Recently, I am trying to using Matlab build-in neural networks toolbox to accomplish my classification problem. However, I have some questions about the parameter settings.
a. The number of neurons in the hidden layer:
The example on this pageMatlab neural networks classification exampleshows a two-layer (i.e. one-hidden-layer and one-output-layer) feed forward neural networks. In this example, it uses 10 neurons in the hidden layer
net=patternnet(10);
My first question is how to define the best number of neurons for my classification problem? Should I use cross-validation method to get the best performed number of neurons using a training data set?
b. Is there a method to choose three-layer or more multi-layer neural networks?
c. There are many different training method we can use in the neural networks toolbox. A list can be found atTraining methods list. The page mentioned that the fastest training function is generally 'trainlm'; however, generally speaking, which one will perform best? Or it totally depends on the data set I am using?
d. In each training method, there is a parameter called 'epochs', which is the training iteration for my understanding. For each training method, Matlab defined the maximum number of epochs to train. However, from theexample, it seems like 'epochs' is another parameter we can tune. Am I right? Or we just set the maximum number of epochs or leave it as default?
Any experience with Matlab neural networks toolbox is welcome and thanks very much for your reply. A.
b. Refer toftp://ftp.sas.com/pub/neural/FAQ3.html#A_hl And for more layers of neural network, you can refer toDeep Learning, which is very hot in recent years and gets state-of-the-art performances in many of the pattern recognition tasks.
c. It depends on your data. trainlm performs better on function fitting (nonlinear regression) problems than on pattern recognition problems while training large networks and pattern recognition networks, trainscg and trainrp are good choices. Generally, Gradient Descent and Resilient Backpropagation is recommended. More detailed comparison can be found here:http://www.mathworks.cn/cn/help/nnet/ug/choose-a-multilayer-neural-network-training-function.html
d. Yes, you're right. We can tune the epochs parameter. Generally you can output the recognition results/accuracy at every epoch and you will see that it is promoting more and more slowly, and the more epochs the more computing time. You can make a compromise between the accuracy and computation time.
논문은 랜덤한 점들을 모두 한번씩만 방문하고 출발 도시로 돌아오는 최단 거리를 찾는 Travelling Salesman Problem(TSP)처럼 입력 값에서 정해진 순서로 답을 찾아야 하는 문제를 풀 수 있는 모델을 제안했습니다.
2015년 6월에 arxiv에 올라온 논문이지만 굉장히 유용한 모델 중 하나라 생각되어 구현하게 되었습니다. 이번에는 I/O 시간을 최소화 하기 위해서 멀티스레드로 데이터 큐를 따로 두어 TensorFlow graph의 실행이 I/O에 방해받지 않도록 구현했습니다.
===
그리고 제가 현재 학사 병특 중인 데브시스터즈에서 함께 일할 머신러닝 리서쳐를 찾고 있습니다 :)
저희 회사에서는 강화학습, Computer vision, NLP 등 자신이 풀고자 하는 문제를 자유롭게 정하고 논문 세미나와 코드 구현을 통해서 팀의 역량을 키워나가고 있습니다. 관심이 있으신 분들은 언제든지 연락주세요!
지원 방법 : http://www.devsisters.com/jobs 채용 문의 : career@devsisters.com
저희 팀의 외부 발표자료 및 오픈소스 프로젝트를 공유합니다.
- 딥러닝과 강화 학습으로 나보다 잘하는 쿠키런 AI 구현하기 http://www.slideshare.net/carpedm20/ai-67616630 - 텐서플로우 설치도 했고 튜토리얼도 봤고 기초 예제도 짜봤다면 http://www.slideshare.net/carpedm20/ss-63116251 - 지적 대화를 위한 깊고 넓은 딥러닝 http://www.slideshare.net/carpedm20/pycon-korea-2016 - 강화 학습 기초 http://www.slideshare.net/carpedm20/reinforcement-learning-an-introduction-64037079
- 애플의 Simulated+Unsupervised (S+U) learning 구현 https://github.com/carpedm20/simulated-unsupervised-tensorflow - Neural Combinatorial Optimization 구현 https://github.com/devsisters/neural-combinatorial-rl-tensorflow - Deep Q-network 구현 https://github.com/devsisters/DQN-tensorflow
[PRML 3.1~3.2] Linear Regression / Bias-Variance Decomposition
Linear Regression에서 Least Square Error를 사용하는 수학적인 근거를 확률적인 접근에서부터 유도하고, 나아가 Regularizer의 의미와 Bias-Variance Decomposition을 이용한 Regression모델의 Overfitting 분석에 대해서 주로 다루었습니다.
앞으로 몇 챕터 더 세미나를 발표할 예정이고, 해당 동영상은 제가 올린 링크의 플레이리스트에 계속 업로드됩니다~ 감사합니다. https://www.youtube.com/watch?v=dt8RvYEOrWw&list=PLzWH6Ydh35ggVGbBh48TNs635gv2nxkFI&sns=em
When doing regression or classification, what is the correct (or better) way to preprocess the data?
Normalize the data -> PCA -> training
PCA -> normalize PCA output -> training
Normalize the data -> PCA -> normalize PCA output -> training
Which of the above is more correct, or is the "standardized" way to preprocess the data? By "normalize" I mean either standardization, linear scaling or some other techniques.
------------
You should normalize the data before doing PCA. For example, consider the following situation. I create a data set X with a known correlation matrix C:
>> C = [1 0.5; 0.5 1];
>> A = chol(rho);
>> X = randn(100,2) * A;
If I now perform PCA, I correctly find that the principal components (the rows of the weights vector) are oriented at an angle to the coordinate axes:
>> wts=pca(X)
wts =
0.6659 0.7461
-0.7461 0.6659
If I now scale the first feature of the data set by 100, intuitively we think that the principal components shouldn't change:
>> Y = X;
>> Y(:,1) = 100 * Y(:,1);
However, we now find that the principal components are aligned with the coordinate axes:
>> wts=pca(Y)
wts =
1.0000 0.0056
-0.0056 1.0000
To resolve this, there are two options. First, I could rescale the data:
>> Ynorm = bsxfun(@rdivide,Y,std(Y))
(The weird bsxfun notation is used to do vector-matrix arithmetic in Matlab - all I'm doing is subtracting the mean and dividing by the standard deviation of each feature).
They're slightly different to the PCA on the original data because we've now guaranteed that our features have unit standard deviation, which wasn't the case originally.
The other option is to perform PCA using the correlation matrix of the data, instead of the outer product:
In fact this is completely equivalent to standardizing the date by subtracting the mean and then dividing by the standard deviation. It's just more convenient. In my opinion you should always do this unless you have a good reason not to (e.g. if you want to pick up differences in the variation of each feature).
GPU-accelerated Theano & Keras on Windows 10 native
>> LAST UPDATED JANUARY, 2017 <<
There are certainly a lot of guides to assist you build great deep learning (DL) setups on Linux or Mac OS (including with Tensorflow which, unfortunately, as of this posting, cannot be easily installed on Windows), but few care about building an efficient Windows 10-native setup. Most focus on running an Ubuntu VM hosted on Windows or using Docker, unnecessary - and ultimately sub-optimal - steps.
We also found enough misguiding/deprecated information out there to make it worthwhile putting together a step-by-step guide for the latest stable versions of Theano and Keras. Used together, they make for one of the simplest and fastest DL configurations to work natively on Windows.
If you must run your DL setup on Windows 10, then the information contained here may be useful to you.
Dependencies
Here's a summary list of the tools and libraries we use for deep learning on Windows 10 (Version 1607 OS Build 14393.222):
Visual Studio 2015 Community Edition Update 3 w. Windows Kit 10.0.10240.0
Used for its C/C++ compiler (not its IDE) and SDK
Anaconda (64-bit) w. Python 2.7 (Anaconda2-4.2.0) or Python 3.5 (Anaconda3-4.2.0)
A Python distro that gives us NumPy, SciPy, and other scientific libraries
CUDA 8.0.44 (64-bit)
Used for its GPU math libraries, card driver, and CUDA compiler
MinGW-w64 (5.4.0)
Used for its Unix-like compiler and build tools (g++/gcc, make...) for Windows
Theano 0.8.2
Used to evaluate mathematical expressions on multi-dimensional arrays
Keras 1.1.0
Used for deep learning on top of Theano
OpenBLAS 0.2.14 (Optional)
Used for its CPU-optimized implementation of many linear algebra operations
cuDNN v5.1 (August 10, 2016) for CUDA 8.0 (Conditional)
Used to run vastly faster convolution neural networks
For an older setup using VS2013 and CUDA 7.5, please refer to README-2016-07.md (July, 2016 setup)
We like to keep our toolkits and libraries in a single root folder boringly called c:\toolkits, so whenever you see a Windows path that starts with c:\toolkits below, make sure to replace it with whatever you decide your own toolkit drive and folder ought to be.
Visual Studio 2015 Community Edition Update 3 w. Windows Kit 10.0.10240.0
You can download Visual Studio 2015 Community Edition from here:
Select the executable and let it decide what to download on its own:
Run the downloaded executable to install Visual Studio, using whatever additional config settings work best for you:
Add C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin to your PATH, based on where you installed VS 2015.
Define sysenv variable INCLUDE with the value C:\Program Files (x86)\Windows Kits\10\Include\10.0.10240.0\ucrt
Define sysenv variable LIB with the value C:\Program Files (x86)\Windows Kits\10\Lib\10.0.10240.0\um\x64;C:\Program Files (x86)\Windows Kits\10\Lib\10.0.10240.0\ucrt\x64
Reference Note: We couldn't run any Theano python files until we added the last two env variables above. We would get a c:\program files (x86)\microsoft visual studio 14.0\vc\include\crtdefs.h(10): fatal error C1083: Cannot open include file: 'corecrt.h': No such file or directory error at compile time and missing kernel32.lib uuid.lib ucrt.lib errors at link time. True, you could probably run C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\amd64\vcvars64.bat (with proper params) every single time you open a MINGW cmd prompt, but, obviously, none of the sysenv vars would stick from one session to the next.
Anaconda (64-bit)
This tutorial was created with Python 2.7, but if you prefer to use Python 3.5 it should work too.
Depending on your installation use c:\toolkits\anaconda3-4.2.0 instead of c:\toolkits\anaconda2-4.2.0.
Download the appropriate Anaconda version from here:
Run the downloaded executable to install Anaconda in c:\toolkits\anaconda2-4.2.0:
Warning: Below, we enabled Register Anaconda as the system Python 2.7 because it works for us, but that may not be the best option for you!
Define sysenv variable PYTHON_HOME with the value c:\toolkits\anaconda2-4.2.0
Add %PYTHON_HOME%, %PYTHON_HOME%\Scripts, and %PYTHON_HOME%\Library\bin to PATH
After anaconda installation open a command prompt and execute:
$ cd $PYTHON_HOME; conda install libpython
Note: The version of MinGW above is old (gcc 4.7.0). Instead, we will use MinGW 5.4.0, as shown below.
Run the downloaded installer. Install the files in c:\toolkits\cuda-8.0.44:
After completion, the installer should have created a system environment (sysenv) variable named CUDA_PATH and added %CUDA_PATH%\bin as well as%CUDA_PATH%\libnvvp to PATH. Check that it is indeed the case. If, for some reason, the CUDA env vars are missing, then:
Define a system environment (sysenv) variable named CUDA_PATH with the value c:\toolkits\cuda-8.0.44
Add%CUDA_PATH%\libnvvp and %CUDA_PATH%\bin to PATH
Install it to c:\toolkits\mingw-w64-5.4.0 with the following settings (second wizard screen):
Define the sysenv variable MINGW_HOME with the value c:\toolkits\mingw-w64-5.4.0
Add %MINGW_HOME%\mingw64\bin to PATH
Run the following to make sure all necessary build tools can be found:
$ where gcc; where g++; where cl; where nvcc; where cudafe; where cudafe++
$ gcc --version; g++ --version
$ cl
$ nvcc --version; cudafe --version; cudafe++ --version
You should get results similar to:
Theano 0.8.2
Version 0.8.2? Why not just install the latest bleeding-edge version of Theano since it obviously must work better, right? Simply put, because it makes reproducible research harder. If your work colleagues or Kaggle teammates install the latest code from the dev branch at a different time than you did, you will most likely be running different code bases on your machines, increasing the odds that even though you're using the same input data (the same random seeds, etc.), you still end up with different results when you shouldn't. For this reason alone, we highly recommend only using point releases, the same one across machines, and always documenting which one you use if you can't just use a setup script.
Clone a stable Theano release (0.8.2) from GitHub into c:\toolkits\theano-0.8.2 using the following commands:
$ cd /c/toolkits
$ git clone https://github.com/Theano/Theano.git theano-0.8.2 --branch rel-0.8.2
Install Theano as follows:
$ cd /c/toolkits/theano-0.8.2
$ python setup.py install --record installed_files.txt
In our case, this resulted in conflicts between 32-bit and 64-bit DLL when trying to run Theano code.
OpenBLAS 0.2.14 (Optional)
If we're going to use the GPU, why install a CPU-optimized linear algebra library? With our setup, most of the deep learning grunt work is performed by the GPU, that is correct, but the CPU isn't idle. An important part of image-based Kaggle competitions is data augmentation. In that context, data augmentation is the process of manufacturing additional input samples (more training images) by transformation of the original training samples, via the use of image processing operators. Basic transformations such as downsampling and (mean-centered) normalization are also needed. If you feel adventurous, you'll want to try additional pre-processing enhancements (noise removal, histogram equalization, etc.). You certainly could use the GPU for that purpose and save the results to file. In practice, however, those operations are often executed in parallel on the CPU while the GPU is busy learning the weights of the deep neural network and the augmented data discarded after use. For this reason, we highly recommend installing the OpenBLAS library.
According to the Theano documentation, the multi-threaded OpenBLAS library performs much better than the un-optimized standard BLAS (Basic Linear Algebra Subprograms) library, so that's what we use.
Download OpenBLAS from here and extract the files to c:\toolkits\openblas-0.2.14-int32
Define sysenv variable OPENBLAS_HOME with the value c:\toolkits\openblas-0.2.14-int32
Theano only cares about the value of the sysenv variable named THEANO_FLAGS. All we need to do to tell Theano to use the CPU or GPU is to set THEANO_FLAGS to either THEANO_FLAGS_CPU or THEANO_FLAGS_GPU. You can verify those variables have been successfully added to your environment with the following command:
Note: If you get a failure of the kind NameError: global name 'CVM' is not defined, it may be because, like us, you've messed with the value of THEANO_FLAGS_CPU and switched back and forth between floatX=float32 and floatX=float64 several times. Cleaning your C:\Users\username\AppData\Local\Theano directory (replace username with your login name) will fix the problem (See here, for reference)
Checking our PATH sysenv var
At this point, the PATH environment variable should look something like:
We'll run the following program from the Theano documentation to compare the performance of the GPU install vs using Theano in CPU-mode. Save the code to a file named cpu_gpu_test.py in the current directory (or download it from this GitHub repo):
from theano import function, config, shared, sandbox
import theano.tensor asTimport numpy
import time
vlen =10*30*768# 10 x #cores x # threads per core
iters =1000
rng = numpy.random.RandomState(22)
x = shared(numpy.asarray(rng.rand(vlen), config.floatX))
f = function([], T.exp(x))
print(f.maker.fgraph.toposort())
t0 = time.time()
for i inrange(iters):
r = f()
t1 = time.time()
print("Looping %d times took %f seconds"% (iters, t1 - t0))
print("Result is %s"% (r,))
if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]):
print('Used the cpu')
else:
print('Used the gpu')
First, let's see what kind of results we get running Theano in CPU mode:
Note: If you get a c:\program files (x86)\microsoft visual studio 14.0\vc\include\crtdefs.h(10): fatal error C1083: Cannot open include file: 'corecrt.h': No such file or directory with the above, please see the Reference Note at the end of the Visual Studio 2015 Community Edition Update 3 section.
Almost a 68:1 improvement. It works! Great, we're done with setting up Theano 0.8.2.
Keras 1.1.0
Clone a stable Keras release (1.1.0) to your local machine from GitHub using the following commands:
$ cd /c/toolkits
$ git clone https://github.com/fchollet/keras.git keras-1.1.0 --branch 1.1.0
This should clone Keras 1.1.0 in c:\toolkits\keras-1.1.0:
Install it as follows:
$ cd /c/toolkits/keras-1.1.0
$ python setup.py install --record installed_files.txt
Verify Keras was installed by querying Anaconda for the list of installed packages:
$ conda list | grep -i keras
Recent builds of Keras can either use Tensorflow or Theano as a backend. At the time of this writing, TensorFlow supports only 64-bit Python 3.5 on Windows. This doesn't work for us, but if you are using Python 3.5, then by all means, feel free to give it a try. By default, we will use Theano as our backend, using the commands below:
We can train a simple convnet (convolutional neural network) on the MNIST dataset by using one of the example scripts provided with Keras. The file is called mnist_cnn.py and can be found in the examples folder:
$ THEANO_FLAGS=$THEANO_FLAGS_GPU
$ cd /c/toolkits/keras-1.1.0/examples
$ python mnist_cnn.py
Without cuDNN, each epoch takes about 20s. If you install TechPowerUp's GPU-Z, you can track how well the GPU is being leveraged. Here, in the case of this convnet (no cuDNN), we max out at 92% GPU usage on average:
cuDNN v5.1 (August 10, 2016) for CUDA 8.0 (Conditional)
If you're not going to train convnets then you might not really benefit from installing cuDNN. Per NVidia's website, "cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers," hallmarks of convolution network architectures. Theano is mentioned in the list of frameworks that support cuDNN v5 for GPU acceleration.
If you are going to train convnets, then download cuDNN from here. Choose the cuDNN Library for Windows10 dated August 10, 2016:
The downloaded ZIP file contains three directories (bin, include, lib). Extract those directories and copy the files they contain to the identically named folders in C:\toolkits\cuda-8.0.44.
To enable cuDNN, create a new sysenv variable named THEANO_FLAGS_GPU_DNN with the following value:
$ THEANO_FLAGS=$THEANO_FLAGS_GPU_DNN
$ cd /c/toolkits/keras-1.1.0/examples
$ python mnist_cnn.py
Note: If you get a cuDNN not available message after this, try cleaning your C:\Users\username\AppData\Local\Theano directory (replace username with your login name). If you get an error similar to cudnn error: Mixed dnn version. The header is from one version, but we link with a different version (5010, 5005), try cuDNN v5.0 instead of cuDNN v5.1. Windows will sometimes also helpfully block foreign .dll files from running on your computer. If that is the case, right click and unblock the files to allow them to be used.
Here's the (cleaned up) execution log for the simple convnet Keras example, using cuDNN:
Now, each epoch takes about 3s, instead of 20s, a large improvement in speed, with slightly lower GPU usage:
The Your cuDNN version is more recent than the one Theano officially supports message certainly sounds ominous but a test accuracy of 0.9899 would suggest that it can be safely ignored. So...
Kaggler Vincent L. for recommending adding dnn.conv.algo_bwd_filter=deterministic,dnn.conv.algo_bwd_data=deterministic to THEANO_FLAGS_GPU_DNN in order to improve reproducibility with no observable impact on performance.
If you'd rather use Python3, conda's built-in MinGW package, or pip, please refer to @stmax82's note here.
Suggested viewing/reading
Intro to Deep Learning with Python, by Alec Radford
Domain Adaptation(DA)에 대한 정리를 올려봅니다. 원래는 제가 하는 딥러닝 스터디에서 발표했던 자료인데 최근에 DA에 대한 관심이 있는 분들이 많아지는 것 같아 올려봅니다. Analysis of Representation for Domain Adaptation 논문에 대한 내용이 대부분이고, Domain Adversarial Training of Neural Networks와 Domain Separation Network의 loss function에 사용되었습니다.
먼저 DA라는 문제 정의는 다음과 같습니다. S라는 source domain에서는 라벨이 있는 데이터를 얻고, T라는 target domain에서는 라벨이 없는 입력 데이터만을 얻게 됩니다. 이 때 우리는 T에서 잘 동작하는 분류기를 찾고 싶은겁니다. 이 세팅은 데이터를 synthetic 환경에서 얻어서 실제 환경에서 동작시키길 원하는 모든 문제에 적용가능한 매우 실용...적인 세팅이라 생각합니다.
DA의 목적은 입력 공간X에서 feature들의 공간 Z로 가는 어떤 좋은 매핑을 찾고자 하는데 있습니다. 우리에게 익숙한 CNN이라면 좋은 convolutional feature map을 찾고자 합니다.
분석을 위해서 조금 더 수학적으로 써보면 입력들의 공간을 measurable space (X, D)로 표현하고, feature들의 measurable space (Z, \tilde{D})로 보내는 어떤 매핑 R을 찾고 싶은거죠.
S와 T의 차이는 다음과 같이 표현됩니다. 우리가 다루는 것이 이미지라 할 때 X는 이미지의 공간이고, domain과 source의 차이는 이 공간 속에서 분류하고자 하는 이미지 사이의 분포의 차이로 정의됩니다. 즉 X에서 정의된 D_{S}와 D_{T}가 있는 것이지요.
이 논문은 크게 두 theorem을 보이는데 첫번째 thm은 target 공간에서의 어떤 분류기 h의 expected error는 source 공간에서의 h의 expected error와 VC bound에서 등장하는 term과 S와 T 공간 사이의 거리와 관심있는 target function 자체의 intrinsic loss에 해당하는 term으로 표현됩니다. 첨부한 정리에선 thm1에 대한 증명을 논문에 써 본 것 보단 조금 더 자세히 정리해봤으니 한번 봐보시면 재밌으실 듯 합니다. VCD나 PAC관련 정리를 보신 분이라면 쉽게 따라가실 수 있을거에요.
Thm1의 물리적 의미를 한번 더 생각해보면 우리가 T에서 잘 동작하는 분류기를 만들기 위해선 먼저 S에서 잘 동작하는 분류기를 만들어야 하고, S와 D 사이의 '거리'를 줄여야 한다는 것이지요. 문젠 이 '거리'를 정의함에 sup이 들어가서 finite sample로 근사가 안된다는 것이지요. 그래서 이를 잘 sample기반으로 잘 근사할 수 있는 다른 metric를 제시합니다. (정확히는 이의 convex upper-bound를요) 그리고 이 근사는 놀랍게도 S공간의 입력들과 T공간의 입력들을 잘 '구분'할 수 없을수록 거리가 가까워지게 됩니다.
뒤에 나오는 Domain Adversarial Trianing of Neural Networks와 Domain Separation Network에선 이 '개념'을 차용해서 새로운 loss functoin을 제안하는데, 입력이 들어왔을 때 이 입력이 S인지 T인지 구분하는 domain classifier를 하나 추가하고, 이 classifier의 성능을 '악화'시키도록 학습을 시킵니다.
개인적으로는 Domain Adversarial Trianing of Neural Networks의 첫번째 실험 파트의 해석이 참 좋은 것 같아요. 각 알고리즘의 decision boundary를 보여주며 DA를 했을 때와 안했을 때의 차이를 보여줍니다.
The dist function is a 'Euclidean distance weight function' which applies weights to an input to get weighted inputs. At your example:
W is the (random) weight matrix. P is the input vector Z is the weighted input
If you type in the matlab prompt 'edit dist.apply' you find the formula behind this function. For your example, the weighted matrix is subtracted from the transposed and copied vector. Now it is squared and then the square root is taken. This is how the Euclidian norm is defined Norm = square((a-b)^2)
I have copied the code and made the example simpler to understand in the code below better:
% dist function
S = size(w,1);
Q = size(p,2);
z2 = zeros(S,Q);
if (Q<S)
p = p';
copies = zeros(1,S);
for q=1:Q
z2(:,q) = sum((w-p(q+copies,:)).^2,2);
end
else
w = w';
copies = zeros(1,Q);
for i=1:S
z2(i,:) = sum((w(:,i+copies)-p).^2,1);
end
end
z2 = sqrt(z2)
In this post, I’ll describe the solution I used. I’ll also explore approaches that did and did not work in my effort to improve my model.
Don’t worry — you don’t need to be an AI expert to understand this post. I’ll focus on the ideas and methods I used as opposed to the technical implementation.
Demo of a deep learning based classifier for recognizing traffic lights
The challenge
The goal of the challenge was to recognize the traffic light state in images taken by drivers using the Nexar app. In any given image, the classifier needed to output whether there was a traffic light in the scene, and whether it was red or green. More specifically, it should only identify traffic lights in the driving direction.
The images above are examples of the three possible classes I needed to predict: no traffic light (left), red traffic light (center) and green traffic light (right).
The challenge required the solution to be based on Convolutional Neural Networks, a very popular method used in image recognition with deep neural networks. The submissions were scored based on the model’s accuracy along with the model’s size (in megabytes). Smaller models got higher scores. In addition, the minimum accuracy required to win was 95%.
Nexar provided 18,659 labeled images as training data. Each image was labeled with one of the three classes mentioned above (no traffic light / red / green).
Software and hardware
I used Caffe to train the models. The main reason I chose Caffe was because of the large variety of pre-trained models.
Python, NumPy & Jupyter Notebook were used for analyzing results, data exploration and ad-hoc scripts.
Amazon’s GPU instances (g2.2xlarge) were used to train the models. My AWS bill ended up being $263 (!). Not cheap. 😑
The code and files I used to train and run the model are on GitHub.
The final classifier
The final classifier achieved an accuracy of 94.955% on Nexar’s test set, with a model size of ~7.84 MB. To compare, GoogLeNet uses a model size of 41 MB, and VGG-16 uses a model size of 528 MB.
Nexar was kind enough to accept 94.955% as 95% to pass the minimum requirement 😁.
The process of getting higher accuracy involved a LOT of trial and error. Some of it had some logic behind it, and some was just “maybe this will work”. I’ll describe some of the things I tried to improve the model that did and didn’t help. The final classifier details are described right after.
I started off with trying to fine-tune a model which was pre-trained on ImageNet with the GoogLeNet architecture. Pretty quickly this got me to >90% accuracy! 😯
Nexar mentioned in the challenge page that it should be possible to reach 93% by fine-tuning GoogLeNet. Not exactly sure what I did wrong there, I might look into it.
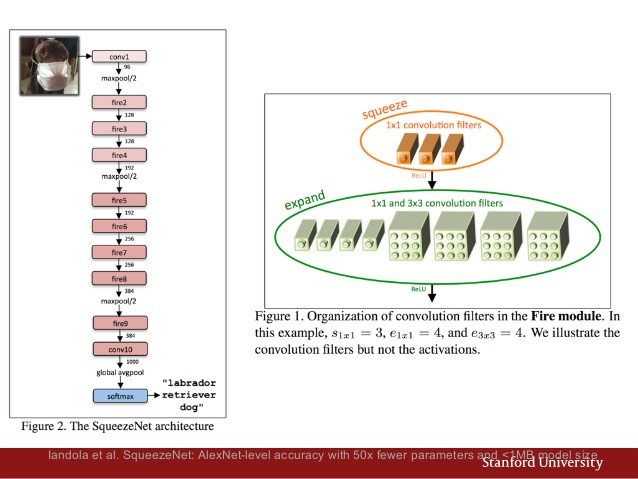
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.
Since the competition rewards solutions that use small models, early on I decided to look for a compact network with as few parameters as possible that can still produce good results. Most of the recently published networks are very deep and have a lot of parameters. SqueezeNet seemed to be a very good fit, and it also had a pre-trained model trained on ImageNet available in Caffe’s Model Zoo which came in handy.
After some back and forth with adjusting the learning rate I was able to fine-tune the pre-trained model as well as training from scratch with good accuracy results: 92%! Very cool! 🙌
Rotating images
Source: Nexar
Most of the images were horizontal like the one above, but about 2.4% were vertical, and with all kinds of directions for “up”. See below.
Different orientations of vertical images. Source: Nexar challenge
Although it’s not a big part of the data-set, we want our model classify them correctly too.
Unfortunately, there was no EXIF data in the jpeg images specifying the orientation. At first I considered doing some heuristic to identify the sky and flip the image accordingly, but that did not seem straightforward.
Instead, I tried to make the model invariant to rotations. My first attempt was to train the network with random rotations of 0°, 90°, 180°, 270°. That didn’t help 🤔. But when averaging the predictions of 4 rotations for each image, there was improvement!
92% → 92.6% 👍
To clarify: by “averaging the predictions” I mean averaging the probabilities the model produced of each class across the 4 image variations.
Oversampling crops
During training the SqueezeNet network first performed random cropping on the input images by default, and I didn’t change it. This type of data augmentation makes the network generalize better.
Similarly, when generating predictions, I took several crops of the input image and averaged the results. I used 5 crops: 4 corners and a center crop. The implementation was free by using existing caffe code for this.
92% → 92.46% 👌
Rotating images together with oversampling crops showed very slight improvement.
Additional training with lower learning rate
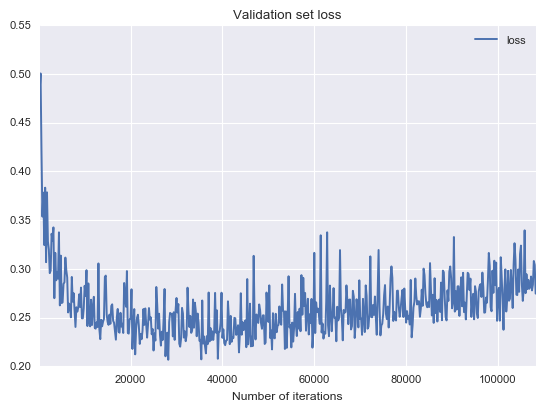
All models were starting to overfit after a certain point. I noticed this by watching the validation-set loss start to rise at some point.
Validation loss rising from around iteration 40,000
I stopped the training at that point because the model was probably not generalizing any more. This meant that the learning rate didn’t have time to decay all the way to zero. I tried resuming the training process at the point where the model started overfitting with a learning rate 10 times lower than the original one. This usually improved the accuracy by 0-0.5%.
More training data
At first, I split my data into 3 sets: training (64%), validation (16%) & test (20%). After a few days, I thought that giving up 36% of the data might be too much. I merged the training & validations sets and used the test-set to check my results.
I retrained a model with “image rotations” and “additional training at lower rate” and saw improvement:
92.6% → 93.5% 🤘
Relabeling mistakes in the training data
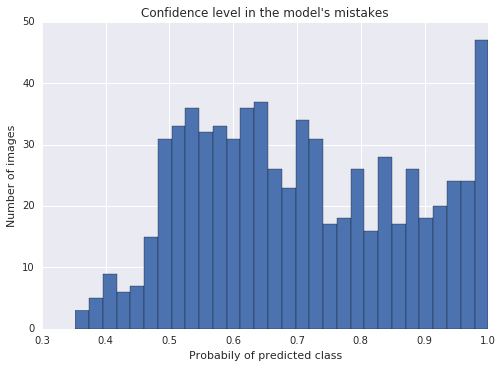
When analyzing the mistakes the classifier had on the validation set, I noticed that some of the mistakes have very high confidence. In other words, the model is certain it’s one thing (e.g. green light) while the training data says another (e.g. red light).
Notice that in the plot above, the right-most bar is pretty high. That means there’s a high number of mistakes with >95% confidence. When examining these cases up close I saw these were usually mistakes in the ground-truth of the training set rather than in the trained model.
I decided to fix these errors in the training set. The reasoning was that these mistakes confuse the model, making it harder for it to generalize. Even if the final testing-set has mistakes in the ground-truth, a more generalized model has a better chance of high accuracy across all the images.
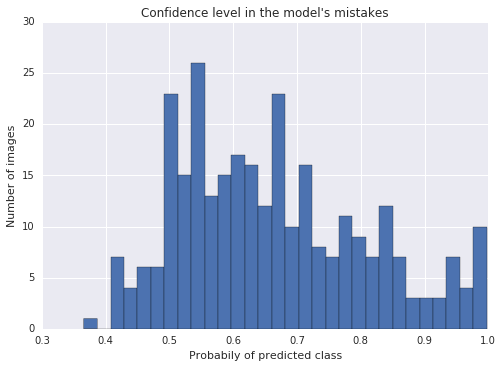
I manually labeled 709 images that one of my models got wrong. This changed the ground-truth for 337 out of the 709 images. It took about an hour of manual work with a python script to help me be efficient.
Above is the same plot after re-labeling and retraining the model. Looks better!
This improved the previous model by:
93.5% → 94.1% ✌️
Ensemble of models
Using several models together and averaging their results improved the accuracy as well. I experimented with different kinds of modifications in the training process of the models involved in the ensemble. A noticeable improvement was achieved by using a model trained from scratch even though it had lower accuracy on its own together with the models that were fine-tuned on pre-trained models. Perhaps this is because this model learned different features than the ones that were fine-tuned on pre-trained models.
The ensemble used 3 models with accuracies of 94.1%, 94.2% and 92.9% and together got an accuracy of 94.8%. 👾
What didn’t work?
Lots of things! 🤕 Hopefully some of these ideas can be useful in other settings.
Combatting overfitting
While trying to deal with overfitting I tried several things, none of which produced significant improvements:
increasing the dropout ratio in the network
more data augmentation (random shifts, zooms, skews)
training on more data: using 90/10 split instead of 80/20
Balancing the dataset
The dataset wasn’t very balanced:
19% of images were labeled with no traffic light
53% red light
28% green light.
I tried balancing the dataset by oversampling the less common classes but didn’t notice any improvement.
Separating day & night
My intuition was that recognizing traffic lights in daylight and nighttime is very different. I thought maybe I could help the model by separating it into two simpler problems.
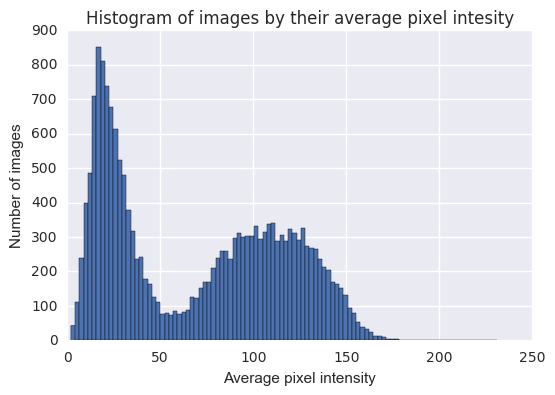
It was fairly easy to separate the images to day and night by looking at their average pixel intensity:
You can see a very natural separation of images with low average values, i.e. dark images, taken at nighttime, and bright images, taken at daytime.
I tried two approaches, both didn’t improve the results:
Training two separate models for day images and night images
Training the network to predict 6 classes instead of 3 by also predicting whether it’s day or night
Using better variants of SqueezeNet
I experimented a little bit with two improved variants of SqueezeNet. The first used residual connections and the second was trained with dense→sparse→dense training (more details in the paper). No luck. 😕
Localization of traffic lights
After reading a great post by deepsense.io on how they won the whale recognition challenge, I tried to train a localizer, i.e. identify the location of the traffic light in the image first, and then identify the traffic light state on a small region of the image.
I used sloth to annotate about 2,000 images which took a few hours. When trying to train a model, it was overfitting very quickly, probably because there was not enough labeled data. Perhaps this could work if I had annotated a lot more images.
Training a classifier on the hard cases
I chose 30% of the “harder” images by selecting images which my classifier was less than 97% confident about. I then tried to train classifier just on these images. No improvement. 😑
Different optimization algorithm
I experimented very shortly with using Caffe’s Adam solver instead of SGD with linearly decreasing learning rate but didn’t see any improvement. 🤔
Adding more models to ensemble
Since the ensemble method proved helpful, I tried to double-down on it. I tried changing different parameters to produce different models and add them to the ensemble: initial seed, dropout rate, different training data (different split), different checkpoint in the training. None of these made any significant improvement. 😞
Final classifier details
The classifier uses an ensemble of 3 separately trained networks. A weighted average of the probabilities they give to each class is used as the output. All three networks were using the SqueezeNet network but each one was trained differently.
Model #1 — Pre-trained network with oversampling
Trained on the re-labeled training set (after fixing the ground-truth mistakes). The model was fine-tuned based on a pre-trained model of SqueezeNet trained on ImageNet.
Data augmentation during training:
Random horizontal mirroring
Randomly cropping patches of size 227 x 227 before feeding into the network
At test time, the predictions of 10 variations of each image were averaged to calculate the final prediction. The 10 variations were made of:
5 crops of size 227 x 227: 1 for each corner and 1 in the center of the image
for each crop, a horizontally mirrored version was also used
Model accuracy on validation set: 94.21% Model size: ~2.6 MB
Model #2 — Adding rotation invariance
Very similar to Model #1, with the addition of image rotations. During training time, images were randomly rotated by 90°, 180°, 270° or not at all. At test-time, each one of the 10 variations described in Model #1 created three more variations by rotating it by 90°, 180° and 270°. A total of 40 variations were classified by our model and averaged together.
Model accuracy on validation set: 94.1% Model size: ~2.6 MB
Model #3 — Trained from scratch
This model was not fine-tuned, but instead trained from scratch. The rationale behind it was that even though it achieves lower accuracy, it learns different features on the training set than the previous two models, which could be useful when used in an ensemble.
Data augmentation during training and testing are the same as Model #1: mirroring and cropping.
Model accuracy on validation set: 92.92% Model size: ~2.6 MB
Combining the models together
Each model output three values, representing the probability that the image belongs to each one of the three classes. We averaged their outputs with the following weights:
Model #1: 0.28
Model #2: 0.49
Model #3: 0.23
The values for the weights were found by doing a grid-search over possible values and testing it on the validation set. They are probably a little overfitted to the validation set, but perhaps not too much since this is a very simple operation.
Model accuracy on validation set: 94.83% Model size: ~7.84 MB Model accuracy on Nexar’s test set: 94.955% 🎉
Examples of the model mistakes
Source: Nexar
The green dot in the palm tree produced by the glare probably made the model predict there’s a green light by mistake.
Source: Nexar
The model predicted red instead of green. Tricky case when there is more than one traffic light in the scene.
The model said there’s no traffic light while there’s a green traffic light ahead.
Conclusion
This was the first time I applied deep learning on a real problem! I was happy to see it worked so well. I learned a LOT during the process and will probably write another post that will hopefully help newcomers waste less time on some of the mistakes and technical challenges I had.
I want to thank Nexar for providing this great challenge and hope they organize more of these in the future! 🙌
If you enjoyed reading this post, please tap ♥ below!
Would love to get your feedback and questions below!
If you get an error about “CVM,” you must delete the cache files that are in C:\Users\MyUsername\AppData\Local\Theano. Once you delete everything, start python again and continue from there.
If you have path issues when trying to import theano, try using the Visual Studio 64-bit command prompt if you have it. It sets a bunch of paths for you and “just works” for me. For reference, the path I use is:
Up and running with Theano (GPU) + PyCUDA on Windows
Jul 30, 2015 7 minute read
Getting CUDA to work with python on Windows is really frustrating. Its not exactly hard, but is sure irritating when you start doing it. If you have ever tried it, you might be knowing that many possible combinations of compilers, cuda toolkit, python etc. don’t work.
This post describes the steps that I followed for a working setup of theano working with GPU acceleration and PyCUDA for general access to GPU from python. Hopefully, it will help if you haven’t found the sweet spot yet.
Setting up
Starting with my machine, it is a Pavilion DV6 7012tx Laptop with Nvidia GeForce GT 630m card. Right now its running Windows 10 x64. If you are already having cygwin or mingw based gcc in place, you might want to remove that since our scientific python stack will provide that.
1. Install Visual Studio
This is needed to get Nvidia’s CUDA compiler (nvcc) working. For choosing the version, go to the latest CUDA on Windows doc and see which version of visual studio the current CUDA toolkit supports.
At the time of writing, CUDA 7 was the latest release and Visual Studio 2013 was the latest supported version. You also don’t need to install 2008 or 2010 version of compiler for python. This will be taken care of later, just go with everything latest.
After installation, you don’t actually need to add cl.exe (usually in a directory like C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin, depending on your Visual Studio version) to PATH for theano since we will define this explicitly in .theanorc, but it is better to do this as many other tools might be using it.
2. Install CUDA toolkit
This should be easy, get the latest CUDA and install it. Keep the samples while installing, they are nice for checking if things are working fine.
3. Setup Python
This is where most of the trouble is. Its easy to get lost while setting up vanilla python for theano specially since you also are setting up gcc and related tools. The theano installation tutorial will bog you down in this phase if you don’t actually read it carefully. Most likely you would end up downloading lots of legacy Visual Studio versions and other stuff. We won’t be going that way.
Install a scientific python distribution like Anaconda. I haven’t tried setting up theano using other distributions but this should be one of the easier ways because of conda package manager. This really relieves you from setting up a separate mingw environment and handling commonly used libraries which are as easy as conda install boost in Anaconda.
If you feel Anaconda is a bit too heavy, try miniconda and adding basic packages like numpy on top of it.
Once you install Anaconda, install additional dependencies.
conda install mingw libpython
4. Install theano
Install theano using pip install theano and create a .theanorc file in your HOME directory with following contents.
One error says that CUDA is installed, but device gpu is not available. For me, this was solved after installing mingw and libpython via conda since Anaconda doesn’t setup gcc along with it as it used to do earlier.
For a more extensive test, try the following snippet taken from theano docs.
fromtheanoimportfunction,config,shared,sandboximporttheano.tensorasTimportnumpyimporttimevlen=10*30*768# 10 x #cores x # threads per coreiters=1000rng=numpy.random.RandomState(22)x=shared(numpy.asarray(rng.rand(vlen),config.floatX))f=function([],T.exp(x))printf.maker.fgraph.toposort()t0=time.time()foriinxrange(iters):r=f()t1=time.time()print'Looping %d times took'%iters,t1-t0,'seconds'print'Result is',rifnumpy.any([isinstance(x.op,T.Elemwise)forxinf.maker.fgraph.toposort()]):print'Used the cpu'else:print'Used the gpu'
 GitHub - philferriere_dlwin_ GPU-accelerated Deep Learning on Windows 10 native.pdf
GitHub - philferriere_dlwin_ GPU-accelerated Deep Learning on Windows 10 native.pdf



































 dist_func.m
dist_func.m