http://kr.mathworks.com/matlabcentral/answers/79147-how-to-color-correct-an-image-from-with-a-color-checker
 http_kr.mathworks.com_matlabcentral_answers_79147-how-to-colo.pdf
http_kr.mathworks.com_matlabcentral_answers_79147-how-to-colo.pdf
We are developing an open source image analysis pipeline ( http://bit.ly/VyRFEr) for processing timelapse images of plants growing. Our lighting conditions vary dynamically throughout the day ( http://youtu.be/wMt5xtp9sH8) but we want to be able to automate removal of the background and then count things like green pixels between images of the same plant throughout the day despite the changing lighting. All the images have x-rite (equivalent) color checkers in them. I've looked through a lot of posts but I'm still a unclear on how we go about doing color (and brightness) correction to normalize the images so they are comparable. Am I wrong in assuming this is a relatively simple undertaking?
Anyone have any working code, code samples or suggested reading to help me out?
Thanks!
Tim
Sample images: Morning: http://phenocam.anu.edu.au/data/timestreams/Borevitz/_misc/sampleimages/morning.JPG
Noon: http://phenocam.anu.edu.au/data/timestreams/Borevitz/_misc/sampleimages/noon.JPG
-------------------------------------------------------------------------------------------
Tim: I do this all the time, both in RGB color space, when we need color correction to a standard RGB image, and in XYZ color space, when we want calibrated color measurements. In theory it's simple, but the code and formulas are way too lengthy to share here. Basically for RGB-to-RGB correction, you make a model of your transform, say linear, quadratic, or cubic, with or without cross terms (RG, RB, R*B^2, etc.). Then you do a least squares model to get a model for Restimated, Gestimated, and Bestimated. Let's look at just the Red. You plug in the standard values for your 24 red chips (that's the "y"), and the values of R, G, B, RG, RB, GB, R^2G, etc. into the "tall" 24 by N matrix, and you do least squares to get the coefficients, alpha. Then repeat to get sets of coefficients beta, and gamma, for the estimated green and blue. Now, for any arbitrary RGB, you plug them into the three equations to get the estimated RGB as if that color was snapped at the same time and color temperature as your standard. If all you have are changes in intensity you probably don't need any cross terms, but if you have changes in the color of the illumination, then including cross terms will correct for that, though sometimes people do white balancing as a separate step before color correction. Here is some code I did to do really crude white balancing (actually too crude and simple for me to ever actually use but simple enough that people can understand it).
I don't have any demo code to share with you - it's all too intricately wired into my projects. Someone on the imaging team at the Mathworks (I think it was Grant if I remember correctly) has a demo to do this. I think it was for the Computer Vision System Toolbox, but might have been for the Image Processing Toolbox. Call them and try to track it down. In the mean time try this: http://www.mathworks.com/matlabcentral/answers/?search_submit=answers&query=color+checker&term=color+checker
--------------------------------------------------------------------------------------------
Thanks, this is very helpful. Is there a quick and easy way to adjust white balance at least? Likewise for the color correction... if I don't need super good color correction but just want to clean up the lighting a bit without doing any high end color corrections is there a simple way to do this or do am I stuck figuring out how to do the full color correction or nothing?
Thanks again.
Tim
---------------------------------------------------------------------------------------------
Did you ever get the demo from the Mathworks? If so, and they have it on their website, please post the URL.
Here's a crude white balancing demo:
% Does a crude white balancing by linearly scaling each color channel.
clc; % Clear the command window.
close all; % Close all figures (except those of imtool.)
clear; % Erase all existing variables.
workspace; % Make sure the workspace panel is showing.
format longg;
format compact;
fontSize = 15;
% Read in a standard MATLAB gray scale demo image.
folder = fullfile(matlabroot, '\toolbox\images\imdemos');
button = menu('Use which demo image?', 'onion', 'Kids');
% Assign the proper filename.
if button == 1
baseFileName = 'onion.png';
elseif button == 2
baseFileName = 'kids.tif';
end
% Read in a standard MATLAB color demo image.
folder = fullfile(matlabroot, '\toolbox\images\imdemos');
% Get the full filename, with path prepended.
fullFileName = fullfile(folder, baseFileName);
if ~exist(fullFileName, 'file')
% Didn't find it there. Check the search path for it.
fullFileName = baseFileName; % No path this time.
if ~exist(fullFileName, 'file')
% Still didn't find it. Alert user.
errorMessage = sprintf('Error: %s does not exist.', fullFileName);
uiwait(warndlg(errorMessage));
return;
end
end
[rgbImage colorMap] = imread(fullFileName);
% Get the dimensions of the image. numberOfColorBands should be = 3.
[rows columns numberOfColorBands] = size(rgbImage);
% If it's an indexed image (such as Kids), turn it into an rgbImage;
if numberOfColorBands == 1
rgbImage = ind2rgb(rgbImage, colorMap); % Will be in the 0-1 range.
rgbImage = uint8(255*rgbImage); % Convert to the 0-255 range.
end
% Display the original color image full screen
imshow(rgbImage);
title('Double-click inside box to finish box', 'FontSize', fontSize);
% Enlarge figure to full screen.
set(gcf, 'units','normalized','outerposition', [0 0 1 1]);
% Have user specify the area they want to define as neutral colored (white or gray).
promptMessage = sprintf('Drag out a box over the ROI you want to be neutral colored.\nDouble-click inside of it to finish it.');
titleBarCaption = 'Continue?';
button = questdlg(promptMessage, titleBarCaption, 'Draw', 'Cancel', 'Draw');
if strcmpi(button, 'Cancel')
return;
end
hBox = imrect;
roiPosition = wait(hBox); % Wait for user to double-click
roiPosition % Display in command window.
% Get box coordinates so we can crop a portion out of the full sized image.
xCoords = [roiPosition(1), roiPosition(1)+roiPosition(3), roiPosition(1)+roiPosition(3), roiPosition(1), roiPosition(1)];
yCoords = [roiPosition(2), roiPosition(2), roiPosition(2)+roiPosition(4), roiPosition(2)+roiPosition(4), roiPosition(2)];
croppingRectangle = roiPosition;
% Display (shrink) the original color image in the upper left.
subplot(2, 4, 1);
imshow(rgbImage);
title('Original Color Image', 'FontSize', fontSize);
% Crop out the ROI.
whitePortion = imcrop(rgbImage, croppingRectangle);
subplot(2, 4, 5);
imshow(whitePortion);
caption = sprintf('ROI.\nWe will Define this to be "White"');
title(caption, 'FontSize', fontSize);
% Extract the individual red, green, and blue color channels.
redChannel = whitePortion(:, :, 1);
greenChannel = whitePortion(:, :, 2);
blueChannel = whitePortion(:, :, 3);
% Display the color channels.
subplot(2, 4, 2);
imshow(redChannel);
title('Red Channel ROI', 'FontSize', fontSize);
subplot(2, 4, 3);
imshow(greenChannel);
title('Green Channel ROI', 'FontSize', fontSize);
subplot(2, 4, 4);
imshow(blueChannel);
title('Blue Channel ROI', 'FontSize', fontSize);
% Get the means of each color channel
meanR = mean2(redChannel);
meanG = mean2(greenChannel);
meanB = mean2(blueChannel);
% Let's compute and display the histograms.
[pixelCount grayLevels] = imhist(redChannel);
subplot(2, 4, 6);
bar(pixelCount);
grid on;
caption = sprintf('Histogram of original Red ROI.\nMean Red = %.1f', meanR);
title(caption, 'FontSize', fontSize);
xlim([0 grayLevels(end)]); % Scale x axis manually.
% Let's compute and display the histograms.
[pixelCount grayLevels] = imhist(greenChannel);
subplot(2, 4, 7);
bar(pixelCount);
grid on;
caption = sprintf('Histogram of original Green ROI.\nMean Green = %.1f', meanR);
title(caption, 'FontSize', fontSize);
xlim([0 grayLevels(end)]); % Scale x axis manually.
% Let's compute and display the histograms.
[pixelCount grayLevels] = imhist(blueChannel);
subplot(2, 4, 8);
bar(pixelCount);
grid on;
caption = sprintf('Histogram of original Blue ROI.\nMean Blue = %.1f', meanR);
title(caption, 'FontSize', fontSize);
xlim([0 grayLevels(end)]); % Scale x axis manually.
% specify the desired mean.
desiredMean = mean([meanR, meanG, meanB])
message = sprintf('Red mean = %.1f\nGreen mean = %.1f\nBlue mean = %.1f\nWe will make all of these means %.1f',...
meanR, meanG, meanB, desiredMean);
uiwait(helpdlg(message));
% Linearly scale the image in the cropped ROI.
correctionFactorR = desiredMean / meanR;
correctionFactorG = desiredMean / meanG;
correctionFactorB = desiredMean / meanB;
redChannel = uint8(single(redChannel) * correctionFactorR);
greenChannel = uint8(single(greenChannel) * correctionFactorG);
blueChannel = uint8(single(blueChannel) * correctionFactorB);
% Recombine into an RGB image
% Recombine separate color channels into a single, true color RGB image.
correctedRgbImage = cat(3, redChannel, greenChannel, blueChannel);
figure;
% Display the original color image.
subplot(2, 4, 5);
imshow(correctedRgbImage);
title('Color-Corrected ROI', 'FontSize', fontSize);
% Enlarge figure to full screen.
set(gcf, 'units','normalized','outerposition',[0 0 1 1]);
% Display the color channels.
subplot(2, 4, 2);
imshow(redChannel);
title('Corrected Red Channel ROI', 'FontSize', fontSize);
subplot(2, 4, 3);
imshow(greenChannel);
title('Corrected Green Channel ROI', 'FontSize', fontSize);
subplot(2, 4, 4);
imshow(blueChannel);
title('Corrected Blue Channel ROI', 'FontSize', fontSize);
% Let's compute and display the histograms of the corrected image.
[pixelCount grayLevels] = imhist(redChannel);
subplot(2, 4, 6);
bar(pixelCount);
grid on;
caption = sprintf('Histogram of Corrected Red ROI.\nMean Red = %.1f', meanR);
title(caption, 'FontSize', fontSize);
xlim([0 grayLevels(end)]); % Scale x axis manually.
% Let's compute and display the histograms.
[pixelCount grayLevels] = imhist(greenChannel);
subplot(2, 4, 7);
bar(pixelCount);
grid on;
caption = sprintf('Histogram of Corrected Green ROI.\nMean Green = %.1f', meanR);
title(caption, 'FontSize', fontSize);
xlim([0 grayLevels(end)]); % Scale x axis manually.
% Let's compute and display the histograms.
[pixelCount grayLevels] = imhist(blueChannel);
subplot(2, 4, 8);
bar(pixelCount);
grid on;
caption = sprintf('Histogram of Corrected Blue ROI.\nMean Blue = %.1f', meanR);
title(caption, 'FontSize', fontSize);
xlim([0 grayLevels(end)]); % Scale x axis manually.
% Get the means of the corrected ROI for each color channel.
meanR = mean2(redChannel);
meanG = mean2(greenChannel);
meanB = mean2(blueChannel);
correctedMean = mean([meanR, meanG, meanB])
message = sprintf('Now, the\nCorrected Red mean = %.1f\nCorrected Green mean = %.1f\nCorrected Blue mean = %.1f\n(Differences are due to clipping.)\nWe now apply it to the whole image',...
meanR, meanG, meanB);
uiwait(helpdlg(message));
% Now correct the original image.
% Extract the individual red, green, and blue color channels.
redChannel = rgbImage(:, :, 1);
greenChannel = rgbImage(:, :, 2);
blueChannel = rgbImage(:, :, 3);
% Linearly scale the full-sized color channel images
redChannelC = uint8(single(redChannel) * correctionFactorR);
greenChannelC = uint8(single(greenChannel) * correctionFactorG);
blueChannelC = uint8(single(blueChannel) * correctionFactorB);
% Recombine separate color channels into a single, true color RGB image.
correctedRGBImage = cat(3, redChannelC, greenChannelC, blueChannelC);
subplot(2, 4, 1);
imshow(correctedRGBImage);
title('Corrected Full-size Image', 'FontSize', fontSize);
message = sprintf('Done with the demo.\nPlease flicker between the two figures');
uiwait(helpdlg(message));
![weidi15.pdf [2.1Mo]](http://www.robots.ox.ac.uk/~vgg/publications/images/pdf.png)
 code.zip
code.zip![[Ulas Bagci in 2015]](http://www.cs.ucf.edu/~bagci/images/bagci_picture_old.jpg "Ulas Bagci in 2015")



















 generate_features1.cpp
generate_features1.cpp on an observed variable
on an observed variable  . Within a probabilistic framework, this is done by modeling the
. Within a probabilistic framework, this is done by modeling the 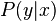 , which can be used for predicting
, which can be used for predicting 







 Visual Recognition and Search.htm
Visual Recognition and Search.htm

















{kind=link}
{kind=link}