by the array [1, 0.95, 0.9] of shape (3,);
# numpy broadcasting means that this leaves the red channel unchanged,
# and multiplies the green and blue channels by 0.95 and 0.9
# respectively.
img_tinted = img * [1, 0.95, 0.9]
# Resize the tinted image to be 300 by 300 pixels.
img_tinted = imresize(img_tinted, (300, 300))
# Write the tinted image back to disk
imsave('assets/cat_tinted.jpg', img_tinted)


The functions scipy.io.loadmat and scipy.io.savemat allow you to read and write MATLAB files. You can read about them in the documentation.
SciPy defines some useful functions for computing distances between sets of points.
The function scipy.spatial.distance.pdist computes the distance between all pairs of points in a given set:
import numpy as np
from scipy.spatial.distance import pdist, squareform
# Create the following array where each row is a point in 2D space:
# [[0 1]
# [1 0]
# [2 0]]
x = np.array([[0, 1], [1, 0], [2, 0]])
print x
# Compute the Euclidean distance between all rows of x.
# d[i, j] is the Euclidean distance between x[i, :] and x[j, :],
# and d is the following array:
# [[ 0. 1.41421356 2.23606798]
# [ 1.41421356 0. 1. ]
# [ 2.23606798 1. 0. ]]
d = squareform(pdist(x, 'euclidean'))
print d
You can read all the details about this function in the documentation.
A similar function (scipy.spatial.distance.cdist) computes the distance between all pairs across two sets of points; you can read about it in the documentation.
Matplotlib is a plotting library. In this section give a brief introduction to the matplotlib.pyplot module, which provides a plotting system similar to that of MATLAB.
The most important function in matplotlib is plot, which allows you to plot 2D data. Here is a simple example:
import numpy as np
import matplotlib.pyplot as plt
# Compute the x and y coordinates for points on a sine curve
x = np.arange(0, 3 * np.pi, 0.1)
y = np.sin(x)
# Plot the points using matplotlib
plt.plot(x, y)
plt.show() # You must call plt.show() to make graphics appear.
Running this code produces the following plot:
With just a little bit of extra work we can easily plot multiple lines at once, and add a title, legend, and axis labels:
import numpy as np
import matplotlib.pyplot as plt
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Plot the points using matplotlib
plt.plot(x, y_sin)
plt.plot(x, y_cos)
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Sine and Cosine')
plt.legend(['Sine', 'Cosine'])
plt.show()
You can read much more about the plot function in the documentation.
You can plot different things in the same figure using the subplot function. Here is an example:
import numpy as np
import matplotlib.pyplot as plt
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Set up a subplot grid that has height 2 and width 1,
# and set the first such subplot as active.
plt.subplot(2, 1, 1)
# Make the first plot
plt.plot(x, y_sin)
plt.title('Sine')
# Set the second subplot as active, and make the second plot.
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')
# Show the figure.
plt.show()
You can read much more about the subplot function in the documentation.
You can use the imshow function to show images. Here is an example:
import numpy as np
from scipy.misc import imread, imresize
import matplotlib.pyplot as plt
img = imread('assets/cat.jpg')
img_tinted = img * [1, 0.95, 0.9]
# Show the original image
plt.subplot(1, 2, 1)
plt.imshow(img)
# Show the tinted image
plt.subplot(1, 2, 2)
# A slight gotcha with imshow is that it might give strange results
# if presented with data that is not uint8. To work around this, we
# explicitly cast the image to uint8 before displaying it.
plt.imshow(np.uint8(img_tinted))
plt.show()

| Learn Python in 3 days : Step by Step Guide - Data Science Central (0) | 2017.06.11 |
|---|---|
| NumPy for Matlab Users (0) | 2017.05.29 |
| Videos to learn about AI, Machine Learning & Deep Learning (0) | 2017.05.09 |
| 초짜 대학원생의 입장에서 이해하는 GAN 시리즈 (0) | 2017.04.02 |
| cs231n cs224d 한국어 강의동영상 ,고려대학교 산업경영공학부 Data Science & Business Analytics 연구실 (0) | 2017.04.02 |
http://www.ninadthakoor.com/2016/07/25/getting-started-with-matconvnet/
Available at: http://www.vlfeat.org/matconvnet/
My goal is to use this toolbox to classify cars into four classes: Sedan, Minivan, SUV and pickup. I already have the data from my prior work (http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6558793).
My plan is to first use transfer learning i. e. to use one of the deep networks pre-trained with imagenet data to extract features and use an SVM classifier to do the actual classification. I plan to do this with Matlab 2016a on Windows 10 PC equipped with GeForce GTX 960. I am aware that Matlab also has deep learning support in its Neural Network toolbox, I am going with MatConNet in hopes that it will stay more cutting edge.
The code below is derived from http://www.mathworks.com/company/newsletters/articles/deep-learning-for-computer-vision-with-matlab.html and http://www.vlfeat.org/matconvnet/quick/
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64 |
clear; close all; clc;%Load the pre-trained netnet = load('imagenet-vgg-f.mat');net = vl_simplenn_tidy(net) ;%Remove the last layer (softmax layer)net.layers = net.layers(1 : end - 1);%% This deals with reading the data and getting the ground truth class labels%All files are are inside the root root = 'C:\Users\ninad\Dropbox\Ninad\Lasagne\data\c200x200\';Files = dir(fullfile(root, '*.bmp'));%Load the map which stores the class informationload MakeModels.matfor i = 1 : length(Files) waitbar (i/ length(Files)); % Read class from the map Q = Files(i).name(end - 18 : end - 4); Qout = MakeModels(Q); Files(i).class = Qout.Type; % Preprocess the data and get it ready for the CNN im = imread(fullfile(root, Files(i).name)); im_ = single(im); % note: 0-255 range im_ = imresize(im_, net.meta.normalization.imageSize(1:2)); im_ = bsxfun(@minus, im_, net.meta.normalization.averageImage); % run the CNN to compute the features feats = vl_simplenn(net, im_) ; Files(i).feats = squeeze(feats(end).x);end%% Classifier training%Select training data fractiontrainFraction = 0.5;randomsort = randperm(length(Files));trainSamples = randomsort(1 : trainFraction * length(Files));testSamples = randomsort(trainFraction * length(Files)+1 : end);Labels = [Files.class];Features = [Files.feats];trainingFeatures = Features( :, trainSamples);trainingLabels = Labels( :, trainSamples);classifier = fitcecoc(trainingFeatures', trainingLabels);%% Carry out the validation with rest of the datatestFeatures = Features( :, testSamples);testLabels = Labels( :, testSamples);predictedLabels = predict(classifier, testFeatures');confMat = confusionmat(testLabels, predictedLabels);% Convert confusion matrix into percentage formconfMat = bsxfun(@rdivide,confMat,sum(confMat,2))% Display the mean accuracymean(diag(confMat)) |
| How to generate confusion matrix in MatConvNet (0) | 2017.05.15 |
|---|---|
| assertition failed vl_simplenn.m (0) | 2017.05.13 |
https://groups.google.com/forum/#!topic/matconvnet/m2BPIPVxB5o
I've used imagenet pretrained model for training my dataset. Here is my code:
net = load('YourTrainedModel.mat');
mdl.classes = net.net_classes;
mdl.layers = net.net_layers;
mdl.layers{end}.type = 'softmax';
ds=load('YourDataSet.mat');
trainSet = [ones(1,numel(ds.y2)) 3*ones(1,numel(ds.y2))];
data = single(reshape(cat(4,ds.x1,ds.
dataMean = mean(data(:,:,:,trainSet == 1), 4);
testSize = size(ds.y2,2);
confMat = zeros(numOfClasses, numOfClasses);
i=1;
while i<=testSize
im=ds.x2(:,:,:,i);
im_ = single(im);
im_=im_-dataMean;
res = vl_simplenn(mdl, im_) ;
scores1= squeeze(gather(res(end).x)) ;
[bestScore, best] = max(scores);
confMat(ds.y2(1,i),best) = confMat(ds.y2(1,i),best)+1;
i = i+1;
end
for i=1:numOfClasses
s = sum(confMat(i,:));
for j=1:numOfClasses
confMat(i,j) = confMat(i,j)/s*100;
end
end
| matconvnet 테스트 이미지에 딥러닝모델 적용하고, 피쳐 뽑아 SVM으로 분류하는 예제 (1) | 2017.05.15 |
|---|---|
| assertition failed vl_simplenn.m (0) | 2017.05.13 |
https://youtu.be/TFpStiC2wDg
| #How to install caffe in windows in just 5 minutes !YouTube - Jun 3, 2017 (0) | 2017.07.25 |
|---|---|
| Caffe 윈도우 설치하기 (0) | 2017.07.25 |
| How to Install TensorFlow | NVIDIA (0) | 2017.03.28 |
| tensorflow install & pycharm install & setting (0) | 2017.03.25 |
| Ubuntu 16.04LTS + TensorFlow + Cuda + Cudnn + Pycharm + Anaconda (0) | 2017.03.25 |
https://github.com/vlfeat/matconvnet/issues/34
StevenLOL commented
|
Hi, when you train a model, as a last layer there is usually the However, in general when you want to obtain only class probabilities, you simply change the last layer type to: And now your call of |
|
Thanks, the best CNN toolkit ever. |
| matconvnet 테스트 이미지에 딥러닝모델 적용하고, 피쳐 뽑아 SVM으로 분류하는 예제 (1) | 2017.05.15 |
|---|---|
| How to generate confusion matrix in MatConvNet (0) | 2017.05.15 |
| NumPy for Matlab Users (0) | 2017.05.29 |
|---|---|
| Python Numpy Tutorial (0) | 2017.05.29 |
| 초짜 대학원생의 입장에서 이해하는 GAN 시리즈 (0) | 2017.04.02 |
| cs231n cs224d 한국어 강의동영상 ,고려대학교 산업경영공학부 Data Science & Business Analytics 연구실 (0) | 2017.04.02 |
| From the basics to slightly more interesting applications of Tensorflow (0) | 2017.03.27 |
| PyTorch Tutorial (0) | 2017.05.13 |
|---|---|
| TensorFlow Tutorial #16 Reinforcement Learning (0) | 2017.04.24 |
| How to Use Timesteps in LSTM Networks for Time Series Forecasting - Machine Learning Mastery (0) | 2017.04.17 |
| Deep learning for satellite imagery via image segmentation | deepsense.io (0) | 2017.04.14 |
| RUBEDO: How to build and run your first deep learning network (0) | 2017.04.14 |
SNU TF 스터디 모임
위의 링크로 들어가시면 1기 때부터 쭉 모아온 발표자료들이 올라와있으니 자유롭게 다운받으실 수 있습니다. (앞으로도 계속 업데이트될 예정입니다.^^) 그리고 혹시나 스터디 관련한 문의가 있으시면 댓글 또는 저한테 말씀해주세요. ![]() :)
:)
그럼 모두 좋은 하루 되시기 바랍니다. 감사합니다! ![]()
| 30개의 필수 데이터과학, 머신러닝, 딥러닝 치트시트 (0) | 2017.09.26 |
|---|---|
| 데이터과학 및 딥러닝을 위한 데이터세트 (0) | 2017.07.04 |
| Beginning Machine Learning – A few Resources [Subjective] (0) | 2017.06.20 |
| List of Free Must-Read Books for Machine Learning (0) | 2017.04.06 |
| Regularization resources in matlab (0) | 2017.04.05 |
| NVIDIA Research Unveils Flowtron, an Expressive and Natural Speech Synthesis Mod (0) | 2020.05.15 |
|---|---|
| 수학을 포기한 직업 프로그래머가 머신러닝 학습을 시작하기위한 학습법 소개 (0) | 2017.07.27 |
| Why Momentum Really Works (0) | 2017.04.05 |
| What is the best probabilistic graphical model toolkit for MATLAB? (0) | 2017.03.19 |
| 스마트폰에서 딥러닝 실행방법-Squeezing Deep Learning into Mobile Phones - A Practitioner's guide (0) | 2017.03.18 |
What better way to enjoy this spring weather than with some free machine learning and data science ebooks? Right? Right?
Here is a quick collection of such books to start your fair weather study off on the right foot. The list begins with a base of statistics, moves on to machine learning foundations, progresses to a few bigger picture titles, has a quick look at an advanced topic or 2, and ends off with something that brings it all together. A mix of classic and contemporary titles, hopefully you find something new (to you) and of interest here.

1. Think Stats: Probability and Statistics for Programmers
By Allen B. Downey
Think Stats is an introduction to Probability and Statistics for Python programmers.
Think Stats emphasizes simple techniques you can use to explore real data sets and answer interesting questions. The book presents a case study using data from the National Institutes of Health. Readers are encouraged to work on a project with real datasets.
2. Probabilistic Programming & Bayesian Methods for Hackers
By Cam Davidson-Pilon
An intro to Bayesian methods and probabilistic programming from a computation/understanding-first, mathematics-second point of view.
The Bayesian method is the natural approach to inference, yet it is hidden from readers behind chapters of slow, mathematical analysis. The typical text on Bayesian inference involves two to three chapters on probability theory, then enters what Bayesian inference is. Unfortunately, due to mathematical intractability of most Bayesian models, the reader is only shown simple, artificial examples. This can leave the user with a so-what feeling about Bayesian inference. In fact, this was the author's own prior opinion.
3. Understanding Machine Learning: From Theory to Algorithms
By Shai Shalev-Shwartz and Shai Ben-David
Machine learning is one of the fastest growing areas of computer science, with far-reaching applications. The aim of this textbook is to introduce machine learning, and the algorithmic paradigms it offers, in a principled way. The book provides a theoretical account of the fundamentals underlying machine learning and the mathematical derivations that transform these principles into practical algorithms. Following a presentation of the basics, the book covers a wide array of central topics unaddressed by previous textbooks. These include a discussion of the computational complexity of learning and the concepts of convexity and stability; important algorithmic paradigms including stochastic gradient descent, neural networks, and structured output learning; and emerging theoretical concepts such as the PAC-Bayes approach and compression-based bounds.
4. The Elements of Statistical Learning
By Trevor Hastie, Robert Tibshirani and Jerome Friedman
This book descibes the important ideas in these areas in a common conceptual framework. While the approach is statistical, the emphasis is on concepts rather than mathematics. Many examples are given, with a liberal use of color graphics. It should be a valuable resource for statisticians and anyone interested in data mining in science or industry. The book's coverage is broad, from supervised learning (prediction) to unsupervised learning. The many topics include neural networks, support vector machines, classification trees and boosting--the first comprehensive treatment of this topic in any book.
5. An Introduction to Statistical Learning with Applications in R
By Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani
This book provides an introduction to statistical learning methods. It is aimed for upper level undergraduate students, masters students and Ph.D. students in the non-mathematical sciences. The book also contains a number of R labs with detailed explanations on how to implement the various methods in real life settings, and should be a valuable resource for a practicing data scientist.
6. Foundations of Data Science
By Avrim Blum, John Hopcroft, and Ravindran Kannan
While traditional areas of computer science remain highly important, increasingly researchers of the future will be involved with using computers to understand and extract usable information from massive data arising in applications, not just how to make computers useful on specific well-defined problems. With this in mind we have written this book to cover the theory likely to be useful in the next 40 years, just as an understanding of automata theory, algorithms, and related topics gave students an advantage in the last 40 years.
7. A Programmer's Guide to Data Mining: The Ancient Art of the Numerati
By Ron Zacharski
This guide follows a learn-by-doing approach. Instead of passively reading the book, I encourage you to work through the exercises and experiment with the Python code I provide. I hope you will be actively involved in trying out and programming data mining techniques. The textbook is laid out as a series of small steps that build on each other until, by the time you complete the book, you have laid the foundation for understanding data mining techniques.
8. Mining of Massive Datasets
By Jure Leskovec, Anand Rajaraman and Jeff Ullman
The book is based on Stanford Computer Science course CS246: Mining Massive Datasets (and CS345A: Data Mining).
The book, like the course, is designed at the undergraduate computer science level with no formal prerequisites. To support deeper explorations, most of the chapters are supplemented with further reading references.
9. Deep Learning
By Ian Goodfellow, Yoshua Bengio and Aaron Courville
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free.
10. Machine Learning Yearning
By Andrew Ng
AI, Machine Learning and Deep Learning are transforming numerous industries. But building a machine learning system requires that you make practical decisions:
- Should you collect more training data?
- Should you use end-to-end deep learning?
- How do you deal with your training set not matching your test set?
- and many more.
Historically, the only way to learn how to make these "strategy" decisions has been a multi-year apprenticeship in a graduate program or company. I am writing a book to help you quickly gain this skill, so that you can become better at building AI systems.
| Deep learning for satellite imagery via image segmentation | deepsense.io (0) | 2017.04.14 |
|---|---|
| RUBEDO: How to build and run your first deep learning network (0) | 2017.04.14 |
| speech-to-text called DeepSpeech 소스코드 논문 (0) | 2017.04.08 |
| 10 minutes Practical TensorFlow Tutorial for quick learners (0) | 2017.04.08 |
| How Deep Neural Networks Work 동영상 강좌 24:37 (0) | 2017.04.05 |



|
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |

Hi,
After run cnn_mnist.m, I have few net-epoch-n.mat models.
To predict one image on mnist , following the example in http://www.vlfeat.org/matconvnet/pretrained
When calling
net=load('./data/mnist-baseline/net-epoch-5.mat');
res=vl_simplenn(net.net, im); % im is just one mnist image whose size is 28*28
I got the error:
Error using vl_nnsoftmaxloss (line 42) Assertion failed.
Error in vl_simplenn (line 164)
res(i+1).x = vl_nnsoftmaxloss(res(i).x, l.class) ;