참고로 아나콘다에서 텐서플로 1.X 또는 2.X 설치하고 가상환경 실행 환경법 부터 "Hello, World" 부터 기본 선형 회귀 분석과 로지스틱 분석, K-Means 및 Nearest Neighbor, Random Forest, GBDT 알고리즘과 Word2Vec 모델을 작성해 볼 수 있습니다.
From SIGGRAPH 2020: Method reconstructs the geometry of complex 3D thin structures in high quality from a color video captured by a handheld camera
For project and code/API/expert request: [https://www.catalyzex.com/paper/arxiv:2005.03372](https://www.catalyzex.com/paper/arxiv:2005.03372)
Method achieves accurate camera pose estimation and faithful reconstruction of 3D thin structures with complex shape and topology at a level that has not been attained by other existing reconstruction methods.
Reconstruct 3D human body shapes based on a sparse set of RGBD frames using a single RGBD camera
For project or code/API/expert requests: https://www.catalyzex.com/paper/arxiv:2006.03630
Empirical evaluations on synthetic and real datasets demonstrate both quantitatively and qualitatively the superior performance of our framework in reconstructing complete 3D human models with high fidelity.
Recapture your portrait photos with desired posture/view, figure, and clothing style!
For project and API or code request: https://www.catalyzex.com/paper/arxiv:2006.01435
It can properly infer invisible body parts and clothes in original portraits, e.g. the lower body, and meanwhile guarantee global coherency of different regions in recaptured portraits.
DeepFaceDrawing: Deep Generation of Face Images from Sketches Paper: http://geometrylearning.com/paper/DeepFaceDrawing.pdf Video: https://www.youtube.com/watch?v=HSunooUTwKs
היי חברים, אני מעביר הרצאות בנושא של מידול תלת מימדי מתמונה בעזרת רשתות ניורנים. בשבועות האחרונים התחלתי להעביר את זה בזום והייתה היענות גבוה (בעיקר מהקהילה החדשה שנוצרה לנו ברדיט https://www.reddit.com/r/2D3DAI/ ), לכן החלטתי לפתוח עוד 4 הרצאות השבוע, המעוניינים מוזמנים להצטרף:
(technical) - June 5th 09:30 https://www.reddit.com/r/2D3DAI/comments/gu06j6/from_2d_to_3d_using_artificial_intelligence_east/
(technical) - June 5th 20:30 https://www.reddit.com/r/2D3DAI/comments/gu097x/from_2d_to_3d_using_artificial_intelligence_west/
(semi-technical) - June 4th 09:30 https://www.reddit.com/r/2D3DAI/comments/gu072a/from_2d_to_3d_using_artificial_intelligence_east/
(semi-technical) - June 4th 20:30 https://www.reddit.com/r/2D3DAI/comments/gu07uq/from_2d_to_3d_using_artificial_intelligence_west/
הרצאות technical דורשות היכרות בסיסית עם רשתות ניורנוים CNN, ResNet. הsemi-technical זה תוכן דומה עם הקדמה על מה זה CNN וResNet וקצת פחות צלילה לפרטים. כל ההרצאות יהיו באנגלית.
Hi, I was told that pytorch is for research purpose and tensorflow for development. Need some clarrification because I have seen people using pytorch too in development. Can't we do all tasks in pytorch which can be done in tensorflow? Give your views
When it comes to deployment in embedded devices, you need to convert pytorch model to tensorflow using third party software. So, you can do all tasks in pytorch but tensorflow is needed when it comes to deployment in devices like android, raspberry pie, etc
This used to be more true than it is now.
Tensorflow didn't have "eager mode" which made it hard to interactively debug research (it does have an eager mode now).
Pytorch didn't have static graphs or a c++ or mobile api which made it harder to deploy in production in some cases (it does now have static "jit" graphs and c++ and mobile APIs).
There are still some differences, eg some researchers prefer the numpy-like api of pytorch. I think Tensorflow has a Javascript api.
The differences are much smaller today and a lot of it comes down to personal preference.
Latest from Apple researchers: Deep learning approach for driving animated faces using both acoustic and visual information
For project and code or API requests: https://www.catalyzex.com/paper/arxiv:2005.13616
To ensure that the model exploits both modalities during training, batches are generated that contain audio-only, video-only, and audiovisual input features
Extracting editable 3D objects directly from a single photograph. For project and code or API request: [https://www.catalyzex.com/paper/arxiv:2005.13312](https://www.catalyzex.com/paper/arxiv:2005.13312)
They simultaneously identify profile-body relations and recover 3D parts by sweeping the recognized profile along their body contour and jointly optimize the geometry to align with the recovered masks. Qualitative and quantitative experiments show that our algorithm can recover high quality 3D models and outperforms existing methods in both instance segmentation and 3D reconstruction
[오픈소스+젯슨보드] AIoT: 생각에 대한 인공 지능 #PyTorch #JetsonNano #Autoencoder #kmeans #ml #뇌파탐지예측 #EEG #GitHub #기계학습 #IoT 뇌파를 읽고 신호 처리하는 방법, Autoencoder를 구축 및 훈련하여 EEG 데이터를 잠재적 인 표현으로 압축하는 방법, 뇌 상태를 결정하기 위해 데이터를 분류하는 k-means 기계 학습 알고리즘 및 물리적 하드웨어를 제어하기 위한 정보! 그리고 그 과정에서 파이썬으로 GUI와 실시간 그래픽을 만드는 방법에 대한 팁을 얻으십시오. 공헌자: David Ng GitHub: https://github.com/dnhkng/AIoT Hackster.io: https://www.hackster.io/dnhkng/aiot-artificial-intelligence-on-thoughts-f62249
From Adobe researchers: State of the art in High-Resolution Image Inpainting For project and code or API request: https://www.catalyzex.com/paper/arxiv:2005.11742
To mimic real object removal scenarios, they collect a large object mask dataset and synthesize more realistic training data that better simulates user inputs
Ask Me Anything session with a Kaggle Grandmaster Vladimir I. Iglovikov https://towardsdatascience.com/ask-me-anything-session-with-a-kaggle-grandmaster-vladimir-i-iglovikov-942ad6a06acd
First-time Competitor to Kaggle Grandmaster Within a Year | A Winner’s Interview with Limerobot https://medium.com/kaggle-blog/zero-to-grandmaster-in-a-year-a-winners-interview-with-limerobot-18ddb3a1aae1
Semantic Segmentation from Image Labels For project and code or API request: https://www.catalyzex.com/paper/arxiv:2005.08104
They develop a segmentation-based network model and a self-supervised training scheme to train for semantic masks from image-level annotations in a single-stage
전 세계 100만 명 참여한 ‘캐글’ 대회… 국내 단 3명뿐인 그랜드마스터를 달성하다, AI팀 김상훈(이베이코리아 AI팀 김상훈 매니저 / 이베이 블로그)
이베이코리아에서는 물류 센터의 효율적인 운영과 자동화, 소비 행동 패턴 기반의 소비자 성향 추정, 판매 제품과 광고 상품의 연관성 증대 및 이상 거래 탐지 등 다양한 분야에서 폭넓게 인공지능(AI)을 활용하고 있다.
최근 이베이코리아 AI팀 김상훈 매니저가 구글이 소유하고 있는 세계 최대 온라인 AI 경진 플랫폼, ‘캐글(Kaggle)’에서 1년이라는 짧은 기간 안에 최상위 연구자(그랜드마스터)로 선정됐다.
김상훈 매니저를 만나 대회 준비 과정과 최근 AI 트렌드에 관한 다양한 이야기들을 들어 보자!
* 10년 전부터 머신러닝에 관심…다양한 연구, 개발에 참여
안녕하세요. 저는 이베이코리아 AI Lab실의 AI Platform팀에서 근무하는 김상훈입니다. 저는 전자공학부를 전공하고, 10년 전 대학원 시절부터 중점적으로 머신러닝(Machine Learning)을 접하여 연구하기 시작했습니다. 컴퓨터 비전(Computer Vision) 분야의 얼굴인식(Face Recognition)이 연구 주제였지만, 회사 생활을 하면서 자연어 처리(Natural Language Processing) 같은 다른 분야에도 관심을 가지게 되었어요. 이베이코리아 직전 회사에서는 딥러닝(Deep Learning) 기술로 (구글 번역기 같은) 기계 번역기를 만드는 일이나 어울리는 옷을 찾아주는 패션 아이템 추천 기술 등을 개발해 온 데이터과학자(Data Scientist)이기도 합니다.
* 후배 개발자들…개발 역량뿐 아니라 비즈니스에 대한 이해 키우길!
데이터 과학자는 고유 업무인 데이터 모델링, POC(Proof of Concept, 개념 증명)를 위한 클라이언트 개발 능력이 물론 중요하지만, 비즈니스에 대한 전반적인 이해도를 높이기 위해 노력하는 자세가 중요하다고 봐요. 회사 차원에서 프로젝트를 진행하려면 다른 부서와의 협업 능력, 설득력 있는 커뮤니케이션 역량 등이 많이 요구되는 것 같습니다.
We've just open-sourced our implementation of TransformerTTS 🤖💬: a Text-to-Speech Transformer. It's based on a Microsoft paper: Neural Speech Synthesis with Transformer Network. It's written in TensorFlow 2 and uses all its cool features.
The best thing on our implementation though is that you can easily use the WaveRNN Vocoder to generate human-level synthesis. We also provide samples and a Colab notebook. Make sure to check it out and please star ⭐️ the repo and share it! We're already working on the Forward version of TransformerTTS and we'll release it soon as well.
Adversarial Colorization of Icons Based on Structure and Color Conditions
Authors: Tsai-Ho Sun, Chien-Hsun Lai, Sai-Keung Wong, and Yu-Shuen Wang
Abstract: We present a system to help#designerscreate icons that are widely used in banners, signboards, billboards, homepages, and#mobileapps. Designers are tasked with drawing contours, whereas our system colorizes contours in different styles. This goal is achieved by training a dual conditional generative adversarial network (GAN) on our collected icon dataset.
Artificial Intelligence it’s a journey, not a destination.
This means only one thing; you need to be prepared for constant learning. Is it a tough path? With all the abundance of abstract terms and an almost infinite number of details, the AI and ML learning curve can indeed be steep for many. But, getting started with anything new is hard, isn’t it? Moreover, I believe everyone can learn it if only there is a strong desire. Besides, there is an effective approach that will facilitate your learning. Like for example, you don’t need to rush, just start with small moves. Imagine a picture of everything you have learned. Every day you should add new elements to this picture, make it bigger and more detailed. Today you can make your picture even bigger by dint of lots of tools out there that allow anyone to get started learning Machine Learning. No excuses! And you have not to be an AI wizard or mathematician. You just need to learn how to teach machines that work in ones and zeros to reach their conclusions about the world. You’re teaching them how to think! Wanna learn how to do so? Here are the best books, courses and more that will help you do it more effectively without being confused.
Bes AI & ML Online Courses


If you want to know more about Artificial Intelligence and Machine learning, online course is a great opportunity to study theoretical aspects and solve practical problems. If you have a sufficient amount of time for this, use this chance. Here are a few courses that I will undoubtedly recommend:
This intensive course provides an in-depth introduction to AI and Machine Learning, it helps understand statistical modeling and discusses best practices for applying Machine Learning. Here you can learn everything about training and assessing models performing common tasks such as classification, regression, and clustering. All this is just in fifteen videos and 81 exercises with an estimated timeline of six hours. By the end of this course, you’ll have a basic understanding of all the main principles. Consequently, it will equip you to transition into a role as a machine learning engineer.
Totally legendary and the most basic machine learning course from Andrew Ng, one of Coursera’s co-founders. Highly recommend this one. Why so? It provides an in-depth introduction and helps you understand statistical modeling and discusses best practices for applying. This is a really good course, after which many things in machine learning become clear. In total, the course lasts 11 weeks. Each week involves 1–2 hours of video lectures, a test of knowledge of the theory and a practical task on the application of specific machine learning methods. In total, it took me 4–6 hours to complete all the material and complete all the tasks of one week. It is important to complete practical tasks, you need to be able to program at least at the most basic level. Personally, I recommend that you complete all the tasks yourself. Nevertheless, if you do not strive to get a follow-up of course, you can not do them. As a last resort, GitHub is full of repositories with various ready-made solutions to practical problems. In my opinion, the course has exactly one disadvantage — the code will need to be written in MATLAB. If this does not bother you, then don’t hesitate to take it.
Another one creation from Andrew Ng. I especially liked the third course, where Andrew talks about how to conduct research in the field of deep learning. But his advice can come in handy in classic ML. What background knowledge is necessary? Basic programming skills (understanding of for loops, if/else statements, data structures such as lists and dictionaries) and that’s all.
If you’re looking for a short yet concise online course that gives a great summarization to your already existing ML knowledge, this is the best choice for you. This course on Machine Learning with Python will equip you to understand the concepts of using data to predict future events. Here you will learn to build predictive models and use Python to perform Supervised learning with scikit-learn, the most powerful ML library used by every Machine Learning Engineer and Data Scientist.
Last but not the least, this course will help you master ML on Python and R, make accurate predictions, build a great intuition of many machine learning models, handle specific tools like reinforcement learning, NLP and Deep Learning. In other words, here is everything you need to master! * And one more suggestion concerning statistics. Where would we be without statistics? In order to set up experiments and correctly calculate correlations, you need to know the statistics. There is an excellent course that I recommend. And if you are completely lazy, then use the book Head First Statistics. Small, with visual pictures — you can read it in just a couple of hours.
AI and Machine Learning Books
Well, then…if you want to dig a little deeper and figure out what’s what, there is no other way than reading good books! This approach can not boast of relevance, but this can be a source of information for a limited period of time and give you a fundamental understanding of technology and how it can be implemented for your tasks.
Nice book for everyone! The author reveals the methods of constructing models and machine learning algorithms. Here are carefully selected examples, accompanied by illustrations, which are gradually becoming more complicated. At the end of each part are links to additional literature with comments by the author.
This one is simpler and easier to read and also it has lots of practical examples. In general, this book will not make you a specialist in machine learning, but will introduce you to the basics in “human language” and show examples of use. Very suitable for the first acquaintance with the topic, especially when you have a background in programming.
Must-read! This book is one of the most advanced in deep learning and machine learning. It also covers the mathematical and conceptual background, deep learning techniques used in industry, and research perspectives.
The book is a bestseller in the Artificial Intelligence section. A huge benefit of this book is the underestimated requirements for the reader’s knowledge. The book is a step-by-step journey through the mathematics of neural networks to create your own neural network using Python. After reading, you can do the main thing: write code in Python, create your own neural networks, teaching them how to recognize various images, and even create solutions based on the Raspberry Pi. But this is not all, because there is also mathematics in the book, but it will not make you scream from horror and misunderstanding ;)
It’s hard for me to call this book a must-read, cause most experts usually get acquainted with this content in practice. However, this book can save you time on the invention of some bicycles and introduce you to the classical methods of speech recognition, language processing, and information retrieval. Whether this is necessary for the era of dominance of neural networks is up to you.
Through a minimal theory, application of concrete examples, and two pre-built Python production infrastructures — scikit-learn and TensorFlow — the author will help you to achieve an intuitive understanding of tools and concepts for building intelligent systems. Thanks to this book, you will learn a wide range of techniques, from simple linear regression and progression to deep neural networks. Totally recommend this book!
The book is intended for graduate students and is intended for those who have basic knowledge in the field of machine learning. I liked the emphasis on missing values of some of the chapters. Would recommend the middle part of the book as a good, but slightly unorthodox introduction to machine learning.
And the last book on this list that I can’t ignore. It is a fascinating series of essays that ponder the effect that the development of artificial intelligence might have in all the circles of our life. I am still reading it and it is an intellectual feast.
Additional Information and Useful Links
Wanna learn more? Have no time for reading books, or taking a course? Read articles or find needed stuff on GitHub. Here are some must-visited places for this:
Open Source Society University’s Data Science course — this is a solid path for those of you who want to complete a Data Science course on your own time, for free, with courses from the best universities in the World
51 ideas for training tasks (toy data problem) in Data Science
You don’t have to be great to start, but you have to start to be great ― Zig Ziglar.
That’s how I wanna end this post. And the last thing, learn AI an ML, cause this is a super exciting time to be involved in this field. And you probably won’t regret it if you start this journey to new knowledge and spend your time on this. If believing the predictions of futurists, these technologies are our future! As always, if you do anything cool with this information, leave a response in the comments below or reach out at any time on my Instagram and Medium blog. Thanks for reading!
Separate a target speaker's speech from a mixture of two speakers
For project and code or API request: https://www.catalyzex.com/paper/arxiv:2005.07074
(FaceFilter: Audio-visual speech separation using still images)
Done using a deep audio-visual speech separation network. Unlike previous works that used lip movement on video clips or pre-enrolled speaker information as an auxiliary conditional feature, we use a single face image of the target speaker
State of the art in lane detection! For project and code or API request: [https://www.catalyzex.com/paper/arxiv:2004.10924](https://www.catalyzex.com/paper/arxiv:2004.10924)
Novel method for lane detection that uses as input an image from a forward-looking camera mounted in the vehicle and outputs polynomials representing each lane marking in the image, via deep polynomial regression
Some time ago, there was a discussion on a listserv to which I describe regarding statistical software preference. Someone had mentioned a strong preference for the use of R and since that time, I have downloaded the software package (seeing as how it's freeware). However, in looking at the interface, I am at a loss regarding how to actually use the application, and I currently cannot commit the time necessary to pour through the hundreds of help articles or forums. That being said, I looked into some R tutorial books and I wanted to see if anyone has any experience with the books I have listed below or if there are any other recommendations (the ones listed are based on reviews). I am currently gravitating towards Andy Field's book because his writing style is accessible and entertaining, but I also feel that there may be some "wasted chapters" because I already have the SPSS version of his book and I assume that there will be some redundancy. I am also open to the idea that I might need to buy 2 books.
I will likely be conducting traditional statistical analyses (e.g., factor analysis, discriminant function analysis, MANOVA/MANCOVA, ANOVA/ANCOVA, regression), but I would also like to learn how to conduct other analyses through R (e.g., canonical correlation analysis, structural equation modeling, path analysis, time series analysis, etc). I have not used some of these techniques, so a book that includes didactics regarding the nature of these analyses would also be ideal. I appreciate any insight into this. Thank you for your time and I hope everyone has a nice day.
Discovering Statistics using R (Andy Field, Jeremy Miles, & Zoe Field)
The R Book (Michael J. Crawley)
R Cookbook (Paul Teetor)
R for Dummies (Joris Meys and Andrie de Vries) (they have one of these books for everything, don't they?)
Introductory statistics with R (Peter Dalagard)
R by Example (Use R!) (Jim Albert and Maria Rizzo)
I bought the R Book by M.Crawley and find that it was really helpful. It helps you learning how to use the software but also gives some hints in how to run the stats. I am using it over and over every time I am trying to learn some new analyses! I warmly advice it. I also have the R Graphics book but this doesn't really add much to what you would already find in the R Book, unless you want to do advanced quality graphs.
Thomas, just finished up a stint learning R as I had previous knowledge/experience with SPSS and SAS. Found that once the code and structure of R made since, the language is very good. I used as part of the learning process The Art of R Programming, A Tour of Statistical Software Design by Matloff [ISBN-13: 978-1593273842].
This was a strong intro book to get into R.
What I found was really helpful for seeing how to construct some of the more complex models was using a couple tools, Deducer and R Commander. These are GUI packages that extend R and let you do some pretty good modeling with simple point and click but you can see the code generated which helped me learn good practice for using various functions.
A final thought, while your time may be limited, the forums and help articles do provide an additional component in that that discuss various package extensions for R. The true power of R lies in the fact that anyone can write add on packages to extend functionality and there are some great ones out there.
Thank you everyone for your recommendations and feedback! I will definitely set some time aside in the next couple of weeks to start learning how to use this application. Take care and I hope everyone enjoys the rest of their week.
Dear Thomas, I can only agree with Ivan Maggini: Crawley's The R book picks up right at the very basics, but won't let you out in the rain once you get the stats going. This is probably the only book you will need in a very long time... Good luck getting started! S.
Hi Thomas, I encourage you with either Crawley's or Teetor's; they both nicely cover the very basics and provide some advanced applications. You may also check a course on 'Computing for Data Analysis' atcoursera.org, if you wish to get the basic foundations through interactive e-learning. However, and to wrap up, I would suggest Crawley's if you envision to establish a 'long-term relationship' with R. All the best,
It comes with a book written by its main developer and is very suitable for getting an overview of a new dataset. After a session you can see the equivalent R code the Actions on the UI have produced.
Here is a link to a number of books, videos, and guides for learning various aspects of R. This includes data management, statistics,ans visualization.
I found "Discovering Statistics using R" (Andy Field, Jeremy Miles, & Zoe Field) quite helpful, particularly if you need thorough explanations of statistics as well as R programming. The book usually gives very detailed step-by-step instructions of how to perform a test using R, as well as a lot of explanations on the background behind statistical tests. That said, it does contain some errors and inconsistencies, and I usually double-check the information with more reliable sources, depending on the topic. Particularly, for mixed models I recommend Pinheiro and Bates: "Mixed-Effects Models in S and S-PLUS" (as R is basically a further development of S, you can use the same code for R).
I discover in R a nice tools about packages. Instead of trying to learn everything right away, another option would be to learn directly packages that can provides you with a quick hand on tools and then follow with more deeper understanding on your way.
Also be aware that depending of your areas of interest and applications someone would already created a package that you can just apply to your problem.
And the nice thing about R, is that all packages are required to come with the package explanation book who is a nice place to learn about the package and also the function attributes.
Hope you will enjoy learning packages use in R.
this would be a nice place to start looking about Time series packages and it use
Brian Everett's Handbook of Statistical Analysis was where I began to get comfortable with R. I'd also recommend looking at the Journal of Statistical Software, a free online journal, which describes R packages with tutorials on their use.
Just to add some (hopefully) helpful context. My R book is basically the SPSS book but for R, so the examples are the same as is a lot of the theory. Having said that because R is such a different programme to SPSS, there are a lot of differences in approach/structure. The similarities can be good - in that you can replicate the examples that you know in SPSS but using R. As a learning tool this might be useful. It might also be a lot of pointless redundancy - depends how you look at it -. Different people will see it as a plus or a minus I suspect. Otherwise, I think Crawley's R book is very good and thorough, the website quick R is also great. R for dummies is extremely good for getting to grips with the R interface and manipulating data etc - it's probably he best book i have seen for this- but covers less applied stats as you might expect. I'm not familiar enough with the other books to comment.
Thank you again everyone for the helpful advice, perspectives, and recommendations! It looks like I'll be going through some of the free materials and buying a couple of different books. Cheers!
Andy Field wrote: "My R book is basically the SPSS book but for R, so the examples are the same as is a lot of the theory."
If that is so, that book would be worth looking into. The SPSS book is probably the most pleasant statistics book I've read and I learned a lot from it.
Hi Mitchell and Phillip: thanks for this answer. I had a look at some of the chapters (free download compare link below for chapter 1 from cran r). Is that similar to the textbook?
It's similar in that it covers some basics. The book has a lot more explanations. For example, it starts off with an extensive review of the help functions across mac, PC, and linux. Although the information in the link you cite is accurate, the book's more designed to get you up and running quickly with a lot of explanations along the way. It's a little like having someone thoroughly explain the interface. I think it's worth the money (I just ordered it as a Nook book recently).
Thanks Phillip, sounds really good. Please tell me more when you have the book. I had a download link this morning but unfortunately my university does not support that database otherwise I would owe it now :(
One more thing, for a more advanced user who already knows the basic operations: I learned *a lot* of R just by reading the fabulous manuals, reference manuals and studying the provided examples. Also, many packages contain vignettes or manuals, which are often v.v. good (in fact, many of them with time turned into actual books). Use the "?" and "??" from R command line a lot.
Hi January, thanks for that tipps. Actually I use the manuals as my first reference, as second the blocks. But yours sound better, I bookmark both (I just googled). What I now learned from you are two things: the "?" and the Cookbook. I had a look at it, it looks good. Thank you so much. I also looked at Mark Gardener: beginning R.
To start with i would consulate An Introduction to R which can be found athttp://cran.r-project.orgits free and gives you everything you need to get started. I would the suggest you move on tothe R Cookbook by Paul Teetor its a good guide but also acts as a good reference guide even for advanced users.
Also the guides on the R site can be a bit hit or miss but some are excellent.
I also like the books from Pfaff and his procedures, just for those who seek more alternatives :) Also some universities have an R team as for example ETH Zurich or Institute for Statistics of University Bern. So much from my side.
I know what tour feeling is like. I've been through it too. R is incredible and very versatile but at the "first date" it looks a bit cryptic. Personally, the 'R Book' is well done because example of scripts and, above all, explanations about the R outcome, which is not to underestimate! I reckon that book is a good starting point. Based on the aim of your analysis, probably you will need more reference from either other books or the R packages manuals. It's hard at the beginning but do not give up!
otherwise the R book by Crawley is great. Plus you can learn so much from all the resources online, esp stackoverflow. The atmosphere can be a little hostile sometimes towards new users, but as long as you demonstrate that you've tried some things, have done some reading and give reproducible code you're covered!
You can refer the guidance document of 'Biodiversity R'. It has got some advanced techniques. Also have a look at 'Applied Spatial Data Analysis with R' by Roger S. Bivand . Edzer J. Pebesma.
Considering the coverage you are looking for, I recommend "Numerical Ecology with R", by Daniel Borcard, François Gillet and Pierre Legendre, published in 2011 in the series "Use R!", Springer, XI + 306 pp. The examples are mainly from ecology, but the book leads you step by step through the application of most major techniques of multivariate data analysis. Seehttp://adn.biol.umontreal.ca/~numericalecology/
Many thanks, Sarah-Jo. It was helpful - R for SAS users, exactly what I needed! I rather use Google and other Internet possibilities than books. Books are expensive!
If you are using R outside of the world of statstics, I would recommend "The Art of R Programming" by Norman Matloff as a good reference for writing much more computationally and memory efficient R code.http://nostarch.com/artofr.htm
I would think Andy Field's text matches what you're looking for pretty exactly. You can always skip the bits you read in his SPSS version - I find there's lots I skip in his writing anyway :-)
Then it is a matter of reading the manuals of particular Packages you would instal when wanting to do something specific. that documentation which comes with R packages usually offer usefull examples.
Well, I see a plenty of extremely helpful suggestions here. But I would like to share my experience as a beginner of R during August 2011. The only things you need to learn as a beginner of R are:
1. The R operators.
2. The R object types and how to generate, coerce and exchange between them.
3. The R functions and how to write them with arguments.
And to learn them you don't need any book, they are well documented in "An Introduction to R" (http://www.r-project.org/) (someone has mentioned it already). The application of R became so diversified and out-reaching that you might only need book to learn very specific application oriented R programing. But what I do is typing in google what exactly I need to do in R. Believe me or not there are 100s of webpages waiting to help you and that yields far better results than digging into a book.
All the books mentioned above are really helpful but I do find the R book by Michael Crawley a real treasure. Not only it is helpful in learning R but it has also helped me get valuable insight on some statistical concepts. It is updated with some of the newest concepts in classification and data mining too.
Two books that illustrate how to use R when using ANOVA, MANOVA, ANCOVA and various regression methods are Wilcox (2012, Modern Statistics for the Social Sciences) and Wilcox (2012, Introduction to Robust Estimation and Hypothesis Testing). A possible appeal of these books it they also include modern robust methods that can substantially increase power when standard assumptions are violated.
To a beginner what I am suggesting is to start with R Commander package with R. Since this is menu driven this will act as a bridge from earlier software that you used to R. Using this package you can perform many basic statistics. Then use Quick R website (http://www.statmethods.net/) to understand some basic codes. In this stage one can read other relevant R books to understand the advanced features of R.
Duda please look at German Rodriguez's Introducing R athttp://data.princeton.edu/R. It simplifies R to the benefit of a beginner. It is one the materials that helped me conquer R.
If you already have experience managing data sets and doing statistical analysis in SAS or SPSS, examine the book "R for SAS and SPSS Users" by Robert Muenchen. He also wrote one for STATA users. Then get the book for you application, such as MANOVA.
I notice you also mention that you found the R "interface" a bit intimidating and that it was difficult to figure "how to actually use the application" ! You might find that RStudio (http://www.rstudio.com/ide/download/) helps you get over that obstacle. No doubt R gurus would spurn it in favor of Emacs (e.g.http://ess.r-project.org/) or some even plainer text editor, but it does make things much easier for a beginner, and is much more similar to programs you are familiar with such as SPSS and SAS.
I highly recommend Visualize This by Nathan Yau. Both this book and the author's blog, FlowingData contains lots of tutorials about using R in order to do some good statistics. Check a look at the blog and then decide! Cheers!!!
Yet another useful book is Using R for Introductory Statistics by John Verzani.
For more depth (regarding statistical methods) I recommend the "MASS" book (Modern Applied Statistics with S) by Ripley and Venables. (The S in the title refers to the language; the book is intended for both of its main implementations, the programs Splus and R.)
Note also that many R programs are accompanied by detailed instructions and papers with tutorials.
I'd agree that "Statistics. An introduction using R" by M. Crawley is very useful, both to learn R and understand statistics. It explains the fundamentals of the statistics and walks you through the R code.
Rstudio is a good interface (GUI), and R in Action (Kabacoff,R) and A Handbook of Statistical Analysis Using R (Everitt,BS; Hothorn, T) are excelent books.
Apart the books available in the R website (http://www.r-project.org, manual section), I started my adventure with R with the very useful Peter Dalgaard's book.
"Introductory Statistics with R" - Springer Editor
It will guide you from the basics of R and statistics until more advanced analysis.
Learning R is about practice, searching, trial and error. When you encounter a problem, Google is often the first choice. You will find answers quite often inhttp://stackoverflow.com/.
For the books, I think R in Action is a great reference, not only for statistics but also for data visualization. The book is systemically written and well-organized. The content covers the basic statistics and intermediate methods such as regression, permutation tests, generalized linear model, PCA, and dealing with missing data. At the same time, its companion website is also very useful:http://www.statmethods.net/. If you have already been familiar with the basic statistics, I think it's a nice start for you to practically learn R and use it!
And I'm still getting great recommendations! Thanks everyone so much for your time in responding to my question. Learning R will be one of my primary projects over winter break. Thank you again! :)
As one of the authors of R for Dummies, I'm bound to suggest that one to you as well. But I'd like to add a sidenote: R for Dummies looks at R from a programming point of view, not so much a statistical point of view.
We chose to take "the other route" as I have daily experience with the problems that arise due to copy-pasting solutions from other people without understanding the underlying structure of the objects and how to work with them. Yet, as R _is_ first and foremost a programming (scripting) language, you need a fair idea about how to work with the objects.
I get R users at my desk that even with more than 3 years of experience still don't know eg that a data frame is a list and not a matrix, and especially don't grasp the consequences of this fact.
As I noted to some critics before, everything you need to learn R is to be found for free on the internet. R for Dummies is merely a (hopefully useful) summary in a sequence we deemed suited to learn R from scratch.
But whatever you do, don't copy code you don't understand, and spend a fair amount of time figuring out the programming aspects, not only the statistical aspects of R.
I strongly recommend 'Using R as an Introductory Statistics' by John Verzani. I used it when learning R and it provided me with strong basis. Very good to teach you the R language and stats at the same time.
Georgia Southern University, Jiann-PIng Hsu College of Public Health
Try Clinical Trial Data Analysis with R by Din Chen and Karl Peace, published by Chapman/ Hall Biostatistics Series. You may also want to consider Applied Meta Analysis Using R, also by Chen and Peace and published by Chapman Hall Biostatistics Series.
I have used the Daalgard book, and I find it to be very helpful. Another book is "R in a Nutshell", by Joseph Adler, is a helpful reference, but don't expect to learn R from it.
Do any of the books have explanations with examples for things like generating permutation distributions or even MCMC methods?
Hi there! I discovered R by taking the Statistics, Data Analysis and Computing for Data Analysis classes onwww.coursera.org. I think the interactions and also the course materials and resources (some of which named above) would add value and more depth to your endeavour rather than only taking a book page by page. Good luck with your work!
If you're already comfortable with the statistics then I would not recommend Andy Field's book because (a) it focuses primarily on the statistics, spending much time (i.e., pages) on trying not to scare students away, and (b) it does not introduce R in the easiest possible way but tries to adapt R usage to the requirements of an SPSS stats book, resulting in examples that may start off scarier than necessary. I prefer a more bare-bones initial approach R, with a minimum of functions and external libraries, focusing on how simply and coherently you can get basic stuff done.
I concur with recommendations for online introductions, such as tutorials marked "for psychologists" and such in the "under 100 page" section of the R contributed documentation pages.
Having said that, I do recommend Field's book for someone who also needs to learn the stats starting at the beginning, for the well-known reasons that have made Field's book so popular with students.
Ministero dell'Istruzione, dell'Università e della Ricerca
For time series analysis I suggest you the book of Shumway and Stoffer. For regression the newest book of Fahrmeir et al, "REGRESSION", which has a lot of updated example in R, STATA and other packages. For simple programmingwww.datamind.org.
Thomas, if you haven't already, I would recommend downloading R-Studio which is a popular 'integrated development environment'. It includes lots of features that make using R easier including adding in additional packages which is a common task.
I would recommend r in a nutshell by Adler and intro stat with R by Dalgaard. Both are so helpful. QuickR website is also a good source for elementary level.
Murray Logan's Book (Practical Design and Analysis Using R: A practical guide) is fine to began an introduction to R. For multivariate analysis (PCA, CCA, RDA,...) I can suggest you try the website of ade4 package, but the problem, may be, it is in French. However, there is the adelist, that is a mailing list used to announce news about the ade4 package for R, and to allow users to exchange informations. For the time serie analysis, you have Woods' Book on Generalized Additive Models in R. You have also a R-tutorial, of ~20 pages, about the time series analysis with R (Zucchini and Nemadé, Time series analysis with R - part I). You can go to see also athttp://a-little-book-of-r-for-time-series.readthedocs.org/en/latest/src/timeseries.html.
R has a tremendous number of resources you can use. In this sense I suggest to go to the Contributed Documentation in the CRAN website (see Manuals\Contributed Documentations at bottom of the page):
Here you can find surely guide for the majority of the statistical techniques you are planning to use. Please consider that sometime you can need some other tutorials or guides so my suggestion is to be aware on the powerful search engines which allow to find statistical techniques of interest. So you can use:
Last but not least you can use from the package "sos" a function: findFn which allow to search of the method (for example) in the various package it is possible to install.
Uniformed Services University of the Health Sciences
Dear Thomas, I second Xuanlong's recommendation for the "Intro to R tutorial". It summarizes very important basics. There is a Youtube video that covers the Intro to R at
With just these basics behind you, and as with any programming language, the best way to learn is to start programming on a problem that interests you. Regardless of what platform you use, you should have two windows open, at least, one interactive and one text editor. This can be done many ways: Rstudio to emacs... Use the manual: "?plot", "?randomForest", etc. Every manual page has one or more examples that you can run. This, in my opinion, is the best text.
LandCover.ai: Dataset for Automatic Mapping of Buildings, Woodlands and Water from Aerial Imagery
For project and dataset: https://www.catalyzex.com/paper/arxiv:2005.02264
They collected images of 216.27 sq. km lands across Poland, a country in Central Europe, 39.51 sq. km with resolution 50 cm per pixel and 176.76 sq. km with resolution 25 cm per pixel and manually fine annotated three following classes of objects: buildings, woodlands, and water.
오늘 소개드릴 논문은 흥미로운 응용사례와 같이 설명드리겠습니다. 최근에 보고있는 논문들이 ICLR이나 CVPR 최근 논문 + 실사례 적용을 하는 것 위주로 보고 있는데 이 사례도 꽤나 재미있었습니다. [응용 사례 - AR-Cut Paste] 우선 첫 번째 동영상을 보시면 얼핏보면 한 10년전에도 하던 ARTag를 인식한 후 사전에 저장해놓은 이미지를 불러와서 맥북과 연동한 것처럼 보입니다. 그런데 실제로는 ARTag가 아니라 saliency maps(관심영역)을 구하고 그 영역을 세밀하게 segmentation하여 그 그림을 맥북으로 전송한 것입니다. Code : https://github.com/cyrildiagne/ar-cutpaste/tree/clipboard [U^2-Net: Going Deeper with Nested U-Structure for Salient Object Detection] 위 사례에서 메인 물체의 백그라운드를 제거하는 기술은(saliency object detetion -> segmentation) U^2-Net이라는 논문을 베이스로 만들었습니다. 그런데 아쉽게도 해당 논문은 accept 승인중이라 아직 공개가 안되었고 개념도만 오픈되어 있습니다. 그 대신 코드가 미리 공개되어있는데 해당 코드를 통해 아래 첨부된 총, 글씨, 사람을 찾고 깔끔하게 분리해냈습니다. 저자가 조만간 논문을 공개한다고하니 추후 확인해봐야겠지만 공개한 주요 알고리즘별 성능표를 보면 아래 그림과 같이 (아마도) SOTA 성능을 내는 것으로 보입니다. 총 6개 데이터셋을 비교했는데 PASCAL-S를 제외하고 가장 압도적인 성능을 보입니다. 네트워크 구조도 오픈되어있는데 그림만 보면 U-Net들을 모아서 또 하나의 U-Net을 만들어서 나온 결과물을 fuse하여 최종 결과물로 쓰는것으로 보입니다. (U-Net 논문은 이 글 맨 아래에 언급됩니다.) [BASNet: Boundary-Aware Salient Object Detection] 이전에 해당 저자의 Basenet(CVPR '19) 논문을 보면(9번째 사진) Predict Module에서 1차로 coarse map을 뽑고 Residual Refinement Module에서 refined된 map을 뽑도록 되어있습니다. Predict Module은 U-Net의 아이디어를 많이 쓴것으로 보이는데 Resnet-34를 베이스로 하지만 일부 res-block을 수정했고, RRM 단계에서도 좀 더 하이레벨의 refine값을 얻기위해 더 깊은 모델을 만들어서 적용했습니다. RRM 에 관련해서는 엄청 유명한 논문인 Large kernel matters : improve semantic segmen-tation by global convolutional network. (CVPR '17) 을 참고해보시면 좋습니다. [추가 논문] Silency Object Segmetation(Detection) 분야를 이해하기 위해서는 사전에 중요한 논문 2가지를 추가로 보는 것이 좋습니다. 해당 분야는 나온지 꽤 되긴했는데(저도 석사때 관련 논문을 썼습니다;) Fully Convolutional Networks for Semantic Segmentation (CVPR '15) Segmentation을 위해서 만든 네트워크에 마지막 dense 부분에 FC-Layer 대신 Conv-Layer로 교체하고 Skip architechture를 제안하여 segmentation에 새로운 방향을 제시한 논문으로 무려 15000회 이상 인용되었습니다. 교체한 이유는 Segmentation시 위치 정보와 이미지 사이즈 등이 중요한데 FC Layer는 위치 정보 유실이나 사이즈 고정등의 이슈가 있어서 이것을 개선하고자 제안했습니다. Receptive Field 개념도 같이 봐두시면 좋습니다. U-Net: Convolutional Networks for Biomedical Image Segmentation (MICCAI 2015) 특이하게(?) 메디컬 영상 학회에 실렸던 논문입니다. 이 논문도 13800회 이상 인용될 정도로 중요합니다. 맨 마지막 그림을 보시면 왜 U^2-Net 설명할때 언급했는지 아실것 입니다. 이렇게 특이한 네트워크 구조를 가지는 이유는 U자 모양에 왼쪽은 Contracting Path라고해서 입력 이미지를 Down-sampling을 하며 context caption 역할을 합니다.(VGG based). 오른쪽은 Expanding Path로 Up-sampling을 하며 정교한 Localization을 목적으로 합니다. 그리고 Contracting Path에서 Max-Pooling전의 feature map을 Crop 하여 concat을 하여 각 정보를 연결합니다. 그외에도 Augment 등의 공헌이 있었습니다. 혼자 보는용으로 정리해둔건 많은데 공유하려고 정리해서 다시 요약하는데 생각보다 시간이 오래걸리네요. 곧 출근시간이 다가와서 여기에서 마무리하고 또 1-2주 후에 새로운 논문 공유하겠습니다.
Clustering is an important part of the machine learning pipeline for business or scientific enterprises utilizing data science. As the name suggests, it helps to identify congregations of closely related (by some measure of distance) data points in a blob of data, which, otherwise, would be difficult to make sense of.
However, mostly, the process of clustering falls under the realm ofunsupervised machine learning. And unsupervised ML is a messy business.
There is no known answers or labels to guide the optimization process or measure our success against. We are in the uncharted territory.
Machine Learning for Humans, Part 3: Unsupervised Learning
Clustering and dimensionality reduction: k-means clustering, hierarchical clustering, PCA, SVD.
medium.com
It is, therefore, no surprise, that a popular method likek-means clusteringdoes not seem to provide a completely satisfactory answer when we ask the basic question:
“How would we know the actual number of clusters, to begin with?”
This question is critically important because of the fact that the process of clustering is often a precursor to further processing of the individual cluster data and therefore, the amount of computational resource may depend on this measurement.
In the case of a business analytics problem, repercussion could be worse. Clustering is often done for such analytics with the goal of market segmentation. It is, therefore, easily conceivable that, depending on the number of clusters, appropriate marketing personnel will be allocated to the problem. Consequently, a wrong assessment of the number of clusters can lead to sub-optimum allocation of precious resources.
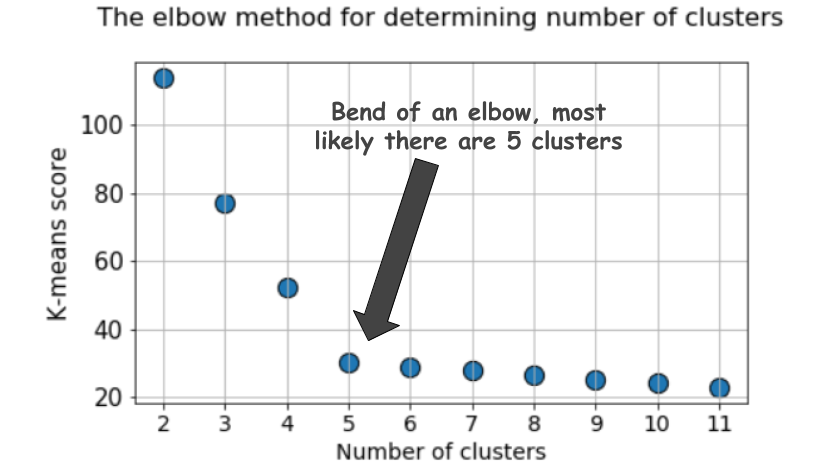
For the k-means clustering method, the most common approach for answering this question is the so-calledelbow method. It involves running the algorithm multiple times over a loop, with an increasing number of cluster choice and then plotting a clustering score as a function of the number of clusters.
What is the score or metric which is being plotted for the elbow method? Why is it called the ‘elbow’ method?
A typical plot looks like following,
The score is, in general, a measure of the input data on the k-means objective function i.e.some form of intra-cluster distance relative to inner-cluster distance.
For example, in Scikit-learn’sk-means estimator, ascoremethod is readily available for this purpose.
But look at the plot again. It can get confusing sometimes. Is it 4, 5, or 6, that we should take as the optimal number of clusters here?
Not so obvious always, is it?
Silhouette coefficient — a better metric
TheSilhouette Coefficientis calculated using the mean intra-cluster distance (a) and the mean nearest-cluster distance (b) for each sample. The Silhouette Coefficient for a sample is(b - a) / max(a, b). To clarify,bis the distance between a sample and the nearest cluster that the sample is not a part of. We can compute the mean Silhouette Coefficient over all samples and use this as a metric to judge the number of clusters.
Here is a video from Orange on this topic,
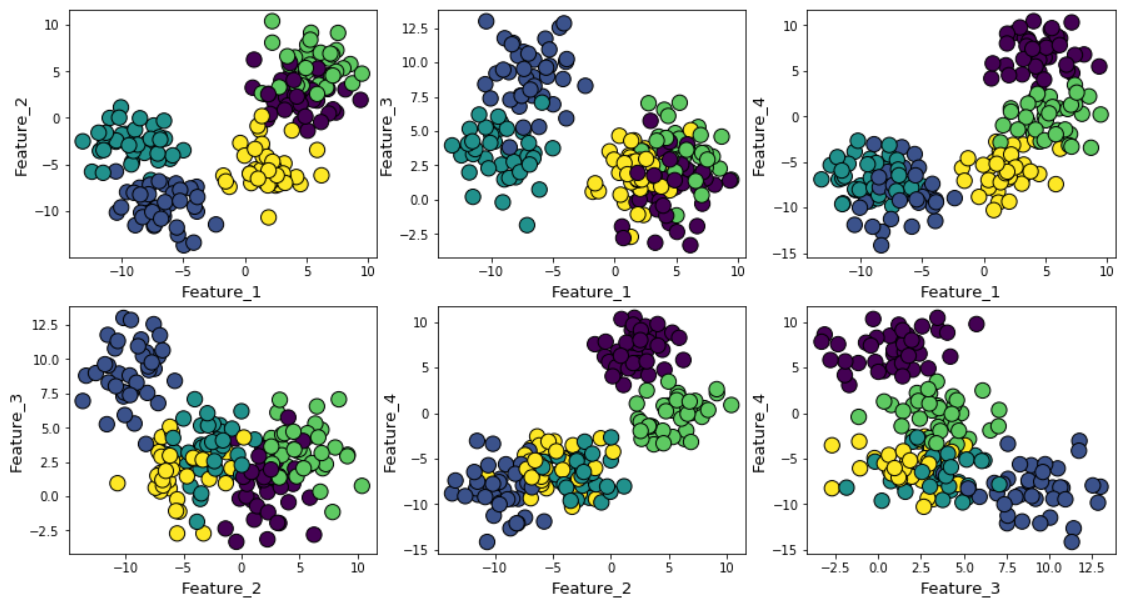
For illustration, we generated random data points using Scikit-learn’smake_blobfunction over 4 feature dimensions and 5 cluster centers. So, the ground truth of the problem is that thedata is generated around 5 cluster centers. However, the k-means algorithm has no way of knowing this.
The clusters can be plotted (pairwise features) as follows,
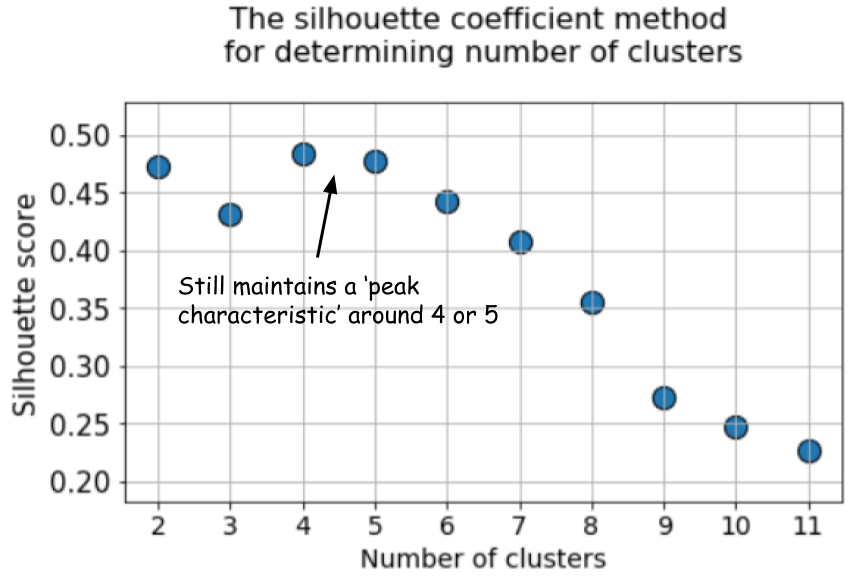
Next, we run k-means algorithm with a choice ofk=2 tok=12 and calculate the default k-means score and the mean silhouette coefficient for each run and plot them side by side.
The difference could not be starker. The mean silhouette coefficient increases up to the point whenk=5 and then sharply decreases for higher values ofki.e.it exhibits a clear peak atk=5,which is the number of clusters the original dataset was generated with.
Silhouette coefficient exhibits a peak characteristic as compared to the gentle bend in the elbow method. This is easier to visualize and reason with.
If we increase the Gaussian noise in the data generation process, the clusters look more overlapped.
In this case, the default k-means score with elbow method produces even more ambiguous result. In the elbow plot below, it is difficult to pick a suitable point where the real bend occurs. Is it 4, 5, 6, or 7?
But the silhouette coefficient plot still manages to maintain a peak characteristic around 4 or 5 cluster centers and make our life easier.
In fact, if you look back at the overlapped clusters, you will see that mostly there are 4 clusters visible — although the data was generated using 5 cluster centers, due to high variance, only 4 clusters are structurally showing up. Silhouette coefficient picks up this behavior easily and shows the optimal number of clusters somewhere between 4 and 5.
BIC score with a Gaussian Mixture Model
There are other excellent metrics for determining the true count of the clusters such asBayesianInformationCriterion(BIC) but they can be applied only if we are willing to extend the clustering algorithm beyond k-means to the more generalized version —GaussianMixtureModel (GMM).
Basically, a GMM treats a blob of data as a superimposition of multiple Gaussian datasets with separate mean and variances. Then it applies theExpectation-Maximization (EM) algorithmto determine these mean and variances approximately.
Gaussian Mixture Models Explained
In the world of Machine Learning, we can distinguish two main areas: Supervised and unsupervised learning. The main…
towardsdatascience.com
The idea of BIC as regularization
You may recognize the term BIC from statistical analysis or your previous interaction with linear regression. BIC and AIC (Akaike Information Criterion) are used as regularization techniques in linear regression for the variable selection process.
BIC/AIC is used for regularization of linear regression model.
The idea is applied in a similar manner here for BIC. In theory, extremely complex clusters of data can also be modeled as a superimposition of a large number of Gaussian datasets.There is no restriction on how many Gaussians to use for this purpose.
But this is similar to increasing model complexity in linear regression, where a large number of features can be used to fit any arbitrarily complex data, only to lose the generalization power,as the overly complex model fits the noise instead of the true pattern.
The BIC method penalizes a large number of Gaussiansand tries to keep the model simple enough to explain the given data pattern.
The BIC method penalizes a large number of Gaussians i.e. an overly complex model.
Consequently, we can run the GMM algorithm for a range of cluster centers, and the BIC score will increase up to a point, but after that will start decreasing as the penalty term grows.
We discussed a couple of alternative options to the often-used elbow method for picking up the right number of clusters in an unsupervised learning setting using the k-means algorithm.
We showed that Silhouette coefficient and BIC score (from the GMM extension of k-means) are better alternatives to the elbow method for visually discerning the optimal number of clusters.
Ifyou have any questions or ideas to share, please contact the author attirthajyoti[AT]gmail.com. Also, you can check the author’sGitHubrepositoriesfor other fun code snippets in Python, R, and machine learning resources. If you are, like me, passionate about machine learning/data science, please feel free toadd me on LinkedInorfollow me on Twitter.
Latest from MIT researchers: A new methodology for lidar super-resolution with ground vehicles
For project and code or API request: https://www.catalyzex.com/paper/arxiv:2004.05242
To increase the resolution of the point cloud captured by a sparse 3D lidar, they convert this problem from 3D Euclidean space into an image super-resolution problem in 2D image space, which is solved using a deep convolutional neural network