60 #Interview #Questions On #MachineLearning https://analyticsindiamag.com/60-in
Data Science 2020. 2. 10. 17:15https://analyticsindiamag.com/60-interview-questions-on-machine-learning/
https://analyticsindiamag.com/60-interview-questions-on-machine-learning/
Machine Learning From Scratch
GitHub, by Erik Linder-Norén : https://github.com/eriklindernoren/ML-From-Scratch
#ArtificialIntelligence #DeepLearning #MachineLearning
Machine Learning From Scratch. Bare bones NumPy implementations of machine learning models and algorithms with a focus on accessibility. Aims to cover everything from linear regression to deep learning.
Python implementations of some of the fundamental Machine Learning models and algorithms from scratch.
The purpose of this project is not to produce as optimized and computationally efficient algorithms as possible but rather to present the inner workings of them in a transparent and accessible way.
$ git clone https://github.com/eriklindernoren/ML-From-Scratch $ cd ML-From-Scratch $ python setup.py install
$ python mlfromscratch/examples/polynomial_regression.py
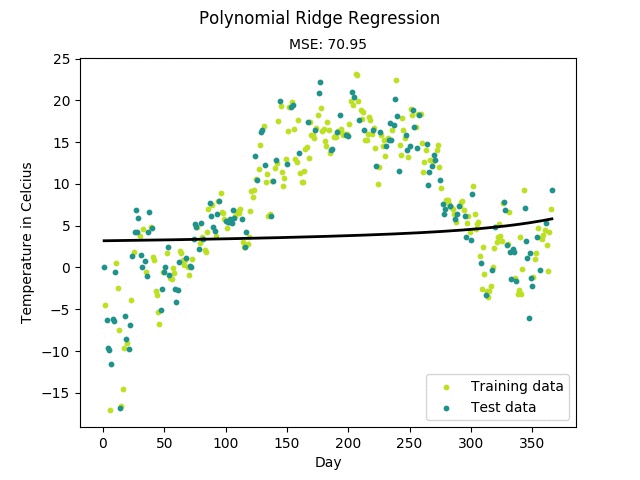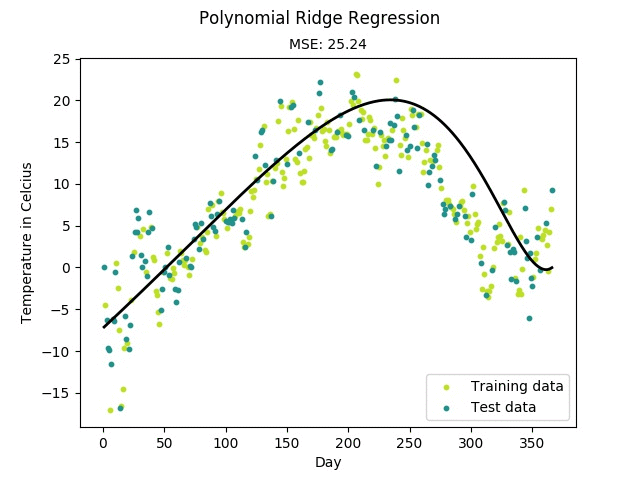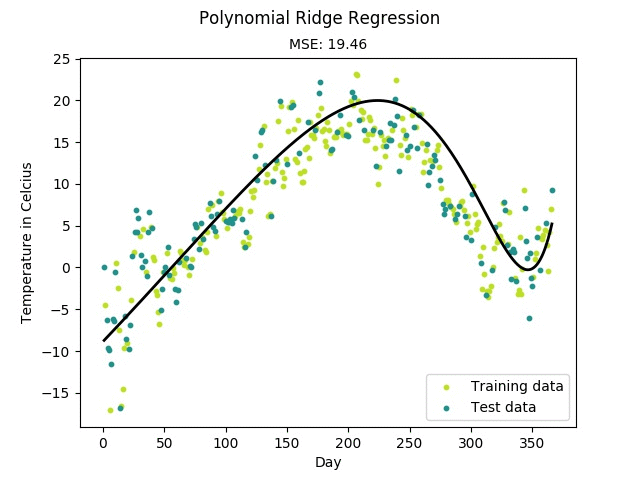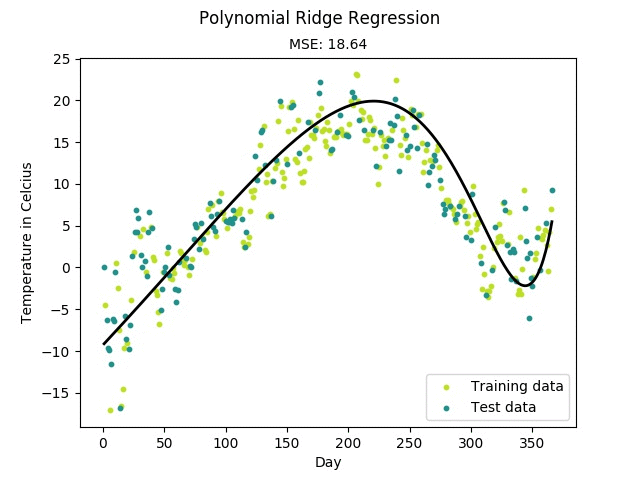
Figure: Training progress of a regularized polynomial regression model fitting
temperature data measured in Linköping, Sweden 2016.
$ python mlfromscratch/examples/convolutional_neural_network.py +---------+ | ConvNet | +---------+ Input Shape: (1, 8, 8) +----------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +----------------------+------------+--------------+ | Conv2D | 160 | (16, 8, 8) | | Activation (ReLU) | 0 | (16, 8, 8) | | Dropout | 0 | (16, 8, 8) | | BatchNormalization | 2048 | (16, 8, 8) | | Conv2D | 4640 | (32, 8, 8) | | Activation (ReLU) | 0 | (32, 8, 8) | | Dropout | 0 | (32, 8, 8) | | BatchNormalization | 4096 | (32, 8, 8) | | Flatten | 0 | (2048,) | | Dense | 524544 | (256,) | | Activation (ReLU) | 0 | (256,) | | Dropout | 0 | (256,) | | BatchNormalization | 512 | (256,) | | Dense | 2570 | (10,) | | Activation (Softmax) | 0 | (10,) | +----------------------+------------+--------------+ Total Parameters: 538570 Training: 100% [------------------------------------------------------------------------] Time: 0:01:55 Accuracy: 0.987465181058
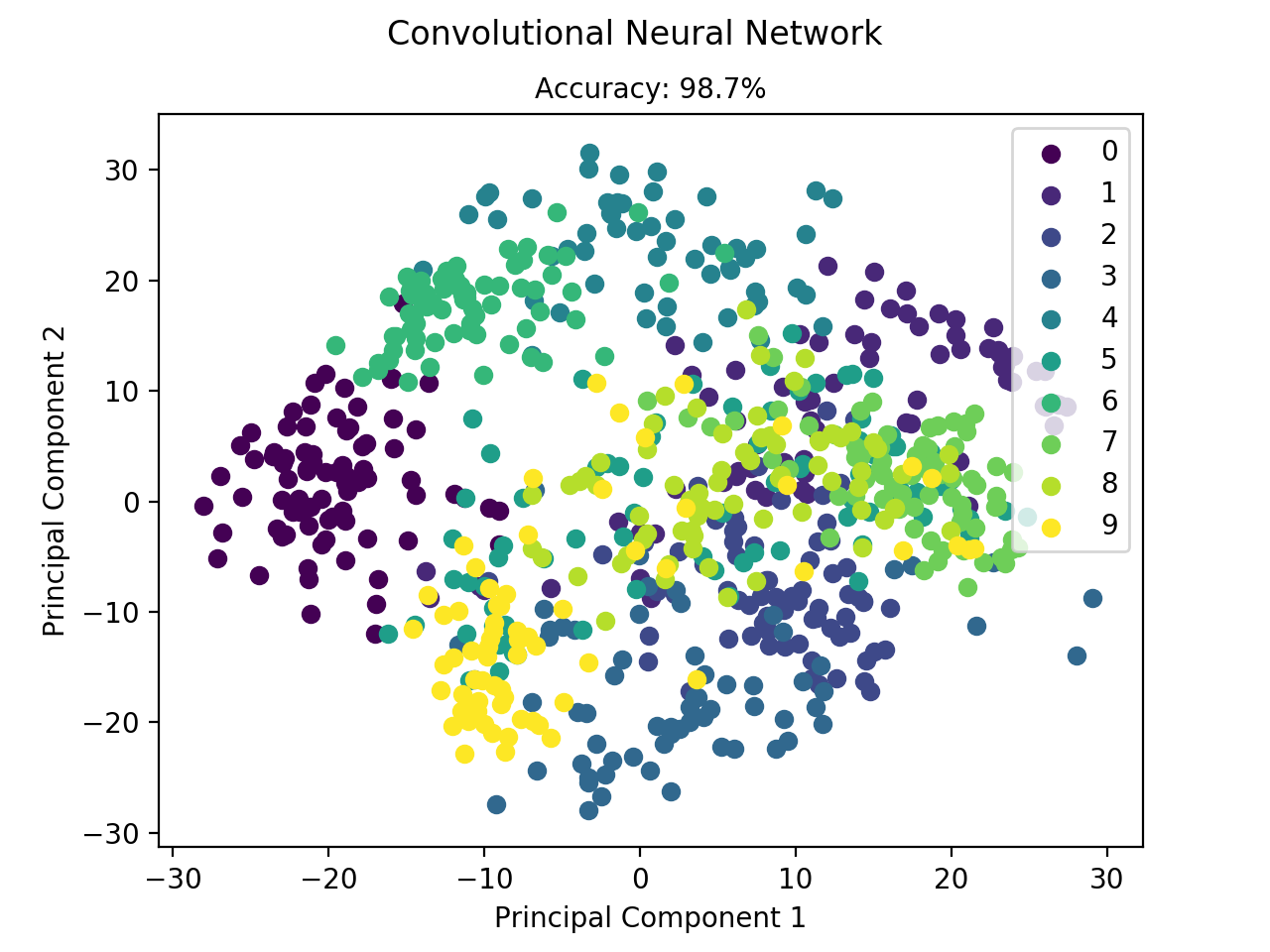
Figure: Classification of the digit dataset using CNN.
$ python mlfromscratch/examples/dbscan.py
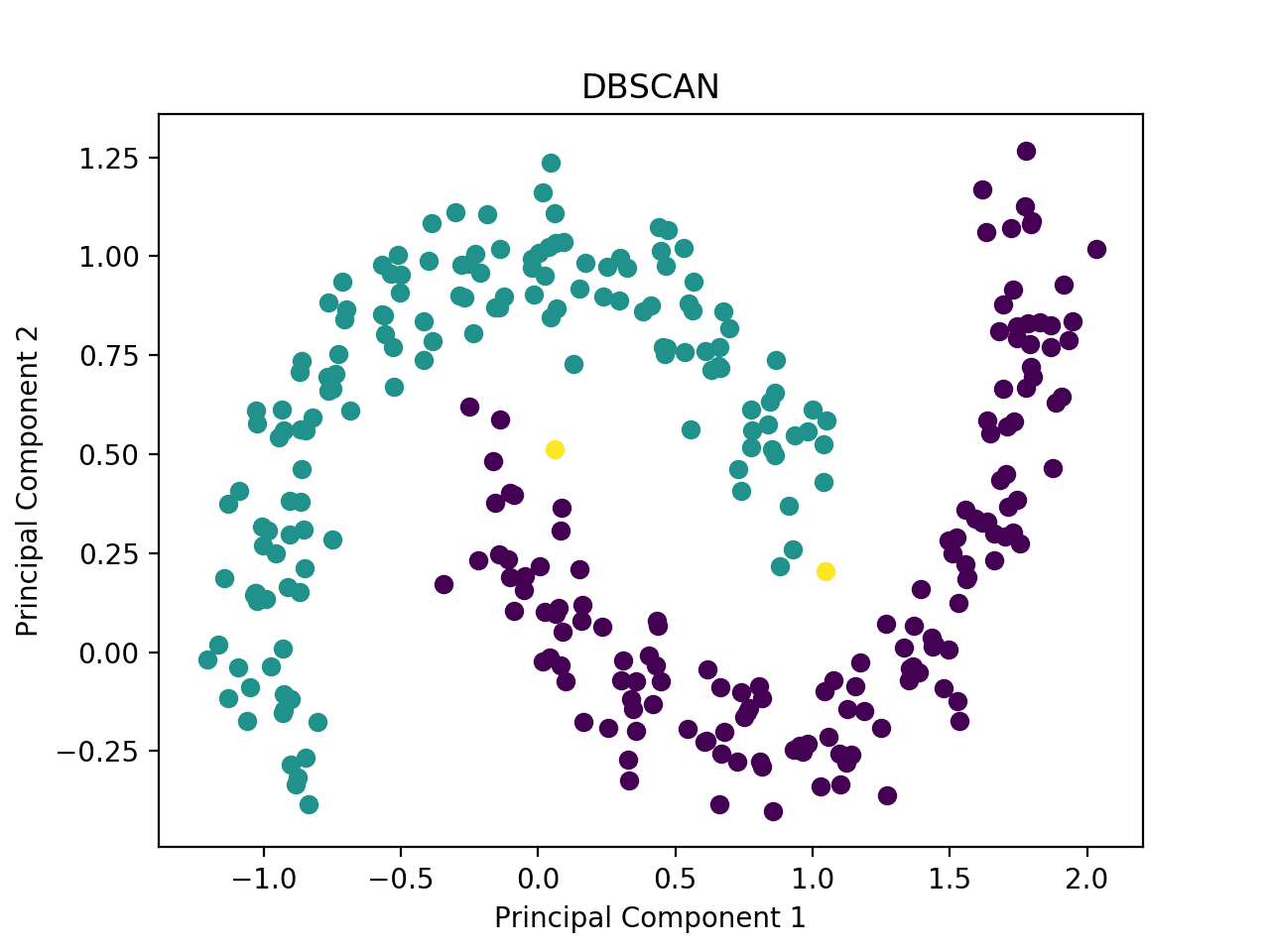
Figure: Clustering of the moons dataset using DBSCAN.
$ python mlfromscratch/unsupervised_learning/generative_adversarial_network.py +-----------+ | Generator | +-----------+ Input Shape: (100,) +------------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +------------------------+------------+--------------+ | Dense | 25856 | (256,) | | Activation (LeakyReLU) | 0 | (256,) | | BatchNormalization | 512 | (256,) | | Dense | 131584 | (512,) | | Activation (LeakyReLU) | 0 | (512,) | | BatchNormalization | 1024 | (512,) | | Dense | 525312 | (1024,) | | Activation (LeakyReLU) | 0 | (1024,) | | BatchNormalization | 2048 | (1024,) | | Dense | 803600 | (784,) | | Activation (TanH) | 0 | (784,) | +------------------------+------------+--------------+ Total Parameters: 1489936 +---------------+ | Discriminator | +---------------+ Input Shape: (784,) +------------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +------------------------+------------+--------------+ | Dense | 401920 | (512,) | | Activation (LeakyReLU) | 0 | (512,) | | Dropout | 0 | (512,) | | Dense | 131328 | (256,) | | Activation (LeakyReLU) | 0 | (256,) | | Dropout | 0 | (256,) | | Dense | 514 | (2,) | | Activation (Softmax) | 0 | (2,) | +------------------------+------------+--------------+ Total Parameters: 533762

Figure: Training progress of a Generative Adversarial Network generating
handwritten digits.
$ python mlfromscratch/examples/deep_q_network.py +----------------+ | Deep Q-Network | +----------------+ Input Shape: (4,) +-------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +-------------------+------------+--------------+ | Dense | 320 | (64,) | | Activation (ReLU) | 0 | (64,) | | Dense | 130 | (2,) | +-------------------+------------+--------------+ Total Parameters: 450

Figure: Deep Q-Network solution to the CartPole-v1 environment in OpenAI gym.
$ python mlfromscratch/examples/restricted_boltzmann_machine.py

Figure: Shows how the network gets better during training at reconstructing
the digit 2 in the MNIST dataset.
$ python mlfromscratch/examples/neuroevolution.py +---------------+ | Model Summary | +---------------+ Input Shape: (64,) +----------------------+------------+--------------+ | Layer Type | Parameters | Output Shape | +----------------------+------------+--------------+ | Dense | 1040 | (16,) | | Activation (ReLU) | 0 | (16,) | | Dense | 170 | (10,) | | Activation (Softmax) | 0 | (10,) | +----------------------+------------+--------------+ Total Parameters: 1210 Population Size: 100 Generations: 3000 Mutation Rate: 0.01 [0 Best Individual - Fitness: 3.08301, Accuracy: 10.5%] [1 Best Individual - Fitness: 3.08746, Accuracy: 12.0%] ... [2999 Best Individual - Fitness: 94.08513, Accuracy: 98.5%] Test set accuracy: 96.7%
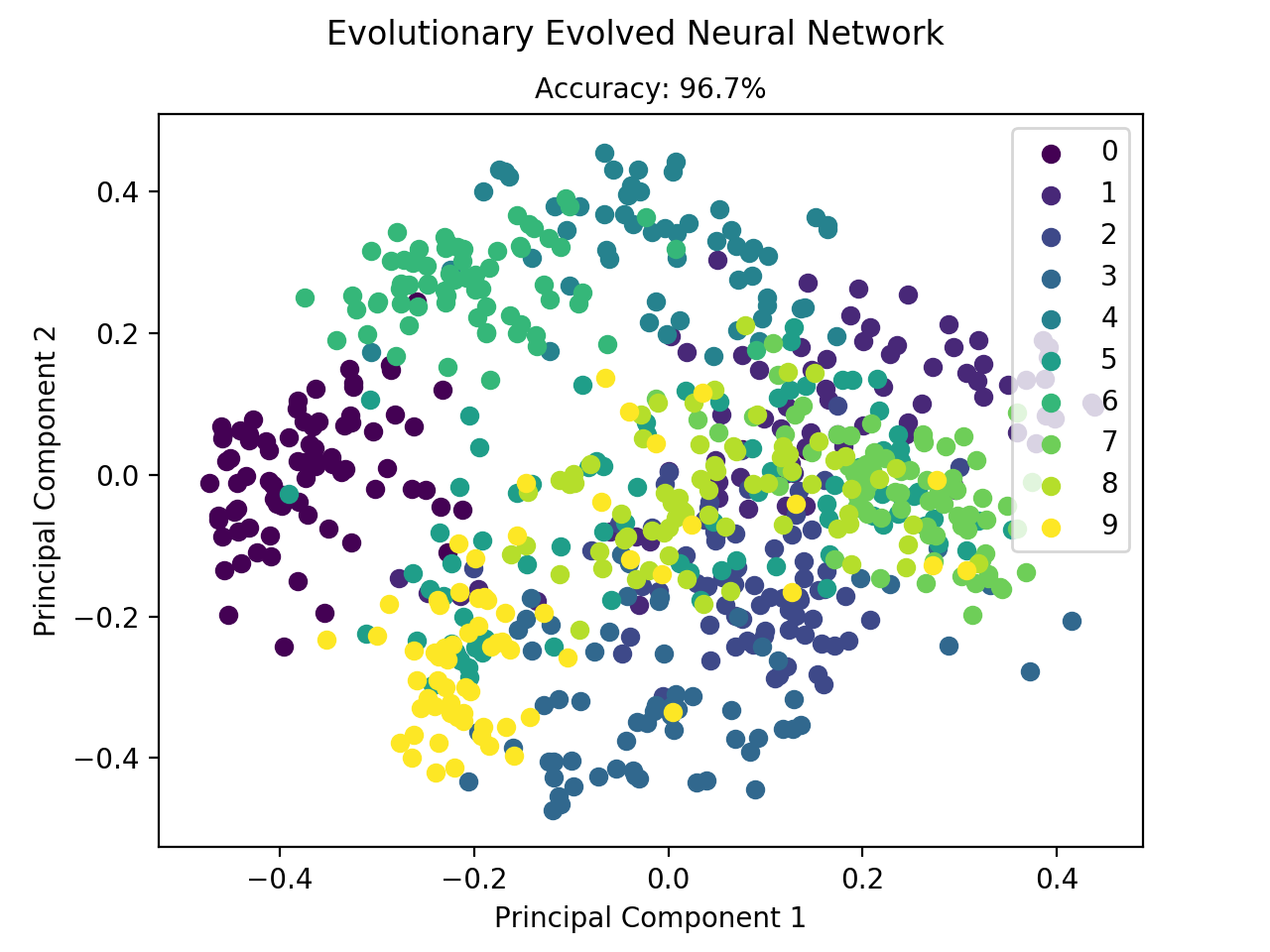
Figure: Classification of the digit dataset by a neural network which has
been evolutionary evolved.
$ python mlfromscratch/examples/genetic_algorithm.py +--------+ | GA | +--------+ Description: Implementation of a Genetic Algorithm which aims to produce the user specified target string. This implementation calculates each candidate's fitness based on the alphabetical distance between the candidate and the target. A candidate is selected as a parent with probabilities proportional to the candidate's fitness. Reproduction is implemented as a single-point crossover between pairs of parents. Mutation is done by randomly assigning new characters with uniform probability. Parameters ---------- Target String: 'Genetic Algorithm' Population Size: 100 Mutation Rate: 0.05 [0 Closest Candidate: 'CJqlJguPlqzvpoJmb', Fitness: 0.00] [1 Closest Candidate: 'MCxZxdr nlfiwwGEk', Fitness: 0.01] [2 Closest Candidate: 'MCxZxdm nlfiwwGcx', Fitness: 0.01] [3 Closest Candidate: 'SmdsAklMHn kBIwKn', Fitness: 0.01] [4 Closest Candidate: ' lotneaJOasWfu Z', Fitness: 0.01] ... [292 Closest Candidate: 'GeneticaAlgorithm', Fitness: 1.00] [293 Closest Candidate: 'GeneticaAlgorithm', Fitness: 1.00] [294 Answer: 'Genetic Algorithm']
$ python mlfromscratch/examples/apriori.py +-------------+ | Apriori | +-------------+ Minimum Support: 0.25 Minimum Confidence: 0.8 Transactions: [1, 2, 3, 4] [1, 2, 4] [1, 2] [2, 3, 4] [2, 3] [3, 4] [2, 4] Frequent Itemsets: [1, 2, 3, 4, [1, 2], [1, 4], [2, 3], [2, 4], [3, 4], [1, 2, 4], [2, 3, 4]] Rules: 1 -> 2 (support: 0.43, confidence: 1.0) 4 -> 2 (support: 0.57, confidence: 0.8) [1, 4] -> 2 (support: 0.29, confidence: 1.0)
If there's some implementation you would like to see here or if you're just feeling social, feel free to email me or connect with me on LinkedIn.
안녕하세요 Lidar SLAM공부중인 김기섭 입니다
#
지난주에 SLAM덩크 스터디에서 이종훈 님께서 레인지넷에 대해 소개해주셨는데요,
19 ICCV에 소개된 시맨틱 키티라는 point-wise 로 fully labeled 된 dataset이 있었기에 가능했던 연구였습니다.
#
시맨틱키티는
28가지 종류의 라벨 (도로, 폴, 인도, 자동차, 사람 등) 및
movable 한 object의 경우 (자동차, 사람 등) instance ID 또한 제공합니다.
이 정보를 이용하면 기존 segmentation work 뿐 아니라 object tracking 또는 dynamic/static 판별 등의 연구도 진행할 수 있을 것 같네요.
예시 영상입니다 https://youtu.be/gNeEfPEyHuw
#
저자가 공개한 파이썬API도 공개되어 있습니다.
https://github.com/PRBonn/semantic-kitti-api
저는 개인적으로 매트랩을 선호해서 매트랩 API도 간단히 만들어보았습니다.
https://github.com/kissb2/semantickitti-matlab
#
시맨틱 라이다 슬램 연구 관심 많으신분들 함께해요
감사합니다.
안녕하세요!
최근 ImageNet 에 SOTA 를 찍은 논문입니다.
https://arxiv.org/abs/1911.04252
캐글에서 많이 보던 pseudo-labeling 이 들어가있네요!
대략 정리하면
1. Train the teacher model with labeled data
2. Generate pseudo label for unlabeled data with teacher model
3. Train the student model with both labeled data and unlabeled data
4. Generate pseudo label for unlabeled data with teature model (student model in step 3)
5. Train the student model with both labeled data and unlabeled data
위 과정을 계속 반복합니다 ㅎ
성능이 매우 좋아지네요!
캐글에서 메달 따려면, SOTA 논문을 잘 보고, 그대로 쓰면 되겠죠?
https://www.facebook.com/groups/PyTorchKR/permalink/1620762534730088/
Pytorch로 image classification 작업하는 분들을 위해 좋은 github을 소개합니다.
https://github.com/rwightman/pytorch-image-models
(pip install timm이나 git clone https://github.com/rwightman/pytorch-image-models 등으로 사용하실 수 있습니다.)
이전에도 efficientnet code에 대해서 소개해드린 코드베이스입니다.
EfficientNet, ResNet, HRNet, SelecSLS등 다양한 모델들과 pretrained weight들을 갖추고 있으며, 모듈러 구조로 다양한 batchnorm, activation, 트레이닝트릭등(Autoaugment 등) 을 쉽게 사용할 수 있도록 짜여있습니다.
개인이 만든것이라고 생각하기에는 놀라울정도로 다양한 모델들과 아키텍쳐를 갖추고 있는데요, maintainer 본인이 여러 업무나 kaggle대회를 진행하거나 논문들을 살펴보면서 맞이하는 코드등을 쌓아가면서 코드를 형성했다고합니다.
최근에 네이버 클로버ai에서 resnet을 재구성하여 이전에 sota였던 efficientnet을 능가하는 assemblenet이 나온 후, 여기 maintainer도 tensorflow로 구성되어있던 원래의 코드를 pytorch로 구현하는 작업에 매진하고 있는 모양입니다.
현재는 selective kernel network를 구현하고 있는데요 이미 다양한 최적화, 모듈화가 가능한 자신의 코드베이스에 맞게 재구성중인 모양입니다.
저 개인적으로는 해당 assemblenet 논문의 결론부에서 언급된 ECA- Net(efficient channel attention)을 나름대로 재구성해서 해당 github에 pull request를 보내놓은 상태입니다.
이 과정에서 원래 ECA 논문(https://arxiv.org/pdf/1910.03151.pdf)
의 잠재적인 한계에 봉착하였습니다.
ECA 원문에서는 channel간의 결과를 convolution할때 kernel size에 맞게 zero padding하게 됩니다.
그러나 채널들간의 관계는 인접한 픽셀이나 feature map과는 다르기 때문에 zero padding하는게 무의미하다고 생각하였습니다.
"첫"채널이나 "마지막"채널은 기하학적이거나 위상적인 의미를 지니지 않을 것이기 때문에 더 zeropadding하여 더 적은 channel과 convolution하기보다는 circular padding을 통해 모든 채널이 같은 갯수의 서로 다른 채널들과 convolution하는게 논리적으로 맞다고 생각합니다.
그러한 논리적 접근에 따라 circular ECA module을 구현하여 함께 pull request를 하였지만, 꼭 해당 코드에만 사용해야하는 것은 아니라 이러한 attention module(ECA든 cECA든) 이 적합하다고 생각하시는 분이라면 참고해서 쓰실 수있으셨으면 좋겠습니다.
ECA PR: https://github.com/rwightman/pytorch-image-models/pull/82
해당 repo를 fork하여 eca를 구현한 제 코드
https://github.com/VRandme/pytorch-image-models/tree/eca
ECA가 SE, CBAM등 여태까지 나온 대부분의 attention model보다 우수한 성능을 보여주었는데, 저는 아직도 spatial attention을 구현한 CBAM에 미련이 남습니다.
그래서 이 코드가 정리되면 CBAM의 채널 attention부분만 ECA로 교체한 ECABAM?을 구현해볼 예정입니다.
안타깝게도 아직은 ImageNet수준의 트레이닝/테스팅을 수행할만한 여건이 되지 않아서 유의미한 진행은 어려울것같은데요, 곧 google collab에서 9.99$/mo로 무료 서비스와 차별화된 서비스를 제공한다고하니 한국에도 출시되면 알아봐야겠습니다.
관심있는 분들 살펴봐주시고 잘못된 부분등은 얼마든지 지적해주시기바랍니다. 감사합니다.
State of the art in image translation (guided)
https://www.profillic.com/paper/arxiv:2002.01048
Applications in facial expression generation, hand gesture translation, person image generation, cross view image translation etc.
(The proposed SelectionGAN explicitly utilizes the semantic guidance information and consists of two stages)
KB금융그룹 문자 분석 경진대회의 수상자가 가려졌습니다.
수고하셨습니다. 코로나 때문에 아쉽게 시상식은 열리지 못했지만
데이콘에서 2주 후 밋업을 개최할 예정입니다.
👑1. 참여 통계
a.참여팀 438 팀
b.참여인원 960 명
🌝2. public_test 검증횟수 6,349 회
a.리더보드 팀 수 373 팀
b.데이터 다운로드 수 2127 회
c. 우승자 점수 (최종 순위 순)
🎉팀명 AUC Infer Time 점수 상금
1.스팸구이 0.999405 6.827 1.3(1) 1000
2.Jhw 0.999058 7.512 3(2) 500
3.지주 0.998289 16.780 5.3(3) 250
4.Start Over 0.9992 3185.950 5.9(4) 100
5.곱창전골저아 0.998474 109.3967 6.1(5) 50
6.곰다리 0.997967 9.825 6.1(6) 50
7.김웅곤 0.997991 235.335 8.1(7) 50
3.의미 🌟
대회 참여 인원은 총 960명으로 국내에서 가장 많은 사람이 참가한 데이터 경진대회로 성황리에 마무리되었습니다. 많은 사람이 참여한 이유로는 1. 기존 데이콘 회원의 높은 참가율 2. 높은 상금 (총 2,000 만원) 3. KB금융, 한국인터넷진흥원(KISA)의 높은 브랜드 가치인 것으로 판단됩니다.
알고리즘 평가를 위해서 대회 중 새롭게 수집한 11월 ~ 12월 금융 문자 데이터에 대해 예측력과, 예측 시간을 측정했습니다. 많은 우수 코드들은 공통적으로 형태소 분석기로는 Mecab을 사용했으며 머신러닝 모델로는 LightGBM을 사용했습니다. 대회 특성상 정확도와 함께 예측 속도가 중요하기 때문에 정확하면서도 처리시간이 짧은 Mecab이 선택되었고, 길이가 짧은 금융문자 특성상 신경망 기반의 BERT, LSTM과 같이 무거운 모델 보다는 비교적 가벼운 LightGBM이 선호된 것으로 보입니다.
대회 결과 새로운 데이터 세트에 대해 AUC 0.999405, 정확도 95%의 높은 예측력을 보이면서도 속도 또한 개당 2ms로 빠르게 처리하는 알고리즘을 발굴할 수 있었습니다. 이로써 고객에게 실시간으로 스미싱 여부를 제공하는 것이 가능할 것으로 기대됩니다.
➡️
Sound Classification with Machine Learning: A demo of a Neural Network trained to classify animal sounds, rain drops, baby crying and man-made noises like helicopter flying.
https://youtu.be/yhr4yw8N9ig
http://bit.ly/2lUbFoQ
안녕하세요!
deepfake 대회가 진행되고 있지만,
쉽지 않은 대회인 것 같습니다.
저어어엉~말 간단하게 프로세스를 정리해봤습니다.
조금이나마 도움되시길 바라며!
대회하며 공부해봅시다 :)
# 1. Face detection 한다.
- 이 커널로 스터디 [https://www.kaggle.com/timesler/comparison-of-face-detection-packages](https://www.kaggle.com/timesler/comparison-of-face-detection-packages)
- facenet-pytorch
- mtcnn
- dlib
# 2. 추출된 이미지로, real, fake face classifier 만든다.
- [https://www.kaggle.com/robikscube/faceforensics-baseline-dlib-no-internet](https://www.kaggle.com/robikscube/faceforensics-baseline-dlib-no-internet)
- [https://www.kaggle.com/unkownhihi/starter-kernel-with-cnn-model-ll-lb-0-69235](https://www.kaggle.com/unkownhihi/starter-kernel-with-cnn-model-ll-lb-0-69235)
- [https://www.kaggle.com/humananalog/inference-demo](https://www.kaggle.com/humananalog/inference-demo)
안녕하세요 SLAM 공부 김기섭입니다.
최근 SLAM 이 간단한 환경에서는 많이 풀렸다고 생각되서인지,
극한 환경 (안개, 한밤중 등) 에서도 SLAM이 잘되게 하자 라는 쪽으로 연구가 많이 이뤄지고 있는 것 같습니다. (예시: https://youtu.be/hDZy47MaPDQ?t=109)
#
한편, 극한 환경을 위해서는 기존에 많이 쓰던 센서 (camera, lidar) 로 알고리즘을 잘 개발하는 것뿐 아니라
이러한 환경 자체에 강인한 센서를 사용하는 것도 문제를 쉽게 해결하는 방법일 수 있는데요
관련 데이터셋을 소개합니다.
#
ICRA 2019 학회의 SLAM dataset workshop 에서 BEST POSTER PRESENTATION AWARD 를 수상한 논문인데요, ViViD : Vision for Visibility Dataset
Vision for Visibility 라는 이름의 약자로 Beyond-visibility vision sensors 로 thermal camera 와 event camera 를 동시에 포함하고 있는게 특징같습니다.
아웃도어와 인도어에서 다양한 시퀀스들을 포함하고 있네요
#
논문 https://drive.google.com/file/d/1DqiMbdbOKX29Qgk-V5B6JVFPkWKLjSqN/view
발표자료 https://drive.google.com/file/d/1HMCVOeCpdI84IBWQ5dw08amVP8TppSZ_/view
데이터는 여기서 받을수있습니다 https://sites.google.com/view/dgbicra2019-vivid/
감사합니다! (급마무리)
[Audio/Datasets] Open Speech Corpora
음성합성, 음성인식 등 음성처리에 필요한 데이터셋 정리본 입니다.
Corpus이름, 언어, 시간, 화자수, 링크, 라이센스 등이 정리되어 있습니다.
https://github.com/JRMeyer/open-speech-corpora
#Audio #Voice #Dataset #Corpora
[https://github.com/catSirup/naver_kin_crawling](https://github.com/catSirup/naver_kin_crawling)
안녕하세요 NLP를 공부하고 있는 김태형입니다.
텍스트 마이닝을 하기 위해 네이버 지식인에서 특정 키워드가 포함된 데이터를 크롤링하는 프로젝트를 간단하게 진행해봤습니다.
첫 크롤링 프로젝트라 엉성합니다. 피드백은 언제나 달게 받겠습니다!
귀찮니스트를 위해 우분투에서 OpenCV를 자동 빌드 및 설치하는 스크립트를 만들었습니다. 매번 제가 빌드하기 귀찮아서요.
https://booiljung.github.io/technical_articles/computer_vision/build_opencv_on_ubuntu_cli_with_script_ko.html
| OpenCV 4.2.0이 정식 릴리즈되었습니다. 이번 릴리즈에서 드디어 CUDA를 이용하여 DNN 모듈을 실행할 수 있게 되었네요. 대박입니다! (0) | 2019.12.23 |
|---|---|
| “The program can't start because opencv_world300.dll is missing from your computer” error in C++ (0) | 2016.10.19 |
| Print out the values of a (Mat) matrix in OpenCV C++ (0) | 2016.09.28 |
| Print out the values of a matrix in OpenCV C++ (0) | 2016.09.28 |
| OpenCV 3.1 개발환경 셋팅 (0) | 2016.09.19 |
안녕하세요, 이정윤입니다.
오늘은 지난 시간에 이어 [#Kaggle](https://www.facebook.com/hashtag/kaggle?source=feed_text&epa=HASHTAG) 대회 시작하기 #2 편입니다.
이번 편에서는 Github에 Repo를 셋업하고, Kaggle API로 데이터를 다운 받은 후, Jupyter Notebook 상에서 데이터를 살펴보았습니다.
다음 편에서는 기본 피처를 가지고 모델을 만들어 첫 번째 답안을 제출해보도록 하겠습니다.
- 사실 오늘 이것까지 올리고 싶었는데... 편집하는데 시간이 너무 많이 걸려서 다음 번으로 미뤄야겠습니다. ㅠ.ㅠ
도움이 되셨다면 좋아요/구독/ 부탁 드립니다. 감사합니다. :)
여러분 모두 저와 함께 Kaggle 대회 참석하시면서 즐거운 Data Science 하시기 바랍니다.
모두 즐거운 Data Science, Happy Kaggling 하세요~!
https://youtu.be/1eqliTZ5okY
안녕하세요 캐코 여러분,
이번에는 캐글 컴피티션 마스터가 되는 법이라는 주제로 영상을 준비해 보았습니다.
이미 잘하시고 계신 분들이 많으시지만 혹 도움이 되는 분들이 계시길 바랍니다.
https://youtu.be/G2ZeYWRruKc
유한님의 공지처럼 올해 100의 한국 마스터 분들을 기원합니다.
Happy Kaggling~!
매우 좋은 AI 학습사이트!
무료에 1:1 튜터 형식으로 재미도 있고!
비록 영어 동영상이지만, 영어 자막 제공하고 있어서
이해하기도 쉽고...
Advisor가 쟁쟁한데 특히 Yoshua Bengio 교수님이!
ㅎㄷㄷ
https://www.facebook.com/groups/KaggleKoreaOpenGroup/permalink/588324355233001/
https://korbit.ai/machinelearning
SLAM이 처음이신분들은
SLAM의 수학적 원리 이해도 좋지만
다양한 데이터셋을 받고, 열어보고, 만져보는거부터 출발하셔도
좋을거같아요
그런의미에서 SLAM쪽에서 가장 유명한 KITTI dataset
을 열어보는 노트북이 있어 공유합니다.
Hyper Parameter Tuning을 자동으로 해주는 Keras Tuner에 대한 tutorial을 공유해드립니다
Keras Tuner를 사용하시면 Bayesian Optimization, Hyperband, Random Search algorithm을 이용하여 내가 만든 model의 hyper parameter를 자동으로 tuning할 수 있습니다
사용법도 매우 간단하고 TensorFlow쓰시는 분들은 tf.data와 호환가능합니다
또 ResNet과 Xception이 built-in model로 포함되어 있어서 이 model을 쓰실 분들은 따로 model을 만드시지 않아도 됩니다
multi-GPU에서의 distributed tuning(data parallel과 trial parallel 모두 가능)도 지원합니다
심지어 Scikit-learn으로 작성한 model도 tuning 가능합니다
빨리 저부터 써봐야겠네요!!
자세한 내용은 아래 blog를 참조해주세요!
https://blog.tensorflow.org/2020/01/hyperparameter-tuning-with-keras-tuner.html
Latest from Microsoft researchers: ImageBERT (for image-text joint embedding)
https://www.profillic.com/paper/arxiv:2001.07966
(They achieve new state-of-the-art results on both MSCOCO and Flickr30k datasets.)
안녕하세요 SLAM공부 김기섭입니다.
논문이 너무 많은 시대입니다.
최신 논문 중 뭘 읽어야 할지 따라가기가 늘 힘들었는데
아래 슬라이드들에 논문 리스트업+요약 이 간단하게 잘 되어있네요! (정말 대단하신분!!)
또 모두 2019년도 업로드 자료라 최신 반영이 잘 되어있는거같습니다 (저도 아직 몇개 안봤지만.,,,)
공유합니다
#
# 2019 - SLAM related
Dynamic Mapping in SLAM
- https://www.slideshare.net/yuhuang/dynamic-mapping-in-slam
Semantic SLAM I
- https://www.slideshare.net/yuhuang/semantic-slam
Semantic SLAM II
- https://www.slideshare.net/yuhuang/semantic-slam-ii
Stereo Matching by Deep Learning
- https://www.slideshare.net/yuhuang/stereo-matching-by-deep-learning
Depth Fusion from RGB and Depth Sensors II
- https://www.slideshare.net/yuhuang/depth-fusion-from-rgb-and-depth-sensors-ii
Depth Fusion from RGB and Depth Sensors III
- https://www.slideshare.net/yuhuang/depth-fusion-from-rgb-and-depth-sensors-iii
Depth Fusion from RGB and Depth Sensors IV
- https://www.slideshare.net/yuhuang/depth-fusion-from-rgb-and-depth-sensors-iv
#
# 2019 - Autonomous Driving related
Lidar for Autonomous Driving II (via Deep Learning)
- https://www.slideshare.net/yuhuang/lidar-for-autonomous-driving-ii-via-deep-learning
LiDAR-based Autonomous Driving III (by Deep Learning)
- https://www.slideshare.net/yuhuang/lidarbased-autonomous-driving-iii-by-deep-learning
fusion of Camera and lidar for autonomous driving I
- https://www.slideshare.net/yuhuang/fusion-of-camera-and-lidar-for-autonomous-driving-i
fusion of Camera and lidar for autonomous driving II
- https://www.slideshare.net/yuhuang/fusion-of-camera-and-lidar-for-autonomous-driving-ii-181748995
3-d interpretation from stereo images for autonomous driving
- https://www.slideshare.net/yuhuang/3d-interpretation-from-stereo-images-for-autonomous-driving
3-d interpretation from single 2-d image for autonomous driving II
- 3-d interpretation from stereo images for autonomous driving II
새해덕담 - 인공지능 훈련을 통해 배우는 인생
(누구든 사는 것의 uncertainty와 부족한 자원에 자주 실망한다. 인공지능 훈련을 하면서 이러한 것이 오히려 성공의 요소로 중요하다는 것을 배운다)
서울대 전기정보공학부의 성원용교수입니다. 나는 올해 8월 은퇴를 앞두었습니다만, 지난 몇년간 인공지능 분야를 재미있게 연구했습니다. 주로 효율적인 하드웨어 구현을 위한 단어길이 최적화, 그리고 응용으로는 음성인식입니다.
오늘은 설이기 때문에 젊은 후학들에게 인공지능을 통해 배우는 인생이 무엇인가하는 것을 생각해 보았습니다. 우리가 인공신경망의 훈련에 SGD(Stochastic Gradient Descent)를 많이 쓰는데, 이 훈련이 잘 되려면 네트워크를 loss surface의 소위 flat minima (평평한 최소)로 보내야 합니다. Flat minima는 웨이트의 값이나 data의 분포에 변화가 생겨도 loss가 크게 변하지 않기 때문에 소위 generalization (일반화) 능력과 관련해서 중요한 개념입니다. 나의 경우는 flat minima를 인공신경망 웨이트의 단어길이를 줄이는 목적으로 중요하게 생각합니다.
최근의 인공신경망은 파라미터의 갯수가 많기 때문에 훈련 데이터를 몇 에포크 돌리면 금방 다 외워버립니다. 즉, 트레이닝 로스가 매우 작아집니다. 그런데 빨리 훈련이 되면 flat minima에 가지 못하는 경향이 있습니다. 이를 오버피팅(over-fitting)되었다 하기도 합니다. 그 까닭은 인공신경망이 만드는 loss surface는 non-convex이기 때문입니다. Non-convex는 최소값 지점(minima)이 수없이 많지요. 따라서 적당하지 않은 minima에 빨리 정착해서 훈련 끝났음하면 안 됩니다. 이렇게 적당하지 않은 minima를 sharp minima라 하는데 training loss는 이 점에서 작을지라도 전체적으로 data의 통계적 변화에 취약합니다. 즉 generalization 능력이 떨어집니다.
이렇게 sharp minima를 피하기 위한 대표적인 훈련법이 SGD (stochastic gradient descent)입니다. GD(gradient descent)와 비교할 때 SGD는 크지 않은 mini-batch size (보통 32~512정도)로 loss를 얻어서 웨이트를 업데이트하는데 이 때 그 미니배치에 어떤 데이터가 들어오냐에 따라서 일종의 noise가 생기고 이 것이 SGD를 sharp minima에 빠지지 않게 하는 역할을 한다고 합니다. 또 다른 방법이 L2 weight regularization입니다. 이 경우는 weight 값의 크기에 제약을 두는 것입니다. 이 밖에도 weight 나 gradient에 noise를 injection하는 방법이 있습니다. 그리고 dropout 도 regularization 입니다.
이러한 regularization방법은 크게 두가지 특징을 가지고 있습니다. 첫째로 uncertainty입니다. GD의 경우는 batch size가 엄청커서 평가의 nosie가 적습니다. 그렇지만 SGD는 batch size가 제한되어 있기 때문에 noise가 큽니다. 어떤 때는 잘못된 방향으로 update합니다. 그렇지만 이 것이 sharp minima에서 빠져나오는데 도움을 줍니다. 두번째는 제약(constraint)입니다. L2 norm을 작게한다든가 weight의 값에 noise를 넣습니다. Regualarization을 가하면 training accuracy 100%를 찍기가 엄청 어렵습니다. Training loss가 천천히 줍니다. 말하자면 더 어려운 시험문제, 더 나쁜 상황으로 훈련을 시키는 것에 비유할 수 있습니다.
이 DNN훈련이 삶에 주는 지혜가 있습니다. 성공하기 위해서는 flat minima를 찾아야 합니다. 직업에 있어서 flat minima는 유연성과 확장성이 있어서 발전가능성이 크고 위기에도 견딜 수 있는 것입니다. 그래서 경영학 구루들은 사람들에게 '자신의 편안한 영역(일종의 sharp minima)에 안주하지 말라' 조언합니다. 그리고 flat minima를 찾기 위해서는 uncertainty를 감수해야 합니다. 입학시험부터 입사시험에 이르기까지 합격 불합격이 꼭 실력대로 되는 것은 아닙니다. 그래도 꼭 실력대로 안되는 세상이 모든 것이 성적대로 줄세워서 되는 세상보다는 낫습니다. 단지 세상은 이러한 uncertainty를 가지고 움직인다는 것을 이해해야 합니다. 두번째는 적절한 regularization이 필요합니다. 돈걱정등 모든 걱정이 없으면 좋을 것 같지만, 많은 재벌의 자식들이 마약문제로 언론에 많이 나옵니다. 부모의 후광으로 빨리 출세가 좋은 것이 아닙니다. 오버피팅되는 네트워크를 만드는 것입니다. 적절한 regularization은 오히려 성공에 도움을 줍니다.
누구든 사는 것의 uncertainty와 부족한 자원에 자주 실망합니다. 그렇지만 인공지능 훈련을 하면서 이러한 것이 또한 성공의 요소로 중요함을 덕담으로 남깁니다. 올 한해에도 많은 성과가 있기를 바랍니다.
👨🏫 안녕하세요 데이콘에서 코드 공유를 오픈 했습니다.
🎉우승자 코드에서 배움과 🤵자신의 코드로 피드백을 받을 수도 있습니다.
➡️ [http://bit.ly/3av37JQ](http://bit.ly/3av37JQ)
#SIA #ADD #미래도전 #dacon #datavisualization #DataScience #DataAnalyst #DataEngineer #DataScentist #DataMining #MachineLearning #deeplearning #데이콘 #경진대회 #데이터분석 #KB금융 #인공지능 #머신러닝 #딥러닝 #자연어처리 #파이썬 #코드 #공유
Latest from Stanford, Adobe and IIT researchers: State of the art in Virtual Try on!
https://www.profillic.com/paper/arxiv:2001.06265
(An efficient framework for this is composed of 2 stages: (1) warping (transforming) the try-on cloth to align with the pose and shape of the target model, and (2) a texture transfer)
#OpenSyllabus
세계 80개국에서 영어로 작성된 7백만 여개의 Syllabus를 수집해 각 전공별로 어떠한 전공 서적이 수업에 가장 많이 참고되었는지를 기록으로 제공해주는 Open Syllabus 사이트를 소개해드립니다.
요즘에는 학부 때와 다른 전공으로 진로를 정하고자 하시는 분들이 많이 계시지만, 비전공자라는 환경적 제약상 어떠한 서적으로 해당 전공을 심도있게 공부할 수 있는지에 대한 고민을 많이 하게 되는 것 같습니다. 리소스는 넘쳐나지만 그 반대 급부로 선택의 고민이 많아지고 있는 것이죠.
물론 모든 서적을 비교해보며 자신에게 가장 맞는 서적을 기반으로 학습하는 것이 가장 이상적일 수 있겠지만, 현실적인 타협안은 가장 많은 전공자들이 필독하는 바이블과 같은 서적을 시작점으로 학습하는 것일 것입니다. 그리고 Open Syllabus가 해당 선택을 도와줄 수 있는 좋은 지침서가 될 수 있을 것 같습니다.
기계학습과 자연어 처리를 공부하는 저의 경우, Open Syllabus에서 수학, 전산학 그리고 추가적 공부를 한다면 언어학에서 자주 사용되는 교재를 기반으로 학습을 시작해볼 수 있겠네요 !
자연어 처리와 직접적인 관련은 없는 게시물일 수 있지만 여러분의 학습 교재 선택에 있어 도움이 될 수 있는 자료인 것 같아 꼭 공유를 드리고 싶었습니다 😆
P.S 전산학의 1위 레퍼런스 교재가 피터 노빅의 인공지능 서적인 점이 재밌네요 ! 그 외 공룡책(OS), 탑다운 네트워크 서적 등도 높은 순위에 랭크되어 있습니다.
Open Syllabus: https://opensyllabus.org/results-list/fields?size=100
SLAM 백엔드에서 최적화에 쓰이는 factor graph에 대한 short course가 최근에 열렸네요 ㅎ
유튜브 영상 강의와 예제 코드도 제공합니다 ㅎ
영상: https://www.youtube.com/playlist?list=PLOJ3GF0x2_eWtGXfZ5Ne1Jul5L-6Q76Sz
코드: https://github.com/jlblancoc/2020-ual-factor-graphs-course
안녕하세요 박찬준입니다.
최근 AI HUB에서 ([http://www.aihub.or.kr/](http://www.aihub.or.kr/))에서 한-영 병렬 말뭉치를 공개했습니다.
한국어-영어 160만 문장의 번역 말뭉치를 공개했으며 자세한 구축사항은 아래 링크에서 확인하실 수 있습니다.
[http://www.aihub.or.kr/aidata/87](http://www.aihub.or.kr/aidata/87)
솔트룩스, 애버트란, 플리토에서 함께 작업한 것으로 알고 있으며 해당 데이터를 활용하여 성능이 얼마나 나오는지 실험을 진행해보았습니다. 눈으로 보았을 때 아직 조금 다듬어야 할 부분들(문장 정렬,표현 등)이 보였으나 기존의 공개된 데이터들 (ex. Opensubtitles)에 비해 상당히 고품질의 데이터로 판단됩니다.
실험을 위한 테스트셋으로는 IWSLT에서 공개한 Test2016, Test2017을 사용하였습니다.
실험결과 한-영 기계번역에서 16.38(Test 16기준) 의 BLEU 점수가 나왔으며 Opensubtitles 데이터까지 함께 학습시켜보니 17.34 (Test 16기준)까지 나오는 것을 볼 수 있었네요. 기존에 서강대학교[저-자원 언어의 번역 향상을 위한 다중 언어 기계번역], 강원대학교[MASS를 이용한 영어-한국어 신경망 기계번역]에서 동일한 테스트셋으로 실험한 논문보다 성능이 높게 나옴을 알 수 있었습니다.(물론 학습데이터가 달라서 성능 비교는 의미가 없습니다...)
역시 데이터의 품질이 중요함을 다시 한번 알 수 있었네요…
해당 데이터로 많은 분들이 다양한 서비스를 만들어 보시면 좋을 거 같습니다.
추가적으로 해당 모델을 Demo형태로도 만들어보았으니 직접 사용해보실 분들은 사용해보시면 좋을 듯 합니다 !
[http://nlplab.iptime.org:32296/](http://nlplab.iptime.org:32296/)
최근에 데이터를 좀더 쉽게 Crawling 할 수 있는 방법이 있지 않을까 생각하다가 OpenCV의 Face Detection 과 dlib의 Face Align 코드를 합쳐보았습니다.
얼굴관련 연구하시는분들에게는 나름 유용하게 쓰일 수 있지 않을까 생각하여, GUI까지 구현하여 깃헙에 올려놨는데, 혹여나 필요하신분 계실까 싶어 링크 올려드립니다.
Usage 항목과 Installation 항목 참고하여 주시기 바랍니다.
[https://github.com/Jaesung-Jun/Cut-And-Save-Faces](https://github.com/Jaesung-Jun/Cut-And-Save-Faces)
| State of the art in 3D dense face alignment! For project and code/API/expert r (0) | 2020.09.23 |
|---|
#nlp_news #tokenizers #ner #felix_hill #ai_dungeon
올해의 첫 NLP 뉴스입니다! 최근 자연어 처리 관련 재밌는 소식들이 많아 어떤 소식을 전해드리는게 좋을까 고민을 하다가, 아래 5개 소식을 선정해 소개해드리고자 합니다. 본 글을 읽는 모든 분들께 유익한 글이 되었으면 좋겠습니다 🤗
ㅡㅡㅡㅡㅡㅡㅡㅡㅡ
1. Hugging Face's Tokenizers
자연어 처리 전문 스타트업 Hugging Face 사에서 토크나이저 라이브러리를 오픈소스로 공개하였습니다. 다들 아시다시피 Deep Learning을 연구 및 적용하는 연구자와 개발자들이 늘어남에 따라 많은 모델링 관련 오픈소스들이 공개되어 왔습니다. 그리고 Hugging Face의 transformers, Facebook의 fairseq, Google의 tensor2tensor 등의 오픈소스가 공개됨에 따라 모델 구현은 이전보다 많이 수월해진 면이 있습니다.
그러나 자연어 데이터 전처리에 필수적으로 포함되는 토큰화 작업에서 생기는 성능 이슈로 인해 여전히 전처리 과정에서의 병목은 존재합니다. 이처럼 전처리 과정에서 발생하는 병목 현상을 해소하고, 다른 오픈소스들과 같이 연구자 및 개발자들에게 더 나은 편의를 제공하기 위해 Hugging Face 사가 토크나이저 오픈소스를 새로이 공개하였습니다!
Hugging Face 사의 'tokenizers'는 [그림 1]과 같이 4개의 컴포넌트가 하나의 파이프 라인으로 구성되며, 각 컴포넌트는 다음 역할을 담당합니다.
- Normalizer: 입력된 텍스트 데이터에 정규화를 수행
- PreTokenizer: 공백을 이용한 간단한 문장 Split을 수행
- Model: BPE, WordPiece, SentencePiece 등의 Tokenization 알고리즘이 적용
- PostProcessing: (Optional) Model의 결과 값에 후작업을 수행 (e.g. Language Modeling을 훈련하기 위해 Special tokens를 더해줄 수 있음)
tokenizers 라이브러리는 Rust로 구현되어 단일 CPU 기준 GB 사이즈의 텍스트를 처리하는데 약 20초 미만이 소요되었다고 하며, 현재 Node.js와 Python 바인딩을 제공해주고 있습니다! 앞으로 자연어 처리 관련 연구 및 개발에 있어 많은 도움을 받을 라이브러리가 될 것 같습니다. 역시 갓 Hugging Face !
2. NER Papers repository
어제 소개해드린 CMU CS 11-747 강좌에 Graham Neubig과 함께 Co-instructor로 등록되어 있는 Pengfei Liu가 2013년부터 2020년까지 8년 간 ACL, EMNLP, NAACL, Coling, ICLR, AAAI, IJCAI 등 7개의 최상위 학회에 제출된 NER 논문들을 큐레이팅한 'Named-Entity-Recognition-NER-Papers' 레포지토리를 공개하였습니다.
논문 리스트와 더불어 NER 연구에 주로 사용되는 벤치마크 데이터셋 정보도 함께 제공해주고 있으며, 리스트 뷰어의 경우 검색, 인용 수 기준 정렬 등 부가적인 편의 기능까지 제공합니다. 특히 각 논문에 카테고리 태그를 모두 달아둠으로써 카테고리 별로 논문을 선별해 볼 수 있는 기능이 많은 연구자들에게 요긴하게 사용될 것 같아 소개를 드립니다 🙂
3. Dair's news letter
Medium에서 자연어 처리와 관련한 좋은 아티클를 많이 작성해주는 dair.ai에서 뉴스 레터를 시작하였습니다. 1~2주 간격으로 자연어 처리, 머신러닝과 관련된 최신 소식들을 전해준다고 합니다. 관심 있으신 분들이 생각나실 때 마다 여러 소식들을 캐치업하기 좋을 자료가 될 것 같습니다.
그리고 이번 첫 편에서는 Hugging Face의 tokenizers, TensorFlow 2.1에 새로이 추가된 TextVectorization 레이어, dair.ai가 Medium을 통해 발행했던 NLP Review in 2019 등을 다루었습니다!
4. Felix Hill's Non-Compositional
언어학, 수학 등에는 Compositionality의 원리가 존재한다고 합니다. (정확하지는 않지만 제가 이해한 바에 의하면) 이는 한 Expression의 의미는 해당 Expressoin을 구성하는 성분들의 의미와 그 성분들을 묶어주는 규칙에 의해 결정된다는 원리입니다. 언어학자들은 자연어가 대개 Compositional 하지만, Idiom과 같이 해당 원리가 적용되지 않는 예외도 존재한다고 이야기합니다. 해당 원리에 부합하지 않는 더 간단한 예로는 "I am home"과 같은 문장을 들 수 있겠네요.
DeepMind에서 인공지능을 연구하는 Felix Hill은 언어학자들과 다른 의견을 가지고 있는 것 같습니다. Felix는 자연어가 기본적으로 Non-Compositional 하다고 주장합니다. 아래는 Felix의 블로그 소개 글입니다.
"자연어는 수학이나 논리학 등의 형식 언어와 다르기에 흥미롭다. 사람들은 때때로 자연어가 Compositional하다고 생각하지만, 자연어는 Compositional한 언어가 아니다. 만약 당신이 자연어가 Compositional하다 생각한 바로 그 사람이라면, 내 블로그 Non-Compositional을 한 번 확인해봐라"
제게는 다소 생소한 언어학과 관련된 이야기이지만, Felix Hill의 "Natural Language is Non-Compositional" 주장에 관심이 있으실 분들이 계실 것 같아 소개를 드립니다. 해당 주장에 흥미가 생기신 분들은 아래 링크를 참조해주세요!
P.S Felix Hill은 Yoshua Bengio, 조경현 교수님과 같은 세계적 석학들과 Co-work을 하는 인공지능 관련 권위자이자 인지과학, 전산 언어학을 전공한 학자입니다. 이러한 Felix의 위 주장은 현재 Twitter에서도 꽤나 논쟁이 되고 있으니, 심각하게 받아 들이시기 보다는 다양한 관점의 주장을 접한다 생각하고 참고하시는게 좋을 것 같습니다 🙂
5. AI Dungeon 2
작년 12월 aidungeon.io 사에서 Open AI의 Pre-trained GPT-2 모델을 활용한 텍스트 기반 게임 AI Dungeon 2를 새로이 내놓았는데, 이게 해외에서 반응이 꽤나 좋습니다. 해당 게임은 GPT-2-small을 사용해 구현했던 AI Dungeon 1을 발전시킨 게임으로, 이번에는 OpenAI가 공개한 모델 중 가장 큰 GPT-2-large를 활용해 텍스트를 보다 안정적으로 생성할 수 있는 게임으로 중무장해 돌아왔습니다.
그리고 본 게임을 구현하며 진행했던 GPT-2 관련 여러 실험 + 튜닝 등의 이야기를 담은 메이킹 스토리 아티클이 있는데 해당 글도 상당히 재미있습니다. 먼저 모델 Fine-tuning의 경우, chooseyourstory.com에서 제공하는 모험 시나리오 관련 데이터셋을 활용해 진행했다고 합니다. 그리고 Text generation 모델들이 겪는 고질적인 문제인 '중복 단어의 생성 문제'를 해결하기 위해 Salesforce 팀이 CTRL에서 적용한, 이전에 이미 생성된 단어들의 확률 값을 의도적으로 줄여주는 방식을 본 게임 모델 개발에도 차용했다고 합니다.
또한 컨텍스트를 유지하기 위해 모델이 생성해낸 '상황 텍스트'와 '사용자의 입력'이 함께 다음 입력 값으로 들어가게 되며, 현재 입력 값 뿐만 아니라 최대 10턴 이전의 입력까지 Memory로 함께 가져가며 이전 상황 설정들을 기억하도록 하였습니다 (최적 메모리로는 이전 8턴 까지의 값들을 사용). 모델의 한계로는 상황 생성에 있어 자연스러운 텍스트를 생성해내고 있긴 하나, 대화문 등의 텍스트를 생성할 때 'Who is who?'를 파악하는 면에서 취약점을 보이고 있다고 합니다.
개인적으로 게임을 몇 번 진행해보았는데 꽤나 흥미로운 게임이었으며, Text generation 모델을 이러한 부문에서도 사용할 수 있구나라는 깨달음을 얻을 수 있었습니다. 그리고 메이킹 스토리의 경우, 모델을 적용하며 마주하게 되는 여러 문제들에 대한 대응 방안(apply CTRL tip, Memory network, ...)이 많이 담긴 좋은 글이기에 꼭 읽어보시길 추천드립니다. 시간 되실 때, 게임도 한 번 해보세요! 😆
ㅡㅡㅡㅡㅡㅡㅡㅡㅡ
[References]
Hugging face's tokenizer: https://github.com/huggingface/tokenizers
NER papers: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Dair's NLP newsletter: https://github.com/dair-ai/nlp_newsletter
Felix Hill's Non-Compositional: https://fh295.github.io/noncompositional.html
AI Dungeon 2: https://play.aidungeon.io/
AI Dungeon 2 making story: https://pcc.cs.byu.edu/2019/11/21/ai-dungeon-2-creating-infinitely-generated-text-adventures-with-deep-learning-language-models/
머신러닝 - 16. NGBoost (데이터 파수꾼 Baek Kyun Shin)
앤드류 응 교수가 속해있는 스탠퍼드 ML Group에서 최근 새로운 부스팅 알고리즘을 발표했습니다. 머신러닝의 대가인 앤드류 응 교수의 연구소에서 발표한 것이라 더 신기하고 관심이 갔습니다. 2019년 10월 9일에 발표한 것으로 따끈따끈한 신작입니다. 이름은 NGBoost(Natural Gradient Boost)입니다. Natural Gradient이기 때문에 NGBoost지만 Andrew Ng의 NG를 따서 좀 노린 것 같기도 하네요.. 엔쥐부스트라 읽어야 하지만 많은 혹자들이 앤드류 응 교수의 이름을 따서 응부스트라 읽을 것 같기도 합니다.
어쨌든 다시 본론으로 넘어가면, 지금까지 부스팅 알고리즘은 XGBoost와 LightGBM이 주름잡았습니다. 캐글의 많은 Top Ranker들이 XGBoost와 LightGBM으로 좋은 성적을 내고 있습니다. NGBoost도 그와 비슷한 명성을 갖게 될지는 차차 지켜봐야겠죠.
* 출처 : https://bkshin.tistory.com/m/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-16-NGBoost
| Having an unbalanced dataset is not an uncommon problem in real world. Intereste (0) | 2020.10.07 |
|---|---|
| [Silhouette coefficient] Clustering metrics better than the elbow-method (0) | 2020.05.13 |
| XGBoost: An Intuitive Explanation Ashutosh Nayak : https://towardsdatascience.c (0) | 2019.12.23 |
| 리그레션 종류 (0) | 2019.11.11 |
| 베이즈 정리(Bayes Theorem)라고 알려진 사후확률 (posterior probability)에 관한 몇가지 수학을 논의할 것입니다 (0) | 2017.10.12 |
State of the art- Photoshop faces with hand sketches!
https://www.profillic.com/paper/arxiv:2001.02890
(The researchers propose Deep Plastic Surgery, a novel sketch-based image editing framework to achieve both robustness on hand-drawn sketch inputs and the controllability on sketch faithfulness)



|
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
